这是我的第334篇原创文章。
一、引言
对于从事数据相关工作的小伙伴,面试的时候经常会被问到如何进行缺失值/异常值的处理,本文来梳理一下填补数值型缺失值的7种方法。
二、实现过程
准备数据
python">df = pd.read_csv('data.csv')
df.drop("id",axis=1,inplace=True)
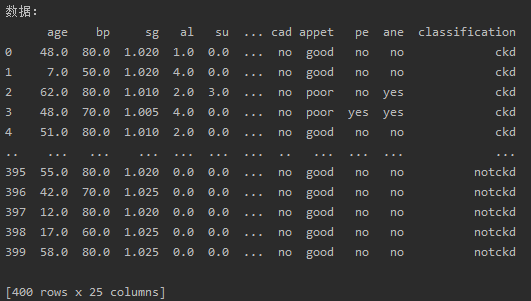
print('数据:', df, sep='\n')df:
查看缺失值情况
整体确实情况:
python">print('数据缺失值情况:', df.isnull().sum(), sep='\n')数值型数据缺失情况:
python">cat_cols = [col for col in df.columns if df[col].dtype == "object"] # 类别型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"] # 数值型变量名
print(cat_cols)
print(num_cols)
print('数值型数据缺失情况:', df[num_cols].isnull().sum(), sep='\n')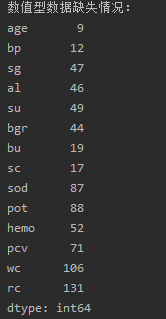
2.1 均值填充
python">df[num_cols] = df[num_cols].fillna(df[num_cols].mean())2.2 中位数填充
python">df[num_cols] = df[num_cols].fillna(df[num_cols].median())2.3 众数填充
python">df[num_cols] = df[num_cols].fillna(df[num_cols].mode().iloc[0])2.4 前后数据填充
python">df[num_cols] = df[num_cols].fillna(method='bfill')python">df[num_cols] = df[num_cols].fillna(method='bfill')2.5 自定义填充
略
2.6 interpolate()插值方法填充
python">df[num_cols] = df[num_cols].interpolate()2.7 机器学习预测填充
略
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。





