目录
文本三剑客
grep
grep和egrep
grep命令格式
grep命令格式
grep运用示例
正则表达式
基本正则表达式
拓展正则表达式
sed
使用sed
sed用法示例
常用选项options示例
地址界定示例
编辑命令示例
sed高级编辑命令
awk
awk的使用
printf命令
操作符
awk PATTERN
awk高阶用法
awk控制语句(if-else判断)
awk控制语句(while循环)
awk控制语句(do-while循环)
awk控制语句(for循环)
与shell脚本中相似的语句
awk数组
文本三剑客
grep
grep和egrep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。
egrep = grep -E:扩展的正则表达式 (除了< , > , \b 使用其他正则都可以去掉\)
grep命令格式
grep` `[option] pattern ``file
grep命令格式
-
-A(显示行数):除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-
-B(显示行数):除了显示符合样式的那一列之外,并显示该行之前的内容。
-
-C(显示行数):除了显示符合样式的一行之外,并显示该行前后的内容。
-
-c:统计匹配的行数。
-
-e:实现多个选项间的逻辑or关系。
-
-E:拓展的正则表达式。
-
-f FILE:从FILE获取PATTERN匹配
-
-F:相当于fgrep
-
-i:忽略字符大小写的差别。
-
-n:显示匹配的行号
-
-o:仅显示匹配到的字符串
-
-q:静默模式,不输出任何信息
-
-s:不显示错误信息
-
-v:显示不被pattern匹配到的行,相当于[^]反向匹配
-
-w:匹配整个单词
grep运用示例
[root@localhost ~]# grep -A2 b test
bbbbb
AAAaaa
BBBBASDABBDA
[root@localhost ~]# grep -B1 b test
aaa
bbbbb
[root@localhost ~]# grep -C1 b test
aaa
bbbbb
AAAaaa
[root@localhost ~]# grep -c aaa test
2
[root@localhost ~]# grep -e AAA -e bbb test
bbbbb
AAAaaa
[root@localhost ~]# grep -in b test
2:bbbbb
4:BBBBASDABBDA
[root@localhost ~]# grep -o ASDA test
ASDA
[root@localhost ~]# grep -q aa test
[root@localhost ~]# grep -v aaa test
bbbbb
BBBBASDABBDA
[root@localhost ~]# grep -w aaa test
aaa正则表达式
(1)介绍
正则表达式应用广泛,在绝大多数的编程语言都可以完美应用,在Linux中,也有着极大的用处。
使用正则表达式,可以有效的筛选出需要的文本,然后结合相应的支持的工具或语言,完成任务需求。
(2)正则表达式类型
正则表达式可以使用正则表达式引擎实现,正则表达式引擎世界是正则表达式模式,并使用这些模式匹配文本的基础软件。
在Linux中,常用的正则表达式有:
-
POSIX 基本正则表达式(BRE)引擎
-
POSIX 扩展正则表达式(BRE)引擎
基本正则表达式
匹配字符
(1)格式
-
. 匹配任意单个字符,不能匹配空行
-
[] 匹配指定范围内的任意单个字符
-
[^] 取反
-
[:alnum:] 或 [0-9a-zA-Z]
-
[:alpha:] 或 [a-zA-Z]
-
[:upper:] 或 [A-Z]
-
[:lower:] 或 [a-z]
-
[:blank:] 空白字符(空格和制表符)
-
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
-
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
-
[:digit:] 十进制数字 或[0-9]
-
[:xdigit:]十六进制数字
-
[:graph:] 可打印的非空白字符
-
[:print:] 可打印字符
-
[:punct:] 标点符号
(2)示例:
[root@localhost ~]# cat test1
abc
123
[root@localhost ~]# grep . test1
abc
123
[root@localhost ~]# grep [a/] test1
