文章目录
- 1、Kafka如何保证消息不丢失
- 1.1 生产者发消息到Brocker丢失:设置异步发送
- 1.2 消息在Broker存储时丢失:发送确认机制
- 1.3 消费者从Brocker接收消息丢失
- 1.4 同步 + 异步组合提交偏移量
- 2、Kafka如何保证消费的顺序性
- 3、Kafka高可用机制
- 3.1 集群模式
- 3.2 分区备份机制
- 4、Kafka数据清理机制
- 4.1 数据存储
- 4.2 数据清理
- 5、Kafka实现高性能的设计
- 5.1 零拷贝
- 6、面试
1、Kafka如何保证消息不丢失
broker:经纪人

和RabbitMQ类似的分析,Kafka丢数据的可能点有:
- 生产者发消息到Brocker的过程丢消息
- 消息存Broker时丢了
- 消费者从Broker接收消息后丢了
1.1 生产者发消息到Brocker丢失:设置异步发送
异步发送,传入回调逻辑,回调逻辑中,判断发送有异常时,记录日志并重试:

配置中设置重试次数:

1.2 消息在Broker存储时丢失:发送确认机制
生产者发送消息到leader,leader需要把数据同步到follower
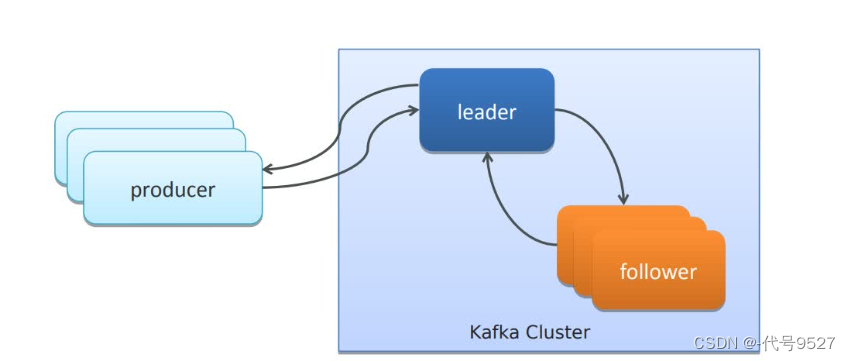
发送确认机制,即返给生产者producer一个acks,当设置acks = :
- 0:producer不等Kafka的回复,消息一扔就走。因此消息发的快,但可能丢消息
- 1:leader收到消息后,给producer一个成功的响应,告诉它消息发送成功
- all:leader、follower都收到消息后,才给producer一个成功的响应

1.3 消费者从Brocker接收消息丢失
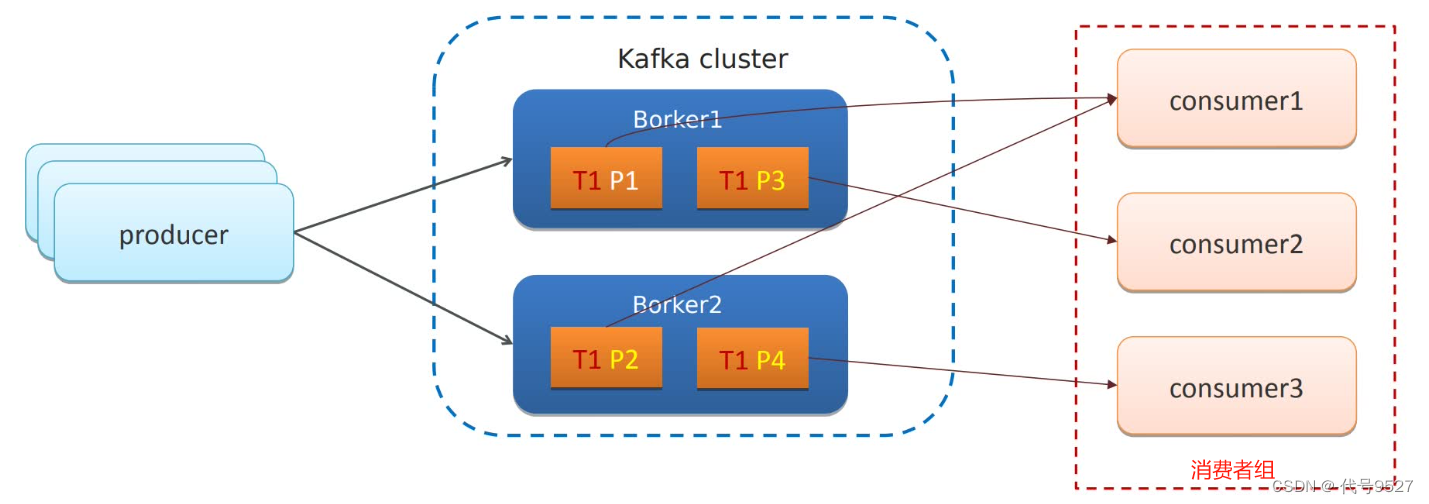
Kafka的分区机制,即一个Topic被划分成多个分区,如图,Topic1被分为P1、P2、P3、P4,且这四个分区,又在两个不同的Broker。
现有一个消费者组,里面有三个实例consume1、consume2、consume3,负责处理topic1 的消息。topic分区的消息,只能由消费者组的唯一一个消费者处理,因此,不同的分区分给了不同的消费者,如图,consume1负责P1、P2,consume2负责P3,consume3负责P4分区。
每个分区里,都是按照偏移量存储数据、消费数据(分区中的每条消息,都分配了一个序号,即偏移量,从0开始自增)。消费者默认每5秒自动提交一次已经消费的偏移量,即自己处理到哪个位置了

