1.首先将模型在Synth80k数据集上训练
Synth80k数据集是合成数据集,里面标注是使用单个字符的标注的,也就是这篇文章作者想要的标注的样子,但是大多数数据集是成堆标注的,也就是每行或者一堆字体被整体标注出来,作者想使用这部分数据集
2.对成行标注的数据集来说,先把成行的文字行切出来,然后用在Synth80k数据集上训练得到的模型推理得到Region score然后再用分水岭算法将单个字符的box给画出来,这样的话就得到了单个文字标注的数据,这部分标签被称为伪标签。
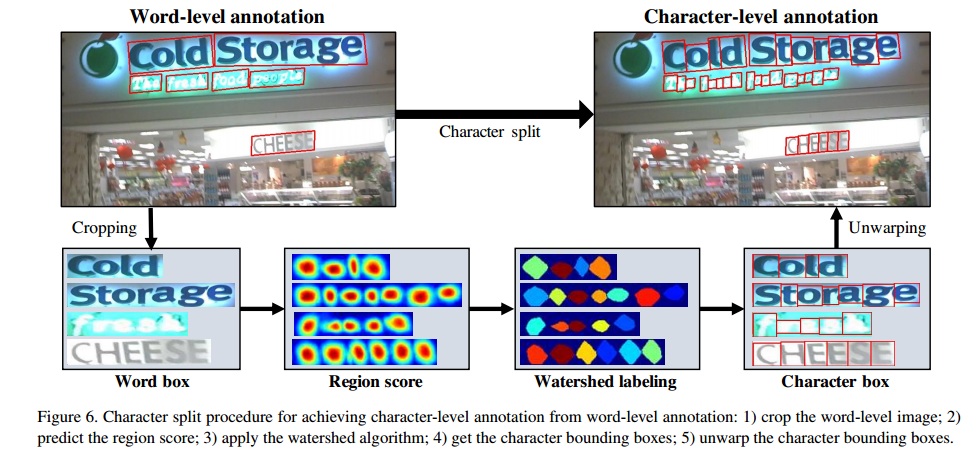
3.得到每个字符的box后,下一步就是使用这些字符框获得每个字符框对应的高斯图和两个字符之间间隙的高斯图,它们叫Region Score和Affiniy Score的GT
对于Region Score来说,只要根据字符框生成高斯图就行,这个高斯图就是Region Score的GT,如下图 细的 绿色 实线 箭头所示

对于Affiniy Score来说,对每个字符框画“对角线”,两个相邻的框四个三角形的中点为Affiniy框的四个顶点,这样就能得到Affiniy框,然后再根据Affiniy框的形状生成高斯热图,这个高斯热图就是Affiniy Score的GT,如图粗绿色实线和绿色虚线所示
4.上面得到的Region Score和Affiniy Score的GT,实际上质量是比较低的,作者使用了一些方法来约束低质量的标注
判断伪标签质量的方法就是根据一行字符框的长度和每个字符框的长度来判断这个伪标签的质量到底怎么样

作者使用置信度来评估标签的质量
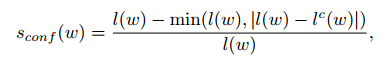
l(w):这一行字符的总长度,这个长度不是边界框的物理长度,我觉得应该是字符的个数
lc(w):这个是我们经过字符分割的过程后得到的长度,也就是得到的检测得到字符框个数
这样的话,当一行文本,我们知道这行文本里面有5个字符,然后经过分割过程,如果我们得到了4个字符框,也就是我们得到了4个字符那么这个置信度就是4/5
得到这个置信度之后就要用起来,在这个字符框内的像素置信度得分就是4/5不在的就是1

在计算损失的时候减少低置信度样本损失的权重
其中S∗r(p)和S∗a(p)分别表示GT Region Score和Affiniy Score的GT热图
这样计算之后低置信度的伪标签在损失计算中的权重就会降低,减少错误的伪标签对模型带来的坏处
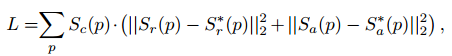
5.ok了,现在我们就可以在真实数据集上愉快进行弱监督训练了
训练完的模型的推理输出结果就是一个字符一个字符的
可以根据自己需要去合成多个字符
具体的作者的方式如下:
- 处理的方向是从左向右,黑色箭头代表处理方向
- 蓝色线是垂直于处理方向的椭圆内的最长的线,也就是说他是和中心点相交且两端到达椭圆边界的线
- 是用黄色线连接蓝色线的中心点
- 将蓝色线旋转到椭圆中心线的位置也就是椭圆的最长的位置,用红色箭头表示,注意这里的红色箭头是没有到边界的,因为椭圆的中心线是最长的
- 红色箭头的端点也就是绿色点就是文本多边形的顶点
- 最边缘的两个红色线要扩展到高斯椭圆的边界处