abc
[root@localhost ~]# grep [^abc] test1
123
[root@localhost ~]# grep [[:alnum:]] test1
abc
123
[root@localhost ~]# grep [a-z] test1
abc
[root@localhost ~]# grep [[:space:]] test1
[root@localhost ~]# grep [[:punct:]] test1配置次数
(1)格式
-
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
-
.* 任意前面长度的任意字符,不包括0次
-
\? 匹配其前面的字符0 或 1次
-
+ 匹配其前面的字符至少1次
-
{n} 匹配前面的字符n次
-
{m,n} 匹配前面的字符至少m 次,至多n次
-
{,n} 匹配前面的字符至多n次
-
{n,} 匹配前面的字符至少n次
(2)示例:
[root@localhost ~]# cat test2
ggle
gogle
google
gooooooooooooooooogle
gagle
[root@localhost ~]# grep "g[o]*gle" test2
ggle
gogle
google
gooooooooooooooooogle
[root@localhost ~]# grep "g[o]\?gle" test2
ggle
gogle
[root@localhost ~]# grep "g[o]\+gle" test2
gogle
google
gooooooooooooooooogle
[root@localhost ~]# grep "g[o]\{1,2\}gle" test2
gogle
google
[root@localhost ~]# grep -E "g[o]{10,}gle" test2
gooooooooooooooooogle
[root@localhost ~]# egrep "g[o]{,10}gle" test2
ggle
gogle
google分组和后向引用
(1)格式
分组:0将一个或多个字符绑定在一起,当作一个整体进行处理。
分组括号中的模式匹配到的内容会被正则表达式引擎记录与内部的变量中,这写变量的命名方式为:\1,\2,\3...
向后引用
引用前面的分组括号中的模式所匹配字符,而非模式本身。
\1表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符。
\2表哦是从左侧起第二个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推。
&表示前面的分组中所有字符。
流程分析如下:

[root@localhost ~]# cat test4
Hello world Hello world
Hiiii world Hiiii world
Hello world Heiii wwwww
[root@localhost ~]# grep "\(He\)" test4
Hello world Hello world
Hello world Heiii wwwww
[root@localhost ~]# grep "\(He\).*\1" test4
Hello world Hello world
Hello world Heiii wwwww
[root@localhost ~]# grep "\(He\).*\(wo\).*\2" test4
Hello world Hello world拓展正则表达式
(1)字符匹配
-
.:任意单个字符
-
[]:指定范围的字符
-
[^]:不在指定范围的字符
-
*:匹配前面字符任意次
-
?:匹配0或1次
-
+:匹配1次或多次
-
{m}:匹配m次
-
{m, n}:匹配至少m次,之多n次
(2)位置锚定
-
^:行首
-
$:行尾
-
<,\b:语首
-
>, \b : 语尾
-
分组:()
-
后向引用:\1, \2, ...
注意:除了<, \b : 语首、>, \b : 语尾;使用其他正则都可以去掉\;
sed
介绍:sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间(patternspace)”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使如“D”的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,指导文件末尾。文件内容并没有改变,除非你使用重定向输出或-i。主要用来自动编辑一个或多个文件,简化对文件的反复操作。
