引言
这篇文章将给大家讲解关于DolphinScheduler与AWS的EMR和Redshift的集成实践,通过本文希望大家能更深入地了解AWS智能湖仓架构,以及DolphinScheduler在实际应用中的重要性。
AWS智能湖仓架构
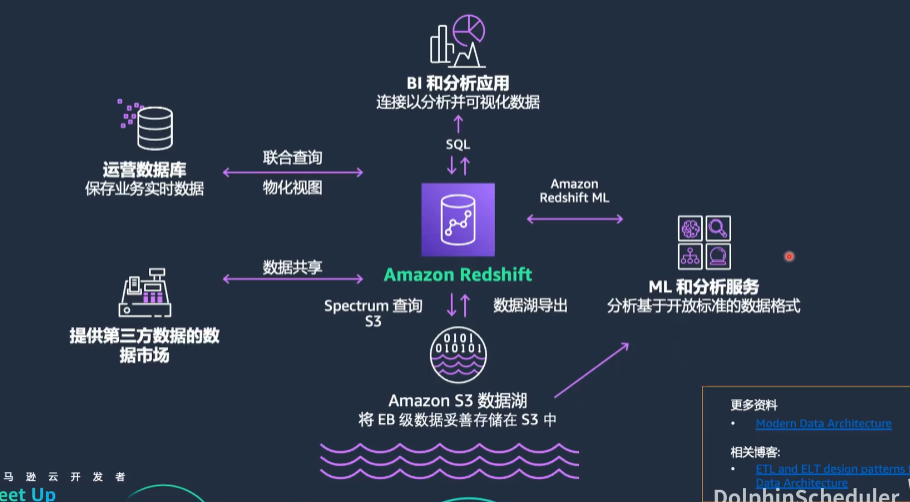
首先,我们来看一下AWS经典的智能湖仓架构图。

这张图展示了以S3为核心的数据湖,围绕数据湖的是各种组件,包括数据库、Hadoop的EMR、大数据处理、数据仓库、机器学习、日志查询和全文检索等。
这些组件形成一个完整的生态系统,确保数据能够在企业内部自由流动,无论是从外围到核心,还是从核心到外围。
智能湖仓架构的核心目标是实现数据在各个组件之间的自由移动,提升企业数据处理的灵活性和效率。
数据源与数据采集工具
为了让大家更直观地理解这张图,我们可以从左到右进行解读。左侧是各种数据源,包括数据库、应用程序以及数据采集和摄入工具。
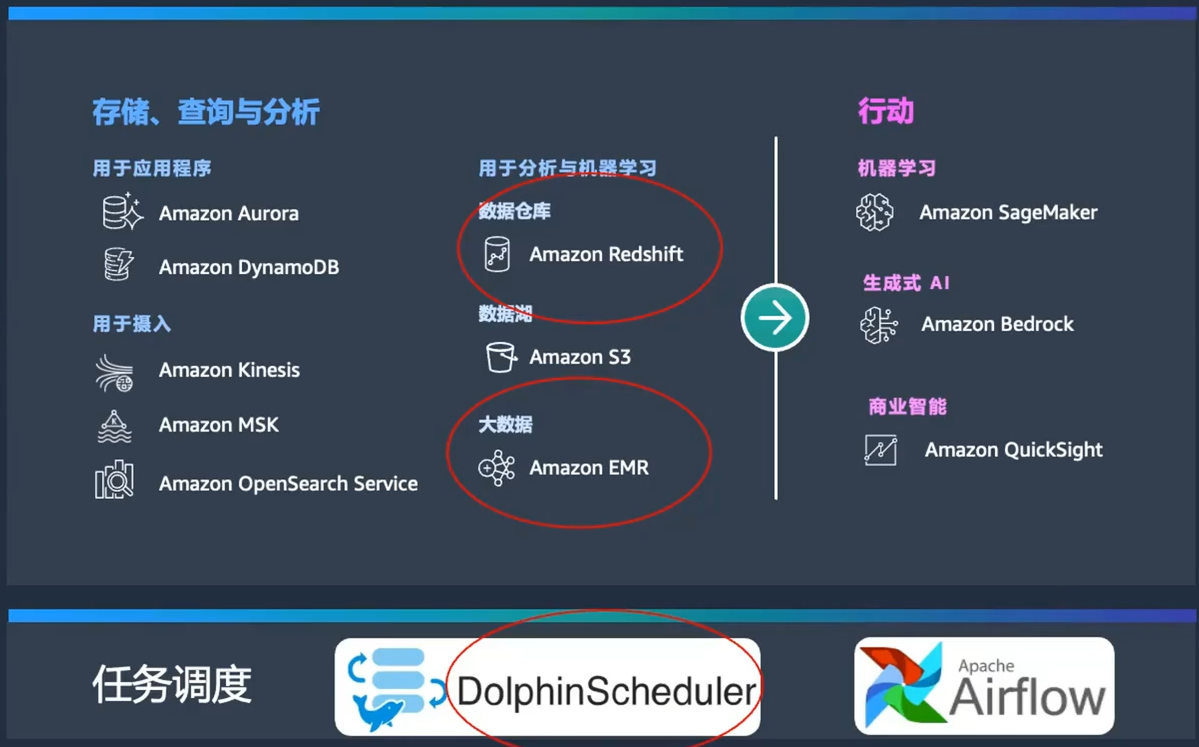
这些工具包括Kinesis、MSK(托管的Kafka)和OpenSearch,都是用于高效数据摄入的优秀工具。
核心组件介绍
今天的主角是图中圈起来的几个关键组件:
- Redshift:用于数据仓库的解决方案。
- EMR:Hadoop生态圈的大数据处理组件。
- DolphinScheduler:任务调度工具。
在大数据处理的下游,还包括BI(商业智能)、传统机器学习和最新的生成式AI,再往下是企业中的人、应用和设备。这张图展示了整个数据处理和分析的流程,使得数据处理过程更加直观和流畅。
今天的分享主要围绕以下两个核心点展开:
- EMR与DolphinScheduler的实践
- Redshift与DolphinScheduler的实践
在此之前,我们先对EMR做一个简要介绍。
