爬取点笑话图片没事的时候躲在被子里看看吧
做实验的等待的时候,有点无聊,就想起来原来自己闲着没事,自己写了个爬虫,爬取了一些搞笑图片,没事看看娱乐下。
相信大家平时都有无聊的时候,那么问题来了,无聊的时候该干些什么呢,看点搞笑图片吧,让我们开心的笑起来,面对疾风吧!(ha sa ki,tuo li a 尅 tuo 我去,又尼玛发神经了,大家请原谅我,我可能会不定期的抽风下 ),言归正传,其实简单的爬虫还是很简单的,但是爬取些简单的数据的时候,我觉得还是挺有用的,例如说,你需要租房,此时,你需要上网去找房,但是你怕被坑啊!怎么办,那就是在网上收集别人的评论和建议,这时候,爬虫可以很有效的爬取到大量海量的数据供你参考。我最近还学会了用爬虫爬去点视频,可以观看点VIP看的电影,但是太麻烦了,这里告诉大家一个神器—-VIP解析,只需要复制要看内容的链接放上去,即可观看,很是方便。又跑题了,这里我就分享下我用爬虫爬取的搞笑图片吧。
程序运行时:

这里稍微介绍下这里用到了三个库:request、re、os,那么这三个库分别在我这个程序里干了啥呢?
想想貌似也没干撒子啊!啊啊啊 啊啊 啊。其实很简单:request库在我看来是请求数据的,re是正则匹配库,那么就有人问了,(等等,谁tm的问了,你特么的自己问的吧?好吧,就是我问的),正则匹配可以自行百度,我觉得我一时半会儿也说不清,因为我也不清楚啊 ,哈哈哈。os库那是系统库。
爬取网站之前,需要对网页源代码进行分析一波,要不然怎么爬取我们需要的呢,你说是吧。

此时的我们需要什么呢,我们需要该图片的url,只要能自动定位到该网址,并且将该网址提取出来,就可以得到该图片了。这时候就要用到正则匹配了,我们可以通过找到正则匹配从一堆代码中快速提取出有用的信息了。
通过寻找规律,并运用正则匹配提取出有用的信息,正则匹配代码如下
import re
re.compile('<h1>(.*?)</h1>.*?<div id="nrbody".*?<img src="(.*?)".*?</p></div>',re.S)
(.*?)中提取的就是我们需要的网址和图片的名称。
以上代码就可以提取出该图片的URL,我们就可以很轻易的通过python的request库获取到该图片资源并保存了。
提取出来的信息,如下图所示:

看到了,这就是正则匹配从该html代码中提取出来的图片信息,名字用来命名保存图片,提取的网址可以用于获取图片数据。
好啦,上述只是分析了一个网页的图片,那么如何让python连续的爬取图片呢,你仔细观察网站,可以看到,这些不同网页之间是有关联的,http://www.51xiaohua.com/baoxiaoegao/(一串数字).html,你仔细看,这些数字不同就会产生不同的网页,所以我们只需要改变这一串数字即可改变网页,而不同的网页那些代码之间是有规律的,所以还是可以用之前的正则匹配提取有效的信息。
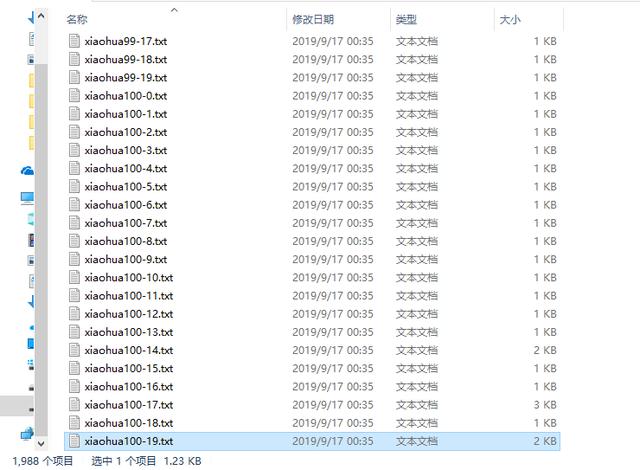
最后,那就来看看爬取的效果吧!

可以看到,已经爬取了一定量的搞笑图片了,朋友,If you are bored,you can try this.
最后附上源代码:
import requests
import re
import osdef get_html(url):headers = {'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 49.0.2623.221Safari / 537.36SE2.XMetaSr1.0'}res = requests.get(url, headers = headers)#print(res.status_code)if res.status_code == 200:return reselse:return Nonedef parse(html):patter = re.compile('<h1>(.*?)</h1>.*?<div id="nrbody".*?<img src="(.*?)".*?</p></div>',re.S)res = re.findall(patter, html)#print(res)return resdef main():for i in range(112000,113001,1):url = 'http://www.51xiaohua.com/baoxiaoegao/' + str(i) + '.html'print('正在爬取第%d张图片'.center(40,'*') %(i-111000+1))ss = get_html(url)#print(ss.text)if ss == None:continuehtml = ss.text#print(html)res = parse(html)#print(res)con = get_html('http:' + res[0][1])#print(con.content)path = 'D:\\爬取的搞笑图片\\'if not os.path.exists(path):os.makedirs(path)res = res[0][0]res = res.replace('?','')with open(path + res + '.png', 'wb') as f:f.write(con.content)if __name__ == '__main__':main()
作为一个搞UWOC的人来说,这仅仅是爱好(根本没时间去学习好吧 ),水平实在有限,作为爱好,慢慢来吧。