人工智能咨询培训老师叶梓 转载标明出处
以往的研究表明,基于Transformer的LLMs能够在参数中存储和检索事实信息,以完成简单提示,例如“Stevie Wonder的母亲是谁”。此外,当必要信息明确给出时,LLMs表现出了显著的上下文推理能力。然而,当推理所需的信息不是输入的一部分时,LLMs是否能够执行多跳推理,这一点尚不清楚。
Google DeepMind、伦敦大学学院、Google Research 和特拉维夫大学的研究团队提出了一个具体的问题:“当处理如‘Superstition的歌手的母亲是谁’这样的两跳提示时,LLMs是否能够确定‘Superstition的歌手’指的是Stevie Wonder这一桥梁实体,以及利用他们对Stevie Wonder母亲的知识来完成提示?” 回答这个问题对于理解LLMs是否能够通过它们参数中隐含的知识进行连接和遍历,而不仅仅是在参数中冗余地存储信息至关重要。

图 1: 展示了研究的两个步骤:第一跳是改变输入提示以引用桥接实体(例如Stevie Wonder),并检查这是否增加了模型对该实体的内部召回。第二跳是检查增加这种召回是否使模型输出与它对桥接实体属性的知识(例如Stevie Wonder的母亲)更加一致。为了测试LLMs的多跳推理能力,研究者们设计了一个实验框架,通过改变输入提示来观察LLMs的内部召回(entity recall)和一致性(consistency)的变化。
研究者构建了一个名为TWOHOPFACT的数据集,用于研究多跳推理,数据集基于Wikidata构建,包含45,595个独特的双跳提示,涵盖52种类型的事实组合。每个双跳提示都设计成需要模型通过两次逻辑推理步骤来正确回答,例如确定特定歌曲的歌手是谁,然后再确定这位歌手的母亲是谁。数据集的构建旨在评估和分析LLMs在没有直接给出所有信息的情况下,是否能够利用其内部知识库来完成复杂的推理任务。通过这个数据集,研究人员可以更深入地了解LLMs的推理机制,并探索提高其推理效率和准确性的方法。
多跳推理中的第一跳
在研究LLMs潜在多跳推理能力的过程中,一个关键的度量方法是内部实体召回得分,即ENTREC。这个方法的目的是衡量模型在遇到两跳提示时,能否有效地在内部召回作为桥梁的实体。具体为ENTREC关注的是模型在特定层级上对隐藏表示的处理,特别是将这些表示投影到词汇空间时,对实体名称的第一个词的对数概率的计算。
例如,考虑一个实体Stevie Wonder,如果我们想要衡量模型对该实体的内部召回,我们会计算模型在某个层级上对"Stevie"这个词的对数概率。这个概率反映了模型在处理与Stevie Wonder相关的提示时,能够在多大程度上内部地回忆起这个名字。ENTREC的值越高,表明模型对桥梁实体的内部召回越强,这在多跳推理中是一个重要的能力。
为了测试ENTREC,研究者们设计了一系列实验,通过改变两跳提示中的某些部分来观察模型的内部召回是否会增加。实验中采用了两种替换方法:实体替换和关系替换。在实体替换中,原始提示中的实体(e1)被替换为另一个实体(e'1),这个新实体不会指向桥梁实体(e2)。例如,如果原始提示是关于“Superstition的歌手”,那么在实体替换后,它可能变成“Thriller的歌手”,因为“Thriller”并不指向Stevie Wonder。
关系替换则是改变提示中的关系(r1),以确保新的描述不会指向桥梁实体。例如,如果原始描述是“Superstition的歌手”,在关系替换后,可能变成“Superstition的抄袭者”,因为抄袭者与Stevie Wonder没有直接关联。