Amazon EMR 简介
Amazon EMR(Elastic MapReduce)是亚马逊云技术提供的一款云端服务,用于轻松运行Hadoop生态圈的各类组件,包括Spark、Hive、Flink、HBase等。
其主要特点包括:
- 及时更新:紧跟开源社区的最新版本,30天内提供最新的开源版本更新。
- 自动弹性扩容和缩容:根据工作负载自动调整集群规模。
- 多种计价模式:灵活组合使用不同的计价模式,实现极致性价比。
EMR与自建Hadoop集群的比较
相比于传统IDC机房自建Hadoop集群,EMR具有以下优势:
- 充分发挥原生特性
- 多种计价模式组合使用
- 自动弹性扩容和缩容
成本分析
在使用Hadoop进行数据分析和大数据处理时,企业越来越关注成本控制,而不仅仅是性能。
下图展示了企业在IDC机房自建Hadoop集群的成本构成,包括服务器成本、网络成本、人工维护成本以及其他额外费用。这些成本往往非常高。
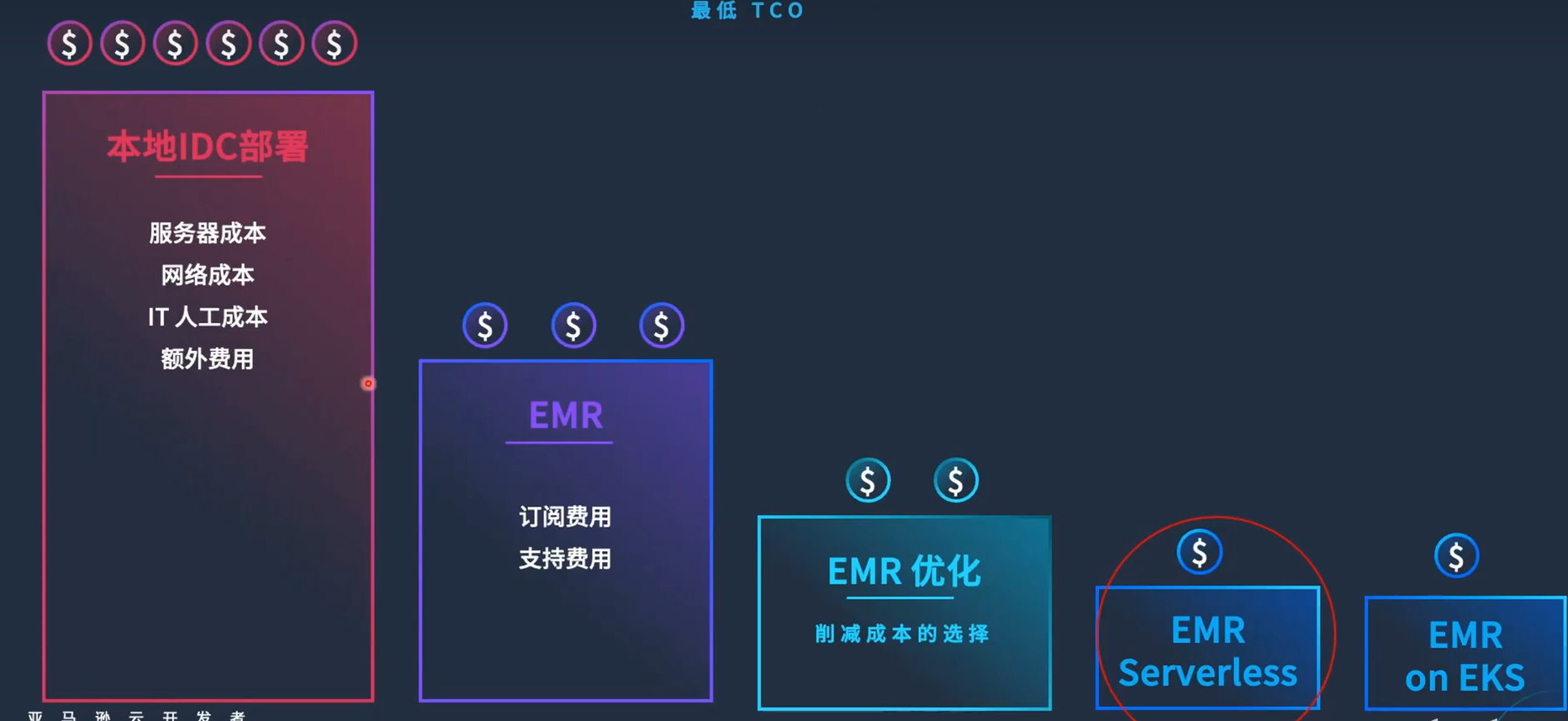
迁移到EMR的优势
许多企业由于本地扩容困难、长周期采购流程以及升级困难等原因,逐渐将Hadoop工作负载迁移到云上的EMR。
通过支付订阅费用和额外支持费用,企业可以享受到以下优势:
- 灵活的计价模式组合
- 自动弹性伸缩
- 参数调优
进一步优化
在完成初步优化后,部分企业可能仍觉得不满足其性价比的要求,进而转向使用EMR Serverless和EMR on EKS。这两者本质上都是基于容器化技术,旨在实现更高的性价比。
EMR Serverless
EMR Serverless让企业摆脱了对硬件和基础设施的维护,更加关注上层应用和业务开发,用户只需设置应用程序代码和相关参数即可。
EMR on EKS
EMR on EKS通过在Kubernetes上构建Hadoop集群,包括Spark和Flink等组件,进一步优化性价比。
