


相关文章
Canary,三种优雅姿势绕过
Canary(金丝雀),栈溢出保护 canary保护是防止栈溢出的一种措施,其在调用函数时,在栈帧的上方放入一个随机值 ,绕过canary时首先需要泄漏这个随机值,然后再钩爪ROP链时将其作为垃圾数据写入&…

【深度学习】AudioLM音频生成模型概述及应用场景,项目实践及案例分析
AudioLM(Audio Language Model)是一种基于深度学习的音频生成模型,它使用自回归或变分自回归的方法来生成连续的音频信号。这类模型通常建立在Transformer架构或者类似的序列到序列(Seq2Seq)框架上,通过学习…
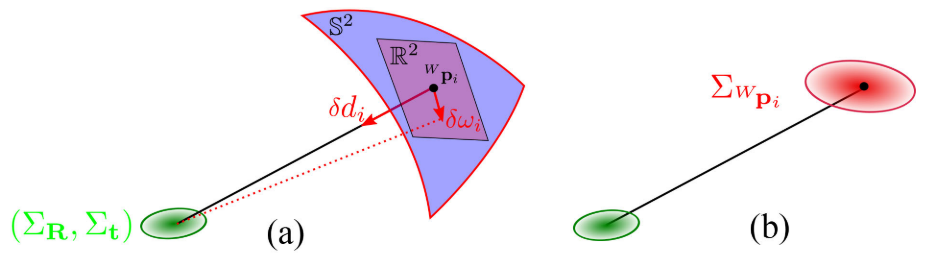
【文献解析】Voxelmap——一种自适应体素地图
Efficient and Probabilistic Adaptive Voxel Mapping for Accurate Online LiDAR Odometry 论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber9813516 代码:GitHub - hku-mars/VoxelMap: [RA-L 2022] An efficient and probabili…
基于Hadoop平台的电信客服数据的处理与分析③项目开发:搭建基于Hadoop的全分布式集群---任务10:Hive安装部署
任务描述
任务内容为安装并配置在Hadoop集群中使用Hive。
任务指导
Hive是一个基于Hadoop的数据仓库框架,在实际使用时需要将元数据存储在数据库中
具体安装步骤如下:
1. 安装MySQL数据库(已安装)
2. 解压缩Hive的压缩包
3…

【OnlyOffice】桌面应用编辑器,插件开发大赛,等你来挑战
OnlyOffice,桌面应用编辑器,最近版本已从8.0升级到了8.1 从PDF、Word、Excel、PPT等全面进行了升级。随着AI应用持续的火热,OnlyOffice也在不断推出AI相关插件。 因此,在此给大家推荐一下OnlyOffice本次的插件开发大赛。 详细信息…
【LinuxC语言】手撕Http协议之accept_request函数实现(一)
文章目录 前言accept_request函数作用accept_request实现解析方法根据不同方法进行不同操作http服务器响应格式unimplemented函数实现总结前言
在计算机网络中,HTTP协议是一种常见的应用层协议,它定义了客户端和服务器之间如何进行数据交换。在这篇文章中,我们将深入探讨Li…
Kafka 进阶指南
Kafka 进阶指南
引言
在掌握了 Kafka 的基本概念和操作后,我们可以进一步探索 Kafka 的高级特性和使用技巧,以提高其性能、可扩展性和可靠性。本指南将介绍 Kafka 的进阶主题,包括性能调优、扩展策略、数据复制、日志压缩、流处理和安全性。…
Vue的学习之数据与方法
前段期间,由于入职原因没有学习,现在已经正式入职啦,接下来继续加油学习。 一、数据与方法 文字备注已经在代码中,方便自己学习和理解 <!DOCTYPE html>
<html><head><meta charset"utf-8">&l…