使用sed
命令格式
sed` `[options] ``'[地址定界] command'` `file``(s)
常用选项options
-
-n:不能输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
-
-e:多点编辑,对每行处理时,可以有多个Script
-
-f:把Script写到文件当中,在执行sed时-f指定文件路径,如果是多个Script,换行写
-
-r:支持拓展的正则表达式
-
-i:直接将处理的结果写入文件
-
-i.bak:再将处理的结果写入文件之前备份一份
地址定界
-
不给地址:对全文进行处理
-
单地址:
-
#:指定的行
-
/pattern/:被此处模式所能够匹配到的每一行
-
-
地址范围:
-
#,#
-
#,+#
-
/pat1/,/pat2/
-
#,/pat1/
-
-
~:步进
-
sed -n '1~2p' 只打印奇数行(1~2从第1行起,每次加2行)
-
sed -n '2~2p' 只打印偶数行
-
编辑命令
-
d:删除模式空间匹配的行,并立即启用下一轮循环
-
p:打印当前模式空间内容,追加到默认输出之后
-
a:在指定行后面追加文本,支持使用\n实现多行追加
-
i:在行前面插入文本,支持使用\n实现多行追加
-
c:替换成为单行或多行文本,支持使用\n实现多行追加
-
w:保存模式匹配的行至指定文件
-
r:拂去指定文件的文本至模式空间中匹配到的行后
-
=:为模式空间中的行打印行号
-
!:模式空间中匹配行取反处理
-
s/(1)/(2)/:查找替换,将内容(1)替换为(2),支持使用其他分隔符,如:s@@@,s###:
-
加g表示行内全局替换;
-
在替换时,可以加一下命令,实现大小写转换
-
\l:拔下个字符转换成小写
-
\L:把repalcement字母替换成小写,直到\U或\E出现
-
\u:把下个字符替换成大写
-
\U:把replacement字母转换成大写,知道\L或\E出现
-
\E:停止以\L或\U开始的大小写转换
-
sed用法示例
常用选项options示例
[root@localhost ~]# clear
[root@localhost ~]# cat demo
aaa
bbbb
AABBCCDD
[root@localhost ~]# sed "/aaa/p" demo #匹配到的行会打印一遍,没有匹配到的行也会打印
aaa
aaa
bbbb
AABBCCDD
[root@localhost ~]# sed -n "/aaa/p" demo #-n只打印匹配到的行
aaa
[root@localhost ~]# sed -e "s/a/A/" -e "s/b/B/" demo #-e多点编辑
Aaa
Bbbb
AABBCCDD
[root@localhost ~]# cat sedscript.txt
s/A/a/g
[root@localhost ~]# sed -f sedscript.txt demo #-f使用文件处理
aaa
bbbb
aaBBCCDD
[root@localhost ~]# sed -i.bak "s/a/A/g" demo #-i直接对文件进行处理
[root@localhost ~]# cat demo
AAA
bbbb
AABBCCDD
[root@localhost ~]# cat demo.bak
aaa
bbbb
AABBCCDD地址界定示例
[root@localhost ~]# cat demo
aaa
bbbb
AABBCCDD
[root@localhost ~]# sed -n "p" demo #不指定行,打印全文
aaa
bbbb
AABBCCDD
[root@localhost ~]# sed "2s/b/B/g" demo #将第2行的b替换为B
aaa
BBBB
AABBCCDD
[root@localhost ~]# sed -n "/aaa/p" demo
aaa
[root@localhost ~]# sed -n "1,2p" demo #打印1-2行
aaa
bbbb
[root@localhost ~]# sed -n "/aaa/,/DD/p" demo
aaa
bbbb
AABBCCDD
[root@localhost ~]# sed -n "2,/DD/p" demo
bbbb
AABBCCDD
[root@localhost ~]# sed "1~2s/[aA]/E/g" demo #将奇数行的a或A替换为E
EEE
bbbb
EEBBCCDD编辑命令示例
[root@localhost ~]# cat demo
aaa
bbbb
AABBCCDD