不仅能提高数据处理的效率和灵活性,也使得企业能够更好地控制成本,实现业务目标。
实践案例分享:从IDC迁移到AWS EMR
接下来通过一个真实案例,分享一个客户从IDC迁移到AWS EMR的优化过程。这将帮助大家了解在云上使用EMR和DolphinScheduler的具体实践,以及如何通过这些工具实现性能和成本的双重优化。
客户背景与挑战
该客户原本在IDC机房采用CDH(Cloudera Distribution Hadoop),自建了一个Hadoop集群,共有13个节点。某个任务在机房内需要13个小时才能完成。客户希望通过迁移到云上,降低成本并提升效率。
迁移与优化过程
初始迁移
客户将其工作负载迁移到AWS云上,采用EMR On EC2。在迁移后的初始阶段,使用Hive on EMR,仅用了6个节点,任务时间缩短至10小时。此时并未进行任何调优。
接着,客户将Hive切换为Spark,仍使用6个节点,任务时间进一步缩短至3.5小时。
通过开启EMR的弹性伸缩功能,并将数据格式转换为parquet,任务时间进一步缩减至2.4小时。
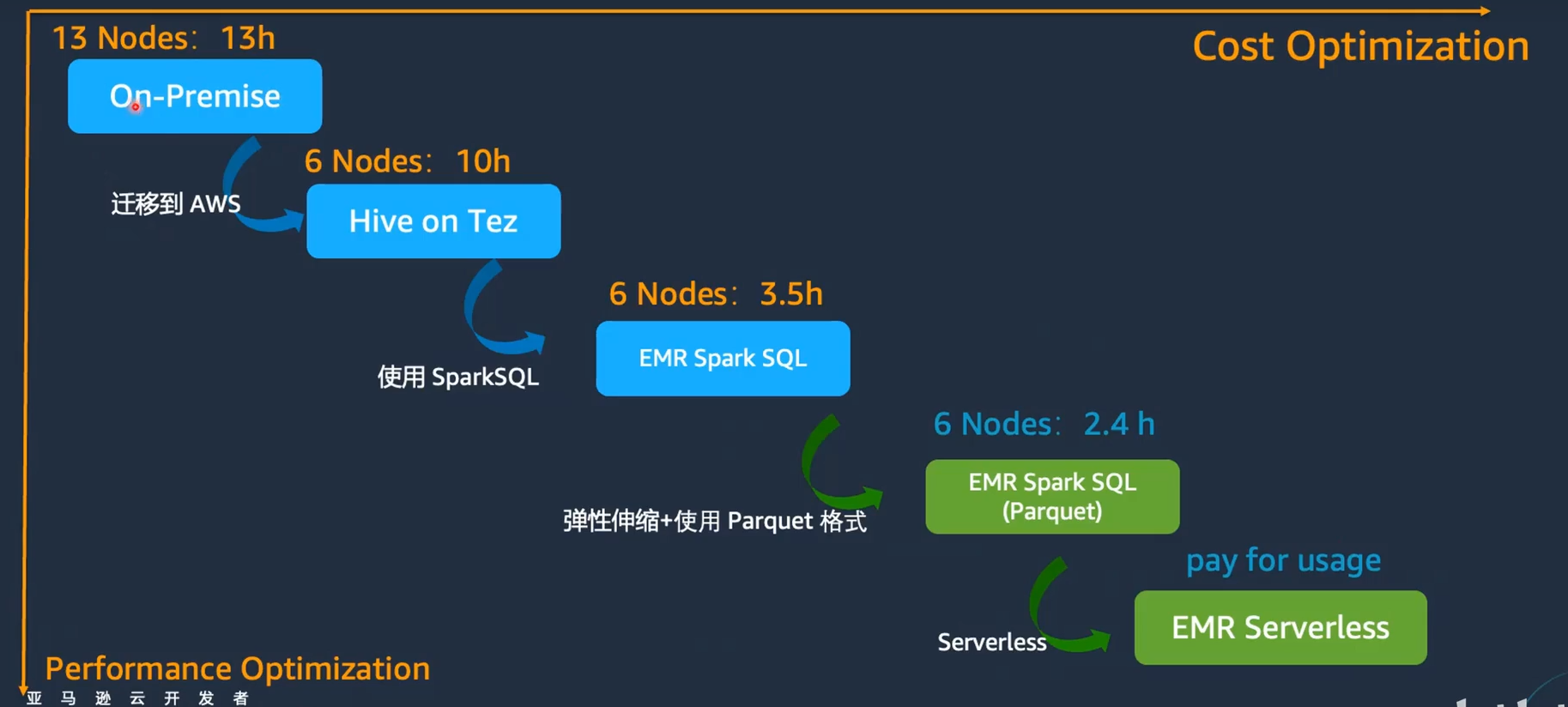
最终优化
客户实现了集群版EMR与EMR Serverless的混合使用,将部分工作负载迁移到EMR Serverless上,达到了极致的性价比,性能优化在很大程度上也代表了成本优化。
调度优化与实践
迁移后的调度方式
在迁移到云上的EMR On EC2后,客户的调度方式如下:
- 任务分布在24小时内,小任务每个大约需要20-30分钟。
- 较大的任务集中在一天的7小时内执行。
- 超级大的任务执行时间为3-5天,甚至一周,一次执行一个月可能只需要运行两三次。
优化调度
通过Apache DolphinScheduler,客户将工作负载分别调度到EMR On EC2和EMR Serverless上。
