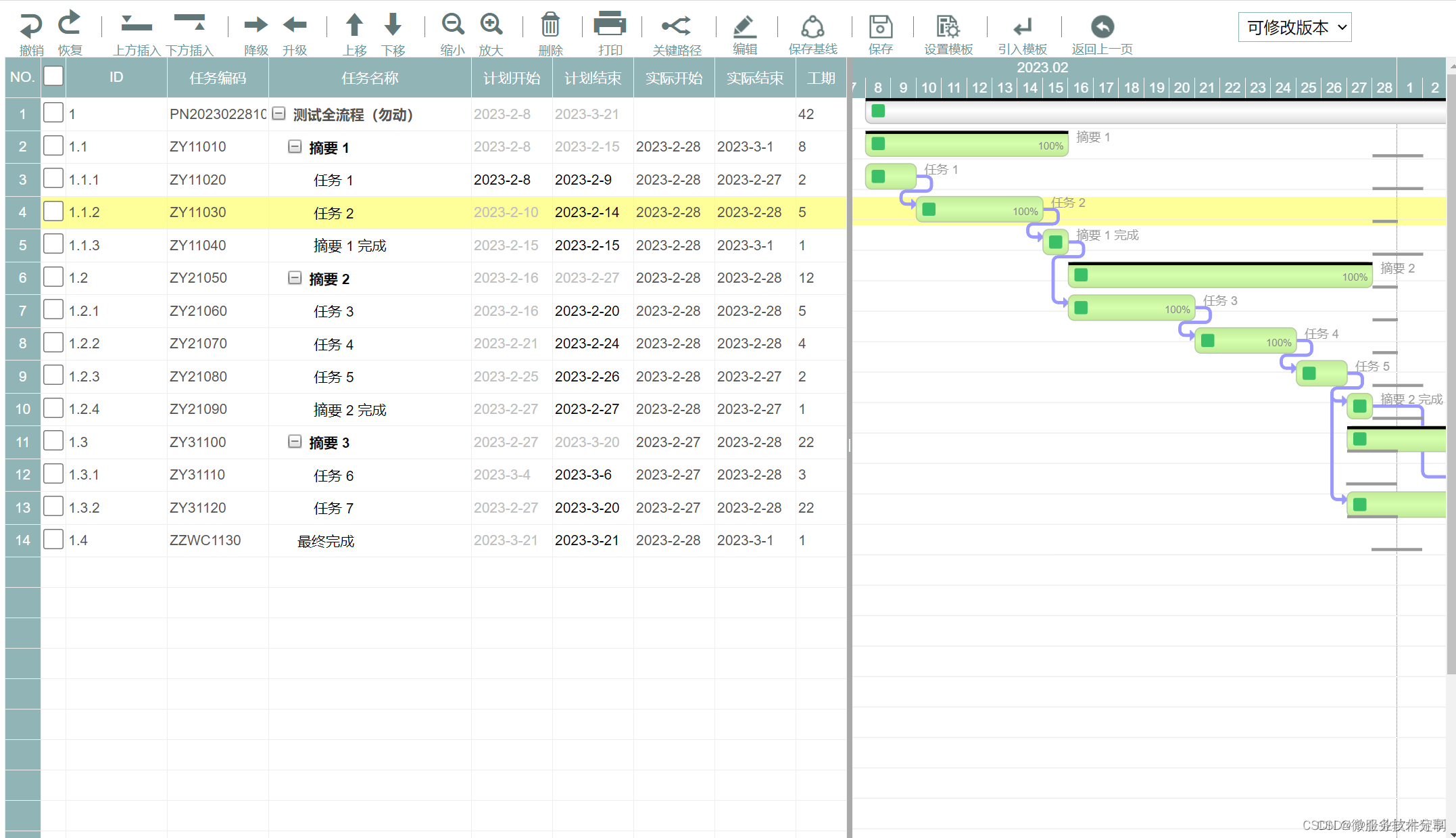
x_before<- 0:5
f_before<-c(35,40,19,3,2,1)
lambda<-mean(rep(x_before,f_before))#计算样本均值
n<-sum(f_before)#样本量x_after<-0:3
f_after<-c(f_before[1:3],f_before[4]+f_before[5]+f_before[6])#合并最后三个频数pp<-dpois(0:2,lambda)
pp[4]<-1-sum(pp)
ei<-n*pp
kafang<-sum((f_after-ei)^2/ei)#计算检验统计量kafang值
pi<-(f_after-ei)^2/ei
p<-pchisq(kafang,df=2,lower.tail = FALSE)
result<-list("理论概率"=pp,"期望频数"=ei,"卡方值"=kafang,"检验pi"=pi,"检验p值"=p)
print(result)输出结果。
$理论概率
[1] 0.3678794 0.3678794 0.1839397 0.0803014$期望频数
[1] 36.78794 36.78794 18.39397 8.03014$卡方值
[1] 0.9005665$检验pi
[1] 0.08689652 0.28045337 0.01996686 0.51324975$检验p值
[1] 0.6374476附录,
R语言生成卡方分位数表:
####卡方(chisq)分布
# 1.卡方分布中抽样函数rchisq
n = 100
df <- 10
rchisq(n, df, ncp = 0)# 2.卡方分布概率密度函数
x <- seq(0,30,0.1) # x为非负整数,表达次数。
y <- dchisq(x,df)
plot(x,y)# 3.卡方分布累积概率
x <- seq(1,20,0.1)
plot(x,dchisq(x,df=10))
# P[X ≤ x]
pchisq(5, df=10)
# P[X > x]
pchisq(5, df=10,lower.tail = FALSE)# probabilities p are given as log(p).
pchisq(5, df=10,log.p = TRUE)# 4.qchisq函数(pchisq的反函数)
# 累积概率为0.95时的x值
qchisq(0.95, df=1)
qchisq(0.95, df=10)
qchisq(0.95, df=100)
qchisq(0.95, df=2) [1] 9.374352 7.225081 4.339676 25.443502 3.618107 10.846279 9.792687 6.958344[9] 8.186593 9.308886 3.833281 13.401038 13.827963 7.114502 7.610147 9.622570[17] 9.386026 5.690467 7.747932 18.025969 12.101603 3.058159 8.716517 9.193497[25] 8.255007 10.381829 16.342552 10.650481 3.516774 11.450335 18.655177 12.566566[33] 11.375149 16.861794 2.171601 9.412595 4.987076 8.830401 15.482431 17.042475[41] 6.790693 8.589830 3.492954 9.936864 11.311470 3.983115 5.778621 11.658223[49] 7.533967 12.962804 11.029936 16.725462 6.123450 5.593923 5.783483 10.653229[57] 8.545289 7.732986 11.465535 5.679195 8.084869 22.411351 10.698811 18.658545[65] 2.346266 7.017037 6.191191 7.662195 14.175151 6.166813 18.540517 15.199404[73] 15.144126 2.831125 9.366318 12.542988 12.084843 4.535881 5.543144 4.091480[81] 11.018910 7.373405 10.465331 13.763390 8.985686 7.844968 15.414990 19.600317[89] 5.664467 11.345434 14.300911 9.378645 8.362372 5.188432 5.972438 9.457694[97] 9.774907 13.822577 5.626243 8.695835