结果,研究者们发现了充分的证据表明第一跳推理能力随着模型规模的增加而变得更强。图2展示了在不同层级上,通过实体替换和关系替换增加桥梁实体的内部召回的相对频率。对于LLaMA-2 7B模型,实体替换的结果显示,随着层级深度的增加,第一跳推理的证据变得更加清晰,在第31层达到0.71的峰值。而关系替换则表现出稍微有些噪声的模式,在第20层达到0.63的峰值。

当模型规模从7B增加到13B再到70B时,无论是实体替换还是关系替换,第一跳推理出现的频率都变得更高。具体来说,实体替换的最大相对频率从7B的0.71增加到13B的0.72,再到70B的0.78。对于关系替换,这个数字从7B的0.63增加到13B的0.64,再到70B的0.76。
图3进一步展示了随着模型规模增加的实验结果。在图3a中,实体替换的第一跳推理结果表明,最大相对频率随着模型规模的增加而提高。在图3b中,关系替换的结果也显示了类似的趋势。这些结果表明,更大的模型规模有助于提高LLM在第一跳推理任务中的表现。

此外,研究者们还发现,在52种不同的事实组合类型中,有73%的类型在所有模型规模和替换类型中表现出了较强的第一跳推理证据。例如,“国歌的国家的总统”这一事实组合类型,在所有模型和替换类型中的最大频率分别为0.97/0.92/1.0(实体替换)和0.87/0.87/0.89(关系替换)。这表明某些特定的事实组合类型在不同模型规模上都能稳定地展现出较强的第一跳推理能力。
这些发现为理解LLMs在多跳推理任务中的能力提供了重要的见解,并表明模型规模的增加对于提高第一跳推理能力是有益的。然而,这种提升并不是普遍存在于所有事实组合类型中,不同类型的事实组合在不同层级上展现出的相对频率模式也各不相同,这可能与它们独特的语义结构和复杂性有关。
多跳推理中的第二跳
在深入探究LLMs的多跳推理能力时,研究者们特别关注了模型在完成两跳推理任务时的一致性表现。为此,他们引入了一致性得分(CNSTSCORE),这是一种新颖的度量手段,旨在衡量LLM在回答两跳提示和相应的单跳提示时输出的相似度。这一得分的计算基于两个输出概率分布之间的交叉熵,通过求这两个分布交叉熵的平均值来实现。交叉熵是一种衡量概率分布差异的方法,其值越低表示两个分布越相似。因此,如果LLM能够在处理两跳提示时有效地利用第一步推理的结果,那么它在回答两跳和单跳提示时的输出分布应该是接近的,这样的一致性将表现为较高的CNSTSCORE。
在实验设计上,研究者们采取了一种干预的方法来测试LLM的第二跳推理能力。他们不是简单地观察模型的自然输出,而是通过改变模型内部的状态来评估其推理过程。研究者们调整了在计算ENTREC时使用的隐藏表示(xl),目的是增强模型对桥梁实体的召回。这种调整是通过梯度上升的方法实现的,即在模型的隐藏层表示中增加与桥梁实体相关的信息,以此来促进模型对这一实体的记忆和利用。
通过这种方法,研究者们可以观察到当模型对桥梁实体的内部召回增强时,是否会导致CNSTSCORE的提高。如果CNSTSCORE随着ENTREC的增加而提高,这将表明模型在两跳推理中确实利用了第一步推理的结果,并且在回答两跳提示时能够更加一致地输出与单跳提示相对应的答案。这种一致性不仅是对模型内部逻辑一致性的验证,也是对其多跳推理能力的重要证据。
结果分析中,研究者们提供了关于第二跳推理的证据,指出这种推理能力并没有随着模型规模的增加而变得更强。通过图4的展示,我们可以看到在LLaMA-2 7B模型中,中间层和后层的相对频率显著高于随机概率0.5,特别是在第30层时达到了0.64的峰值。这一结果在统计上是显著的,表明在这些层级上,增强对桥梁实体的召回能够提高模型的一致性得分。