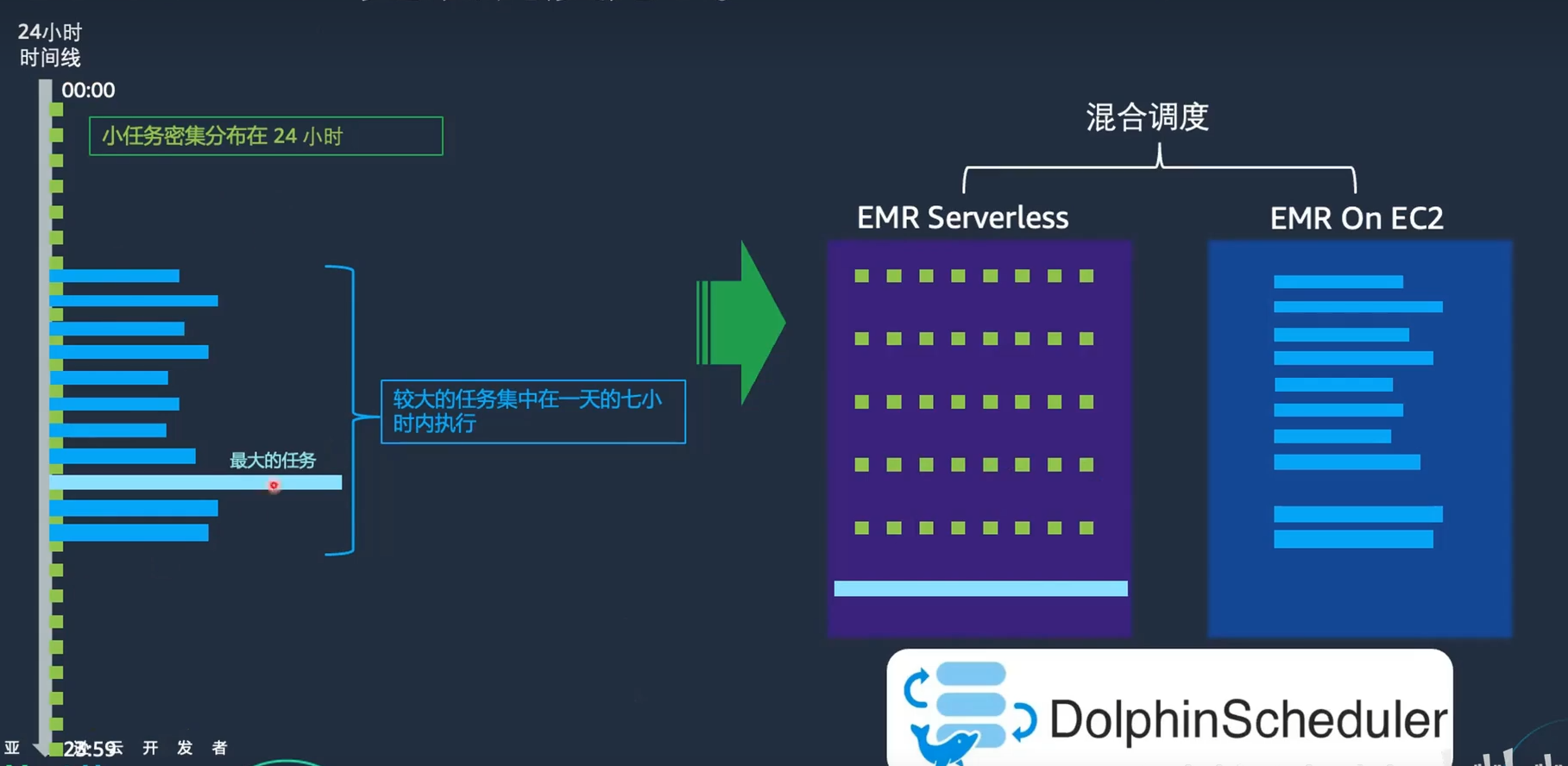
具体做法如下:
- 小任务:放到EMR Serverless上,因为这些任务不需要3-4台节点,10GB-20GB内存即可满足需求。
- 大任务:继续保留在EMR On EC2上,因为这些任务在云上运行时间相对集中,则可以集群定时开关,降低成本。
- 超级大任务:放到EMR Serverless上,通过监控每次运行的CPU和内存消耗,,将每次任务运行的成本可视化,便于针对性地、持续地进行成本优化。
统一元数据管理
使用AWS Glue作为统一的元数据管理工具,使得集群的创建、销毁、再创建过程无需恢复元数据或数据,同一份数据和元数据可以在EMR On EC2和EMR Serverless之间无缝使用。
挑战与解决方案
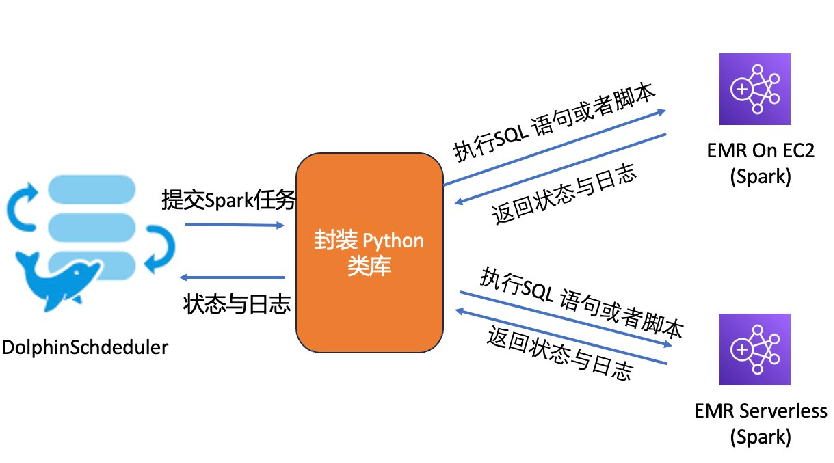
在此过程中,我们也遇到了一些挑战:
- 异步提交问题:EMR Serverless目前仅支持异步提交,而批处理任务需要同步执行。我们通过封装Python类库,实现了统一的API接口,解决了这个问题。
- 日志查看不一致:EMR和EMR Serverless的日志查看方式不同。通过DolphinScheduler,我们实现了统一的日志下载和查看,改善了客户体验。
- API接口差异:EMR和EMR Serverless的API接口不同。我们通过封装统一的API接口,减少了客户的维护成本。
- SQL提交限制:EMR Serverless暂时不支持直接提交SQL。我们通过Python脚本,间接实现了SQL提交。
解决方案实施
我们和客户一起封装了一个Python类库,通过这个类库,统一了EMR On EC2和EMR Serverless的任务提交、日志查询和状态查询接口。在DolphinScheduler中,客户可以通过统一的API无缝地的在EMR Serverless 和 EMR on EC2 之间切换工作负载。