[root@localhost ~]# sed "2d" demo #删除第2行的内容
aaa
AABBCCDD
[root@localhost ~]# sed -n "2p" demo #打印第2行的内容
bbbb
[root@localhost ~]# sed "2a123" demo #在第2行后面追加123
aaa
bbbb
123
AABBCCDD
[root@localhost ~]# sed "1i123" demo #在第1行前面插入123
123
aaa
bbbb
AABBCCDD
[root@localhost ~]# sed "3c123\n456" demo #替换第3行的内容
aaa
bbbb
123
456
[root@localhost ~]# sed -n "3w/root/demo3" demo #保存第3行的内容到文件demo3中
[root@localhost ~]# cat demo3
AABBCCDD
[root@localhost ~]# sed "1r/root/demo3" demo #读取demo3中的内容到第1行后
aaa
AABBCCDD
bbbb
AABBCCDD
[root@localhost ~]# sed -n "=" demo #打印行号
1
2
3
[root@localhost ~]# sed -n '2!p' demo #打印除了第2行的内容
aaa
AABBCCDD
[root@localhost ~]# sed 's@[a-z]@\u&@g' demo #将全文的小写字母替换为大写字母
AAA
BBBB
AABBCCDDsed高级编辑命令
(1)格式
-
h:把模式空间中的内容覆盖至保持空间中
-
H:把模式空间中的内容追加至保持空间中
-
g:从保持空间中取出数据覆盖至模式空间中
-
G:从保持空间中取出数据追加至模式空间中
-
x:把模式空间中的内容语保持空间中的内容进行互换
-
n:读取匹配到的行的下一行覆盖至模式空间中
-
N:读取匹配到的行的下一行追加至模式空间中
-
d:删除模式空间中的行
-
D:删除当前模式空间开端至\n的内容(不再传至标准输出),放弃之后的命令,但是对剩余模式空间重新执行sed
(2)案例+示意图演示
[root@localhost ~]# cat num.txt
One
Two
Three
[root@localhost ~]# sed '1!G;h;$!d' num.txt
Three
Two
One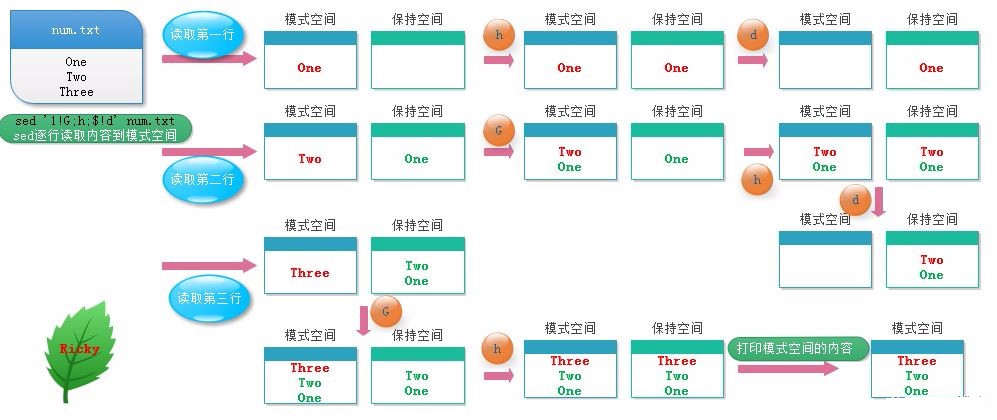
保持空间是模式空间一个临时存放数据的缓冲区,协助模式空间进行数据处理。
(3)示例
显示偶数行
[root@localhost ~]# seq 9 | sed -n 'n;p'
2
4
6
8倒序显示
[root@localhost ~]# seq 9 | sed '1!G;h;$!d'
9
8
7
6
5
4
3
2
1显示奇数行
[root@localhost ~]# seq 9 | sed 'H;n;d'
1
3
5
7
9显示最后一行
[root@localhost ~]# seq 9 | sed 'N;D'
9每行之间加空行
[root@localhost ~]# seq 9 | sed 'G'
1
2
3
4
5
6
7
8
9
[root@localhost ~]# 将每行内容替换成空行
[root@localhost ~]# seq 9 | sed "g"
确保每一行下面都有一个空行
[root@localhost ~]# seq 9 | sed '/^$/d;G'
1
2
3
4
5
6
7
8
9
[root@localhost ~]# awk
介绍:awk是一种编程语言,用于在Linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其他命令的输出。它支持用户自定义函数和动态 正则表达式等先进功能,是Linux/unix下的一个强大编程工具。它在命令行中使用,但更多的是作为脚本来使用。awk有很多内建的功能,例如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
awk其实不仅仅是工具软件,还是一种编程语言。
awk的使用
语法
awk` `[options] ``'program'` `var=value ``file``…``awk` `[options] -f programfile var=value ``file``…``awk` `[options] ``'BEGIN{ action;… } pattern{ action;… } END{ action;… }'` `file` `...