如上,某个消费组的实例consumer1处理P1、P2,实例consumer处理P3。假设consumer2宕机,其负责的分区分给组里的其他实例去处理,如交给了consumer1
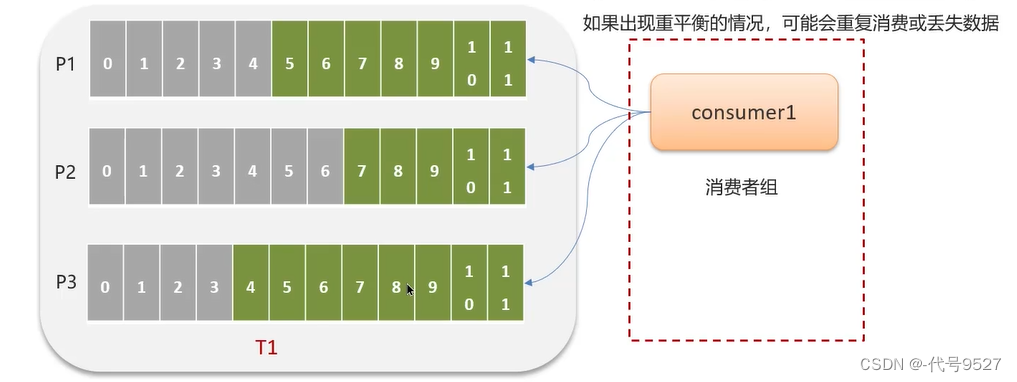
此时:
- 如果consume2消费到了偏移量3,提交的偏移量也是3,则consumer1接手后,没任何问题
- 如果consume2消费到了偏移量6,但提交的偏移量只到3(还没来得及提交),则consumer1接手后,会导致3~6偏移量的数据重复消费
- 如果consume2消费到了偏移量1,但提交的偏移量到了3(消息拿走了,但还没来得及处理),则consumer1接手后,会导致1~3的消息丢失
1.4 同步 + 异步组合提交偏移量
解决这个问题,可禁用自动提交偏移量,改为手动提交:
- 同步提交:会导致消费者在提交偏移量后阻塞,直到提交成功或失败,但偏移量准确(看重可靠性)
- 异步提交:允许消费者继续处理其他消息,而不必等待偏移量提交的确认,但偏移量可能提交失败(看重吞吐量)
- 同步 + 异步组合使用
组合使用,处理消息时使用异步提交,而在消费完后提交出现异常时(consumer.commitAsync方法异常),使用同步提交来确保最后一批消息的偏移量被正确提交。如此,可以在保证效率的同时,尽可能地保证偏移量的正确性