例如,在DolphinScheduler上调度到EMR On EC2时,脚本如下:
from emr_common import Sessionsession_emr = Session(job_type=0)
session_emr.submit_sql("job_name","your_sql_query")
session_emr.submit_file("job_name","your_pyspark_script")
而调度到EMR Serverless时,脚本如下:
from emr_common import Sessionsession_emrserverless = Session(job_type=1)
session_emrserverless.submit_sql("your_sql_query")
session_emrserverless.submit_file("job_name","your_pyspark_script"通过Apache DolphinScheduler的参数传递特性,整个代码可以在不同引擎之间自由切换,实现了无缝调度。除了基本的job type参数之外,还有许多其他参数可供配置。
为了简化用户操作,系统为大部分参数设置了默认值,因此用户通常不需要手动配置这些参数。
例如,用户可以指定任务执行的集群,如果不指定,系统将默认选择第一个活跃的应用或集群ID。
此外,用户还可以为每个Spark任务设置driver和executor的相关参数。如果不指定这些参数,系统也会使用默认值。
封装Session
为了实现简化操作,我们封装了一个session对象,这个session包含两个子类:EMRSession和EMRServerlessSession。
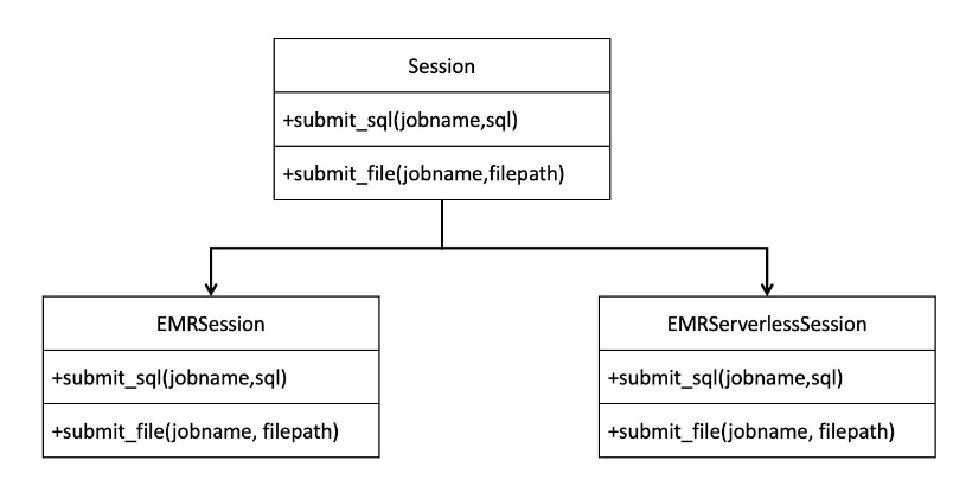
根据传入参数的不同,系统会创建相应的session对象,无论是提交SQL语句还是脚本文件,其接口从上到下都是一致的。
使用体验
下面通过一些DolphinScheduler的截图来展示其使用体验。
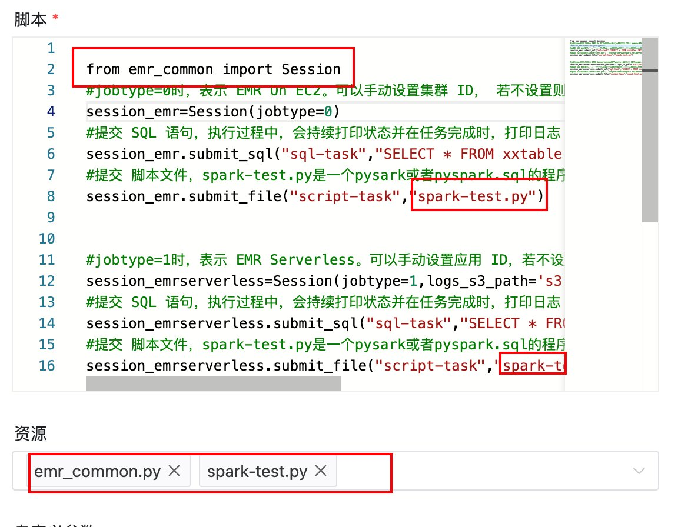
上图是DolphinScheduler上的一个Python Operator示例,包含了EMR On EC2和EMR Serverless的代码:
from emr_common import Session# EMR On EC2
session_emr = Session(job_type=0)
session_emr.submit_sql("job_name","your_sql_query")
session_emr.submit_file("job_name","your_pyspark_script")# EMR Serverless
session_emrserverless = Session(job_type=1)
session_emrserverless.submit_sql("your_sql_query")
session_emrserverless.submit_file("job_name","your_pyspark_script"实际效果
通过上述优化,客户不仅大幅缩短了任务运行时间,还实现了成本的大幅节约。
例如,在未调优情况下,任务时间从13小时缩短到10小时,而经过多次优化后,最终任务时间缩短到2.4小时,同时实现了集群版本EMR和Serverless版本的混合使用。