常用命令选项
-
-F fs:fs指定输入分隔符,fs可以是字符串或者正则表达式,如-F
-
-v var=value:赋值一个用户定义变量,将外部变量传递给awk
-
-f scripfile:从脚本文件中读取awk命令
awk变量
内置变量
(1)格式
-
FS:输入字段分隔符,默认为空白字符
-
OFS:输出字段分隔符,默认为空白字符
-
RS:输入记录分隔符,指定输入时的换行符,原换行符仍有效
-
ORS:输出记录分隔符,输出使用指定符号代替换行符
-
NF:字段数量,共有多少字段,$NF引用最后一列,$(NF-1)引用倒数第2列
-
NR:行号,后可跟多个文件,第2个文件行号继续从第一个文件最后行号开始
-
FNR:各文件分别计数,行号后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
-
FILENAME:当前文件名
-
ARGC:命令行参数的个数
-
ARGV:数组,保存的时命令行所给定的各参数,查看参数
(2)示例
[root@localhost ~]# cat awkdemo
hello:world
linux:redhat:lalala:hahaha
along:love:youou
[root@localhost ~]# awk -v FS=':' '{print $1,$2}' awkdemo
hello world
linux redhat
along love
[root@localhost ~]# awk -v FS=':' -v OFS='---' '{print $1,$2}' awkdemo
hello---world
linux---redhat
along---love
[root@localhost ~]# awk -v RS=':' '{print $1,$2}' awkdemo
hello
world linux
redhat
lalala
hahaha along
love
youou
[root@localhost ~]# awk -v FS=':' -v ORS='---' '{print $1,$2}' awkdemo
hello world---linux redhat---along love---
[root@localhost ~]# awk -F : '{print NF}' awkdemo
2
4
3
[root@localhost ~]# awk -F: '{print $(NF-1)}' awkdemo
hello
lalala
love自定义变量
自定义变量(区分大小写)
(1)-v var=value
先定义变量,后执行动作print
[root@localhost ~]# awk -v name="along" -F: '{print name":"$0}' awkdemo
along:hello:world
along:linux:redhat:lalala:hahaha
along:along:love:you在执行动作print后定义变量
[root@localhost ~]# awk -F: '{print name":"$0;name="along"}' awkdemo
:hello:world
along:linux:redhat:lalala:hahaha
along:along:love:you在program中直接定义
可以把执行的东顾总放在脚本中,直接调用脚本-f
[root@localhost ~]# cat awk.txt
{name="along";print name,$1}
[root@along ~]# awk -F: -f awk.txt awkdemo
along hello
along linux
along alongprintf命令
格式
(1)格式化输出
printf` ` "FORMAT"``, item1,iten2,...