这样写,提交偏移量可控了,但如果消费完一条消息后,还没异步提交就断电,还是会有重复消费问题。finally里写个同步提交,可以解决异步提交时,偏移量可能提交失败(有异常)的问题,但解决不了瞬间断电宕机的问题。
再回头看瞬间断电宕机一个consumer,导致的重复消费和消息丢失问题。这么写代码,重复消费的问题还在,因此,还是要考虑幂等方案,如消费时,先判断业务ID是否存在,是则return。
但消息丢失的问题就没有了,因为现在是手动提交偏移量,不存在:消息拿走了,但还没来得及处理,偏移量就被提交了(然后宕机)的情况。现在的代码是,先处理,再提交。因此,如果最坏也就是消息被处理了,但没提交偏移量,后面的consumer接手后,还是属于重复消费问题。
2、Kafka如何保证消费的顺序性
需要顺序性的场景如:聊天,A发消息的顺序 == B收消息的顺序。Kafka,一个Topic可能有多个分区,每个分区内,是有顺序的,但整个Topic的所有分区里,无顺序。因此,要顺序,可只提供一个分区。或者说,同一个业务的数据,放同一个分区。

以上两种写法都可,第一种写法指定分区,第二种写法用key,key被hash后,分到不同的区,因此,同一个业务,用相同的key即可。
3、Kafka高可用机制
3.1 集群模式
每一个broker,就是一个Kafka实例。 多个broker实例,组成集群。挂掉一个,其余的也能处理请求。

3.2 分区备份机制
一个topic有多个分区,每个分区有多个副本,其中一个是leader,另一个是follower,且follower存储在集群的其他broker实例中。如下图,topic1的分区P0,其leader在broker1,两个follower在broker1和broker2。当leader故障,Kafka会将一个follower提升为leader,且ISR的follower优先被提升。
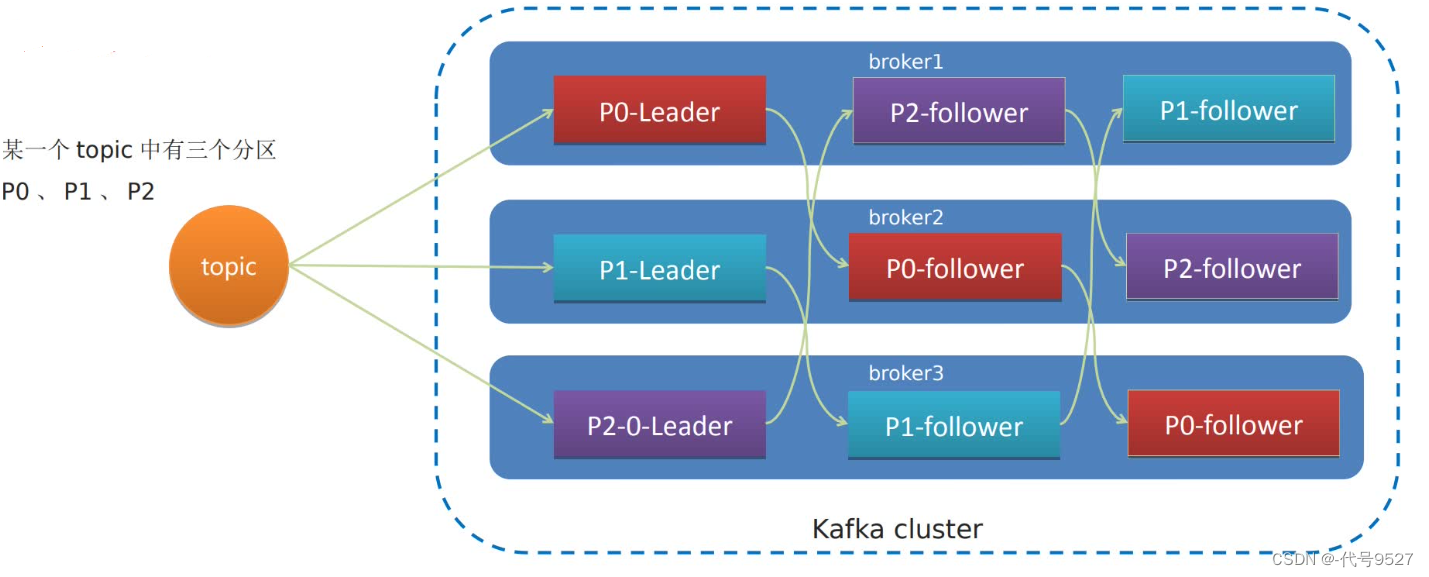
ISR,即in-sync-relica,是同步复制的follower,数据更加完整,但效率不高。普通的follower,即异步复制的,不保证完整性,但性能好。
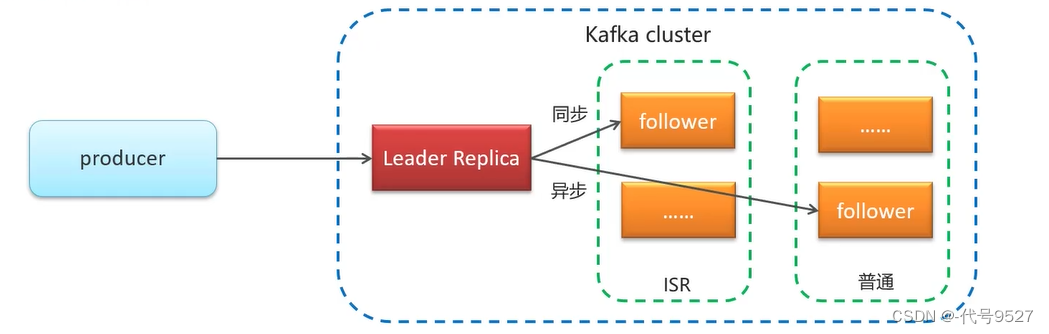
最后,关于ISR副本数的控制:

4、Kafka数据清理机制
4.1 数据存储

topic是一个逻辑概念,数据在磁盘,按照topic分区存,一个分区对应一个文件夹,如下图:

分区内部,存储了数据,且是分段存储,segment,每一段,对应三个文件,.index索引文件、.log真正的数据文件、.timeindex时间索引文件。采取分段,而不是将所有数据都放到一个文件,是因为分段后:
- 删除已被消费的无用分段文件更方便
- 查找数据更便捷(文件名是以偏移量命名的)
都放一个文件,不分段,则不管是删除还是查找都很烦。
4.2 数据清理
清理策略1:消息保存时间超过了指定时间,默认168h即7天。

清理策略2:当topic所有分区的文件总和,所占的文件大小超过配置的阈值,开始删除最久的消息。需手动开启。

5、Kafka实现高性能的设计
- 消息分区:一个topic分成多个part,在不同的broker节点上。不再受单台服务器的限制,可以不受限的处理更多的数据
- 顺序读写:磁盘顺序读写,而不是随机磁盘寻道,提升读写效率
- 页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。第二次读相同数据时,直接走页缓存,写时,先写到页缓存,再刷回磁盘。

- 零拷贝:减少上下文切换及数据拷贝
- 消息压缩:Kafka提供了多种数据压缩算法,东西变小了,从而减少磁盘IO和网络IO,但同时压缩也会额外损耗CPU资源
- 分批发送:将多个消息打包批量发送,减少网络开销,默认16KB一发,如果指定时间内,不到16KB,也会发,以防消息积压
5.1 零拷贝
现在有一个producer需要发送消息,过程为:从用户空间(权限小,无法直接调用硬件资源磁盘)拷贝到内核空间的页缓存,到一定批次后,将数据写进磁盘。

再来一个consumer消费消息,过程为:用户空间的Kafka先在页缓存找有没这个消息,没找到则去磁盘,并拷贝到内核空间的页缓存,再拷贝到用户空间。想要把消息发送给消费者,就要用到socket连接和网卡,因此接下来是,数据从用户空间拷贝到内核空间的Socket缓冲区,再拷贝到网卡,然后发出去,经历了4次拷贝

而Kafka的零拷贝,即磁盘 copy到 页缓存,页缓存直接copy到网卡,只要两次拷贝。Kafka知道哪个消费者要消费消息,因此,把整个操作委托给系统,不再经过用户空间。

6、面试






![【YOLOv8改进[CONV]】轻量级架构AKConv助力YOLOv8目标检测效果 + 含全部代码和详细修改方式 + 手撕结构图 + 有效涨点](/images/no-images.jpg)