通过这个案例,我们可以看到,通过使用AWS EMR和DolphinScheduler,企业可以在保证性能的同时,大幅降低成本,实现更高的性价比。希望这个案例能为大家在云上进行大数据处理和优化提供一些借鉴和参考。
Redshift 实践分享
Redshift是AWS推出的云数据仓库,已经存在十多年,是业界最成熟的云数据仓库之一。通过Redshift,用户可以实现数据仓库、数据湖和数据库的无缝集成。
Redshift简介
Redshift是一款分布式数据仓库产品,支持以下功能:
- 联合查询与联邦查询:直接查询MySQL等关系数据库的数据,无需通过ETL导入Redshift。
- 与S3数据湖的集成:通过Redshift Spectrum,直接查询S3上的parquet等格式的数据,而无需将数据导入Redshift。
- 与机器学习的集成:在没有机器学习经验的情况下,通过写SQL就能快速且自动地完成特征工程与模型训练,然后进行趋势预测、销售预测、异常检测等应用。
Redshift不仅支持集群部署,还提供Serverless模式,在这种模式下,用户无需管理负载和资源扩展,只需关注SQL代码和数据开发应用,进一步地简化了数据开发的门槛,让大家更加专注业务层面的开发,而不要去关注过多的关注底层的运维。

自3.0版本起,DolphinScheduler支持Redshift数据源。通过DolphinScheduler的SQL Operator,用户可以直接编写Redshift的SQL,进行大数据开发和应用。
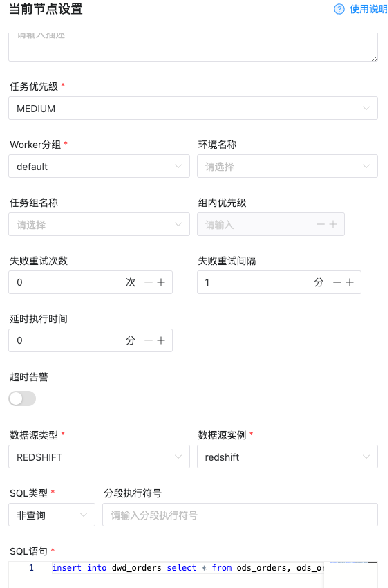
用户可以通过拖拽界面操作,轻松定制DAG并监控各个任务和流程的执行情况。
并发控制
Redshift是一个OLAP数据库,具有高吞吐量和快速计算的特点,但其并发扩展通常不超过50。这对于调度大量并发任务的客户来说是一个挑战。
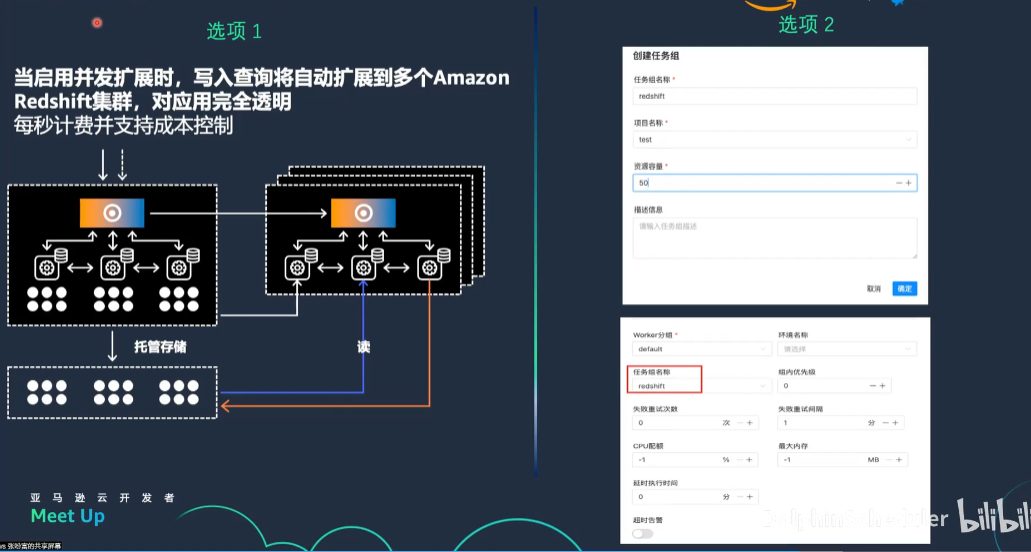