必须指定FORMAT
不会自动换行,需要显示给出换行控制符,\n
FORMAT中需要分别为后面每个item指定格式符
(2)格式符
-
%c:显示字符的ASCII码
-
%d,%i:显示十进制整数
-
%e,%E:显示科学计数法数值
-
%f:显示为浮点数,小数%5.1f,带整数、小数点、整数共5位,小数1位,不够用空格补上
-
%g,%G:以科学计数法或浮点形式显示数值
-
%s:显示字符串,例:%5s最少5各字符,不够用空格补上,超过5各还继续显示
-
%u:无符号整数
-
%%:显示%自身
(3)修饰符,放在%c[/d/e/f...]之间
-
#[.#]:第一个数字控制显示的宽度,第二个#表示小数点后精度。%5.1f
-
-:左对齐(默认右对齐)%-15s
-
+:显示数值的正负符号%+d
示例
-----使用printf制作表格
[root@localhost ~]# awk -F: 'BEGIN{printf "username userid\n -----------------------------------\n"}{printf "%-20s|%-10.3f\n",$1,$3}' /etc/passwd
username userid-----------------------------------
root |0.000
bin |1.000
daemon |2.000
adm |3.000
lp |4.000
sync |5.000
shutdown |6.000
halt |7.000
mail |8.000
operator |11.000
games |12.000
ftp |14.000
nobody |99.000
systemd-network |192.000
dbus |81.000
polkitd |999.000
postfix |89.000
sshd |74.000
user001 |1000.000
apache |48.000
redhat |1001.000
操作符
格式:
-
算术操作符:
-
x+y,x-y,x*y,x/y,x^y,x%y
-
-x:转换为负数
-
+x:转换为数值
-
-
字符串操作符:没有符号的操作符,字符串连接
-
赋值操作符
-
=,+=,-=,/=,%=,……=
-
++,--
-
-
标胶操作符:
-
==,!=,>=,<,<=
-
-
模式匹配符:~:左边是否和右边匹配包含!~:是否不匹配
-
逻辑操作符:与&&,或||,非!
-
函数调用:function_name(argu1,argu2,...)
-
条件表达式(三目表达式):
selector
?
if-true-expression
:
if-false-expression
-
注释:先判断selector,如果符合,执行?后的操作;否则执行:后的操作
-
示例:
(1)模式匹配符
---查询以/dev开头的磁盘信息
[root@along ~]# df -h |awk -F: '$0 ~ /^\/dev/'
/dev/mapper/cl-root 17G 7.3G 9.7G 43% /
/dev/sda1 1014M 121M 894M 12% /boot
---只显示磁盘使用状况和磁盘名
[root@along ~]# df -h |awk '$0 ~ /^\/dev/{print $(NF-1)"---"$1}'
43%---/dev/mapper/cl-root
12%---/dev/sda1
---查找磁盘大于40%的
[root@along ~]# df -h |awk '$0 ~ /^\/dev/{print $(NF-1)"---"$1}' |awk -F% '$1 > 40'(2)逻辑操作符
[root@along ~]# awk -F: '$3>=0 && $3<=1000 {print $1,$3}' /etc/passwd
root 0
bin 1
[root@along ~]# awk -F: '$3==0 || $3>=1000 {print $1}' /etc/passwd
root
[root@along ~]# awk -F: '!($3==0) {print $1}' /etc/passwd
bin
[root@along ~]# awk -F: '!($0 ~ /bash$/) {print $1,$3}' /etc/passwd
bin 1
daemon 2(3)条件表达式(三目表达式)
[root@along ~]# awk -F: '{$3 >= 1000?usertype="common user":usertype="sysadmin user";print usertype,$1,$3}' /etc/passwd
sysadmin user root 0
common user along 1000awk PATTERN
格式:
PATTERN:根据pattern条件,过滤匹配的行,再做处理
(1)如果未指定:空模式,匹配每一行
(2)/regular expression/:仅处理能够匹配到的行,正则,需要用//括起来
(3)relational expression:关系表达式,结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值
(4)line ranges:行范围
startline(起始行),endline(结束行):/pat1/,/pat2/ 不支持直接给出数字,可以有多段,中间可以有间隔
(5)BEGIN/END模式
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成后执行
示例:
[root@along ~]# awk -F: '{print $1}' awkdemo
hello
linux
along
[root@along ~]# awk -F: '/along/{print $1}' awkdemo
along
[root@along ~]# awk -F: '1{print $1}' awkdemo
hello
linux
along
[root@along ~]# awk -F: '0{print $1}' awkdemo