图4中的柱状图通过颜色编码来表示相对频率与随机概率的对比,其中蓝色表示相对频率大于或等于0.5,而红色则表示相对频率低于0.5。值得注意的是,在最后一层,研究者们手动将相对频率设置为0.5,因为在这一层次上,干预对一致性没有影响。
当模型从7B扩展到13B和70B时,第二跳推理的最大相对频率保持相对稳定,分别为0.64(7B)、0.65(13B)和0.61(70B)。这与第一跳推理的发现不同,第一跳推理的能力是随着模型规模的增加而提高的。这种稳定性表明,尽管模型的规模在增加,但第二跳推理的能力并没有得到相应的增强。
研究者们还观察到,在52种不同的事实组合类型中,大约19%的类型在所有模型规模上都展现出了较强的第二跳推理证据。例如,“创始人的本科母校”和“国歌的国家的总统”这两个事实组合类型,在所有模型规模上都显示出了较强的第二跳推理证据,其最大相对频率分别为0.86/0.81/0.82和0.84/0.89/0.82。
这些发现与Ofir Press等人在2023年的观察结果一致,即单跳问题回答的性能提升速度快于多跳性能,因此随着模型规模的增加,组合性差距(即模型能够正确回答所有子问题但不能生成总体解决方案的比例)并没有减少。这表明,尽管模型规模的增加可能带来了一些好处,但在多跳推理任务中,可能还需要考虑其他因素,如模型架构或训练方法的改进,以进一步提升LLMs的推理能力。
潜在的多跳推理
研究者们将之前的发现结合起来,以评估LLMs在处理两跳提示时进行潜在多跳推理的能力。他们将两跳推理的成功视为两个研究问题(RQ1和RQ2)的成功的组合。RQ1的成功意味着在输入提示中增加对桥梁实体的描述性提及能够增加LLM的内部实体召回。RQ2的成功则意味着增加的内部召回能够提高LLM回答两跳提示与单跳提示的一致性。
研究者们通过分析不同模型大小(7B、13B、70B)的LLaMA-2模型,来观察模型在处理两跳提示时的多跳推理表现。他们记录了四种可能的结果:SS(RQ1和RQ2都成功)、FS(RQ1失败,RQ2成功)、SF(RQ1成功,RQ2失败)和FF(RQ1和RQ2都失败)。结果以相对频率的形式展现,其中绿色表示多跳推理成功(SS)的情况。
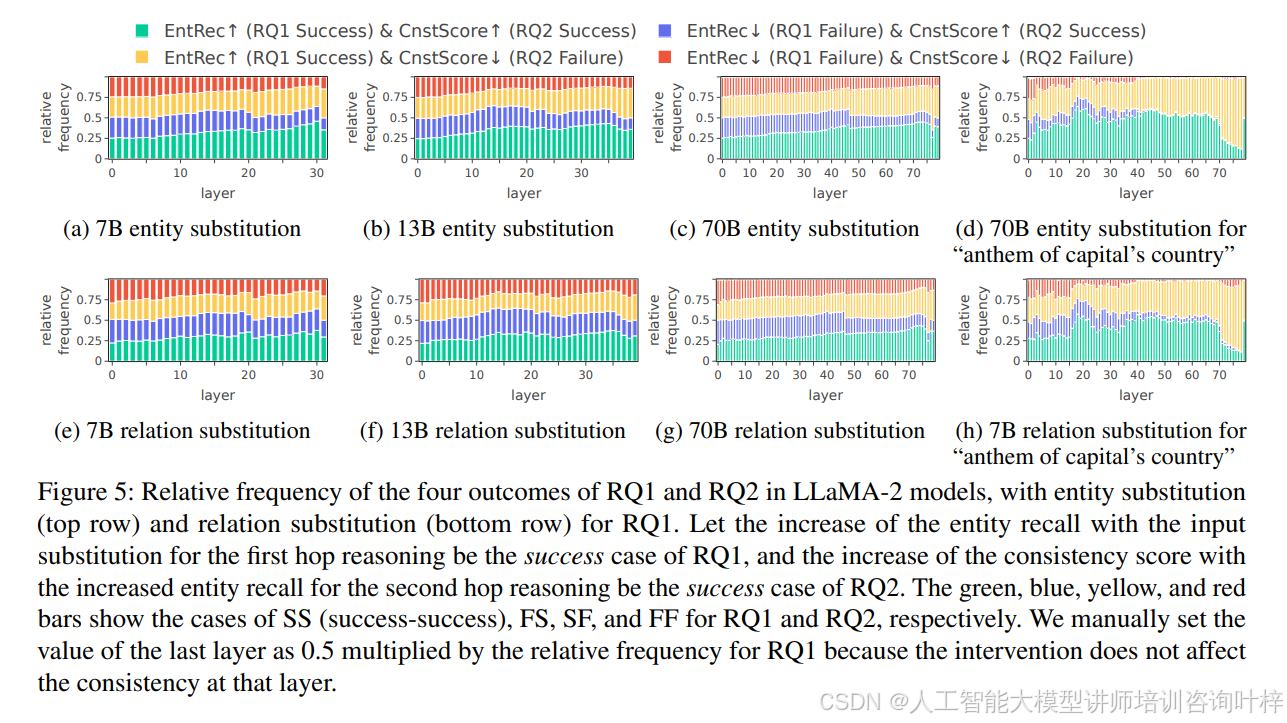
模型表现:
LLaMA-2 7B:在实体替换和关系替换的实验中,7B模型表现出了高于随机概率的多跳推理能力,尤其是在实体替换中,第30层的相对频率达到了0.46。
LLaMA-2 13B和70B:随着模型大小的增加,研究者们观察到关系替换的多跳推理能力有所提升。例如,在70B模型中,关系替换的最大相对频率从7B的0.38增加到0.43,表明更大的模型可能有助于通过关系变化促进多跳推理。
研究者们还分析了不同事实组合类型对多跳推理能力的影响。他们发现,在52种事实组合类型中,有23%的类型在超过80%的情况下表现出了强烈的潜在多跳推理证据。例如,“首都的国家国歌”这一类型在所有模型和替换类型中都表现出了较高的多跳推理能力。
尽管在某些情况下LLMs表现出了潜在的多跳推理能力,但这种能力在不同类型的事实组合中表现出高度的上下文依赖性。另外虽然模型大小的增加对于第一跳推理有积极的影响,但对于第二跳推理并没有观察到同样的趋势。这可能表明,当前的模型架构和预训练方法在促进LLMs进行深层次的多跳推理方面存在局限性。
这项研究为理解LLMs的潜在多跳推理能力提供了新的视角,并为未来的研究指出了潜在的挑战和机遇。研究结果表明,尽管LLMs在某些情况下能够表现出多跳推理能力,但这种能力的发展和应用可能需要对现有的模型架构、预训练数据和损失函数进行更深入的研究和改进。
论文链接:https://arxiv.org/abs/2402.16837