为了解决这一问题,有两个选项:
- 开启Redshift并发扩展:扩展到预置资源的10倍容量,但会增加额外成本。
- 使用DolphinScheduler的并发控制功能:创建任务组,设定资源容量,控制调度到Redshift的任务并发,避免集群过载。
Shell Operator实践
在使用DolphinScheduler进行Redshift开发时,推荐使用SQL Operator,但也可以使用Shell Operator,通过sql - fxxx.sql 命令执行SQL文件。
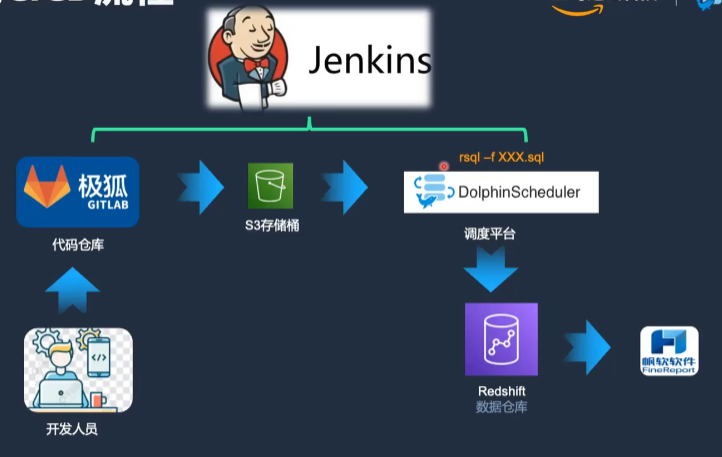
这种做法的好处在于可以与CICD流程集成。开发人员可以在个人电脑上通过GitLab开发代码,提交后自动上传到S3桶,DolphinScheduler支持从S3桶读取代码文件,并提交到Redshift中执行。
比如说通过Jenkins实现了代码推送到GitLab后,自动上传到S3存储桶。在DolphinScheduler的资源中心创建文件后,自动向S3写文件,并更新DolphinScheduler的元数据,实现了CICD的无缝集成。
总结
今天我们分享了EMR与EMR Serverless和DolphinScheduler的整合经验和实践,以及Redshift与DolphinScheduler的集成实践。以下是我个人对DolphinScheduler社区的期望和展望:
- SQL语法树解析生成血缘关系:希望DolphinScheduler能提供基于SQL语法树解析生成的数据血缘关系,尤其是字段级别的血缘关系。
- 引入AI agent编排流程:希望未来DolphinScheduler能考虑引入AI agent的编排流程,或引入AI agent的Operator。

感谢大家的观看,如果想了解更多详情,欢迎加小助手进群交流。
本文由 白鲸开源科技 提供发布支持!