[root@along ~]# awk -F: '/^h/,/^a/{print $1}' awkdemo
hello
linux
along
[root@along ~]# awk -F: 'BEGIN{print "第一列"}{print $1} END{print "结束"}' awkdemo
第一列
hello
linux
along
结束awk高阶用法
awk控制语句(if-else判断)
(1)语法
if(condition){statement;…}[else statement] 双分支
if(condition1){statement1}else if(condition2){statement2}else{statement3} 多分支
(2)使用场景:对awk取得的整行或某个字段做条件判断
(3)示例
[root@localhost ~]# awk -F: '{if($3>10 && $3<1000)print $1,$3}' /etc/passwd
operator 11
games 1
[root@localhost ~]# awk -F: '{if($NF=="/bin/bash") print $1,$NF}' /etc/passwd
root /bin/bash
along /bin/bash
---输出总列数大于3的行
[root@localhost ~]# awk -F: '{if(NF>2) print $0}' awkdemo
linux:redhat:lalala:hahaha
along:love:you
---第3列>=1000为Common user,反之是root or Sysuser
[root@localhost ~]# awk -F: '{if($3>=1000) {printf "Common user: %s\n",$1} else{printf "root or Sysuser: %s\n",$1}}' /etc/passwd
root or Sysuser: root
root or Sysuser: bin
Common user: along
---磁盘利用率超过40的设备名和利用率
[root@localhost ~]# df -h|awk -F% '/^\/dev/{print $1}'|awk '$NF > 40{print $1,$NF}'
/dev/mapper/cl-root 43
---test=100和>90为very good; 90>test>60为good; test<60为no pass
[root@localhost ~]# awk 'BEGIN{ test=100;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
very good
[root@localhost ~]# awk 'BEGIN{ test=80;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
good
[root@localhost ~]# awk 'BEGIN{ test=50;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
no passawk控制语句(while循环)
(1)语法
while``(condition){statement;…}
备注:条件“真”,进入循环;条件“假”,退出循环。
(2)使用场景
最一行内的多个字段逐一类似处理使用
对数组中的个元素逐一处理时使用
(3)示例
---以along开头的行,以:为分隔,显示每一行的每个单词和其长度
[root@along ~]# awk -F: '/^along/{i=1;while(i<=NF){print $i,length($i); i++}}' awkdemo
along 5
love 4
you 3
---以:为分隔,显示每一行的长度大于6的单词和其长度
[root@along ~]# awk -F: '{i=1;while(i<=NF) {if(length($i)>=6){print $i,length($i)}; i++}}' awkdemo
redhat 6
lalala 6
hahaha 6
---计算1+2+3+...+100=5050
[root@along ~]# awk 'BEGIN{i=1;sum=0;while(i<=100){sum+=i;i++};print sum}'
5050
awk控制语句(do-while循环)
(1)语法
do` `{statement;…}``while``(condition)
意义:无论真假,至少执行一次循环体
(2)计算1+2+3+……+100=5050
[root@along ~]# awk 'BEGIN{sum=0;i=1;do{sum+=i;i++}while(i<=100);print sum}'
5050awk控制语句(for循环)
(1)语法
for``(expr1;expr2;expr3) {statement;…}
(2)特殊用法:遍历数组中的元素
for``(var ``in` `array) {``for``-body}
(3)示例
---显示每一行的每个单词和其长度
[root@along ~]# awk -F: '{for(i=1;i<=NF;i++) {print$i,length($i)}}' awkdemo
hello 5
world 5
linux 5
redhat 6
lalala 6
hahaha 6
along 5
love 4
you 3
---求男m、女f各自的平均
[root@along ~]# cat sort.txt
xiaoming m 90
xiaohong f 93
xiaohei m 80
xiaofang f 99
[root@along ~]# awk '{m[$2]++;score[$2]+=$3}END{for(i in m){printf "%s:%6.2f\n",i,score[i]/m[i]}}' sort.txt
m: 85.00
f: 96.00与shell脚本中相似的语句
break和continue
---奇数相加
[root@localhost nice]# awk 'BEGIN{sum=0;for(i=1;i<=100;i++) {if(i%2==0)continue;sum+=i}print sum}'
2500
---1+2+……+66
[root@localhost nice]# awk 'BEGIN{sum=0;for(i=1;i<=100;i++){if(i==66)break;sum+=i}print sum}'
2145next
next:提前结束对文本处理而直接进入下一行处理(awk自身循环)
[root@localhost nice]# awk -F: '{if(NE%2!=0) next;print $1,$3}' /etc/passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 99
systemd-network 192
dbus 81
polkitd 999
postfix 89
sshd 74
user001 1000
apache 48
redhat 1001awk数组
关联数组:array[index-expression]
(1)可使用任意字符串:字符串要使用双引号括起来
(2)如果其数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串”
(3)若要判断数组中是否存在某元素,要使用“index in array”格式进行遍历
(4)若要遍历数组中的每个元素,要使用for循环:for(var in array){for-body}
示例
[root@along ~]# cat awkdemo2
aaa
bbbb
aaa
123
123
123
---去除重复的行
[root@localhost nice]# awk '!arr[$0]++' awkdemo
aaa
bbbb
123
123
---打印文件内容,和该行重复第几次出现
[root@localhost nice]# awk '{!arr[$0]++;print $0,arr[$0]}' awkdemo
aaa 1
bbbb 1
aaa 2
123 1
123 2
123 1分析:把每行作为下标,第一次进来,相当于print ias……一样结果为空,打印空,! 取反结果为1,打印本行,并且++变为不空,下次进来相同的行就是相同的下表,本来上次的值,! 取反为空,不打印,++变为不空,所以每次重复进来的行都不打印。
数组遍历
[root@localhost nice]# awk 'BEGIN{print rand()}'
0.237788
[root@localhost nice]# awk 'BEGIN{srand();print rand()}'
0.0676647
[root@localhost nice]# awk 'BEGIN{srand();print rand()}'
0.0358619
[root@localhost nice]# awk 'BEGIN{srand();print int(rand()*100%50+1)}'
26
[root@localhost nice]# awk 'BEGIN{srand();print int(rand()*100%50+1)}'
43
[root@localhost nice]# awk 'BEGIN{srand();print int(rand()*100%50+1)}'
[root@localhost nice]# awk 'BEGIN{abc["ceo"]="along";abc["coo"]="mayun";abc["cto"]="mahuateng";for(i in abc){print i,abc[i]}}'
coo mayun
ceo along
cto mahuateng
[root@localhost nice]# awk '{for(i=1;i<=NF;i++)abc[$i]++}END{for(j in abc)print j,abc[j]}' awkdemo
aaa 2
bbbb 1
123 2
123 1数值\字符串处理
(1)数值处理
rand():返回0和1直接按的一个随机数,需要有个种子srand(),没有种子,一直输出0.127788
示例:
---输出0-1之间的随机数
[root@localhost nice]# awk 'BEGIN{print rand()}'
0.237788
[root@localhost nice]# awk 'BEGIN{srand();print rand()}'
0.0676647
[root@localhost nice]# awk 'BEGIN{srand();print rand()}'
0.0358619
---输出0-50之间的随机数
[root@localhost nice]# awk 'BEGIN{srand();print int(rand()*100%50+1)}'
26
[root@localhost nice]# awk 'BEGIN{srand();print int(rand()*100%50+1)}'
43字符串处理
-
length([s]):返回指定字符串的长度
-
sub(r,s,[t]):对t字符串进行搜索,r表示模式匹配内容,并将第一个匹配的内容替换为s
-
gsub(r,s,[t]);对t字符串进行搜索,r表示模式匹配的内容,并全部替换为s所表示的内容
-
split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第二个索引值为2,……
示例:
[root@localhost nice]# echo "2008:08:08 08:08:08" | awk 'sub(/:/,"-",$1)'
2008-08:08 08:08:08
[root@localhost nice]# echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$0)'
2008-08-08 08-08-08