文章目录
- 一、说明
- 二、受试者“间”因素和受试者“内”因素的意思?
- 三、混合模型方差分析回答 3 件事
- 四、混合模型方差分析的假设
一、说明
在本文中,我将讨论一种称为混合模型方差分析的方差分析变体,也称为具有重复测量的 2 因素方差分析。这种统计方法用于分析包括受试者间因素(不同组)和受试者内因素(对同一受试者的重复测量)的数据。
二、受试者“间”因素和受试者“内”因素的意思?

受试者间因素和受试者内因素
假设我们想测试不同的教学方法(A、B 和 C)是否会影响学生的表现。我们对 15 名参与者进行研究,每组随机分配 5 名参与者(每组一种教学方法)。这种设置体现了主题之间的因素。
“受试者间因素”表示研究中的每个参与者只被分配到一组,并且每组经历不同的情况。
在此分析中,我们的目标是确定各组之间的平均性能水平是否存在显着差异,这正是单因素方差分析旨在实现的目标。如果您需要更多详细信息,可以参考我之前的文章,位于“参考资料”部分。
但是,我们可以探索一种教学方法在多个时间点对每个科目的影响,例如:
- 在应用教学方法之前(预测试)
- 教学期过半
- 应用教学方法后(后测)
这个过程代表了受试者内因素
此过程表示主题内因素。因此,在混合模型方差分析中,我们至少有一个受试者内因子和一个受试者间因子。
三、混合模型方差分析回答 3 件事
受试者内因素效应:它确定受试者内因素(前测、中测、后测等时间点)是否对因变量(学生表现)有显着影响。
受试者间因素效应:它评估了学科间因素(不同的教学方法)是否对因变量有显着影响。
交互作用:它检查了受试者内和受试者之间的因素之间是否存在显着的交互作用。
设置假设
在混合模型方差分析中,通常有三个假设
1/ 受试者内因素(时间)的主效应
原假设 (H0): 不同测量时间点的平均值没有显著差异。
备择假设 (H1):不同测量时间点的平均值存在显著差异。
2/ 学科间因素的主要影响(教学方法)
原假设 (H0):不同教学方法组的平均值没有显著差异。
备择假设 (H1): 不同教学方法组的平均值存在显著差异。
3/ 互动效果(教学方法*时间):
原假设 (H0):教学方法对绩效的影响不会随时间而改变(没有相互作用)。
备择假设 (H1): 教学方法对绩效的影响会随着时间而变化(存在交互作用)。
四、混合模型方差分析的假设
1 常态:因变量应近似正态分布在受试者间因子的每一组中。
2 独立:观察结果是独立的。
3 方差的同质性:因变量的方差在受试者间因子的不同组中应该是相等的(我们可以使用 Levene 检验来检查假设,您可以在 参考资料 部分阅读我关于它的文章
4 无显著异常值:数据不应包含显著的异常值,因为它们会不成比例地影响分析结果。
5 协方差的同质性:对于受试者内因素(时间),相关组的所有组合之间的差异方差应相等。(可以使用 Mauchly 的球形度测试进行测试,以后可以调整)
关于协方差的同质性的注意事项:在我们的例子中,我们有 3 个组。
第一组之间的差异。
第二组的差异,第一组和第三组的差异。
第二组和第三组之间的差值应具有相同的方差。
1/ 数据 :让我们计算一下前面的例子。我将利用 Numpy 生成随机数据。
import pandas as pd
import numpy as np
from pingouin import mixed_anovanp.random.seed(0)n = 15time_points = ['T1', 'T2', 'T3']data = pd.DataFrame({'Participant': np.repeat(range(1, n+1), len(time_points)),'Teaching_Method': np.repeat(['A', 'B', 'C'], n),'Time': np.tile(time_points, n),'Score': np.random.randint(50, 100, size=n*len(time_points))
})data.head()
2/ 假设:
A/ 正态性 : 现在,我们需要验证这些假设。我将首先使用 Shapiro-Wilk 检验检查正态性
注意:
- 原假设 (H0) 是数据服从正态分布。
- 如果 p 值大于所选的显著性水平,则我们无法否定原假设。这表明没有重要证据可以得出数据偏离正态分布的结论。
from scipy.stats import shapirofor method, group_data in data.groupby('Teaching_Method')['Score']:stat, p = shapiro(group_data)print(f'Shapiro-Wilk test for {method}: p-value = {p}')# Shapiro-Wilk test for A: p-value = 0.3026245223583117
# Shapiro-Wilk test for B: p-value = 0.5795532845153779
# Shapiro-Wilk test for C: p-value = 0.7610549007614936
由于在所有教学方法的 Shapiro-Wilk 检验中,所有 p 值都大于 0.05(我使用的显著性水平),这表明没有明显证据表明偏离正态性。因此,满足正态性假设。
B/ 方差的同质性:为了评估方差的同质性,我将采用 Levene 检验。
from scipy.stats import levenestat, p = levene(*[group_data for method, group_data in data.groupby('Teaching_Method')['Score']])
print(f'Levene\'s test for homogeneity of variances: p-value = {p}')
# Levene's test for homogeneity of variances: p-value = 0.8937735564168452
注意:
Levene检验中的原假设(H0)是被比较组的方差相等。
由于 Levene 检验的 p 值为 0.89(大于显著性水平),因此我们无法否定原假设,表明没有显着证据表明教学方法组之间的方差存在显着差异。
C/ 协方差的齐质性:如前所述,我们可以利用 Mauchly 测试来实现此目的。
from pingouin import sphericitysphericity_test = sphericity(data, dv='Score', subject='Participant', within='Time')print(sphericity_test)
# SpherResults(spher=True, W=0.9298475348159647, chi2=0.9455504153256469, dof=2, pval=0.6232701617877808)
注意:
- 原假设 (H0) 是所有可能的受试者内条件对之间的差异方差相等。
“spher=True” 参数表示满足球形度的假设。此外,当观察 p 值(大于 alpha)时,有大量证据拒绝球形度的假设。
D/ 异常值 :我们可以采用Tukey的方法(Tukey的栅栏,Tukey的规则),它涉及以下步骤:
计算数据的四分位距 (IQR),即第三个四分位数 (Q3) 和第一个四分位数 (Q1) 之间的差值。您也可以在“参考资料”部分参考我关于它的文章。
将下围栏 (LF) 定义为 Q1–1.5 * IQR,将上围栏 (UF) 定义为 Q3 + 1.5 * IQR。任何低于下围栏或高于上围栏的数据点都被视为潜在的异常值。
注意: 对于异常值数显著的阈值,没有一般规则,因为它可能取决于多个因素。
import seaborn as sns
import matplotlib.pyplot as pltQ1 = data['Score'].quantile(0.25)
Q3 = data['Score'].quantile(0.75)
IQR = Q3 - Q1lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQRoutliers = data[(data['Score'] < lower_bound) | (data['Score'] > upper_bound)]print("Outliers:")
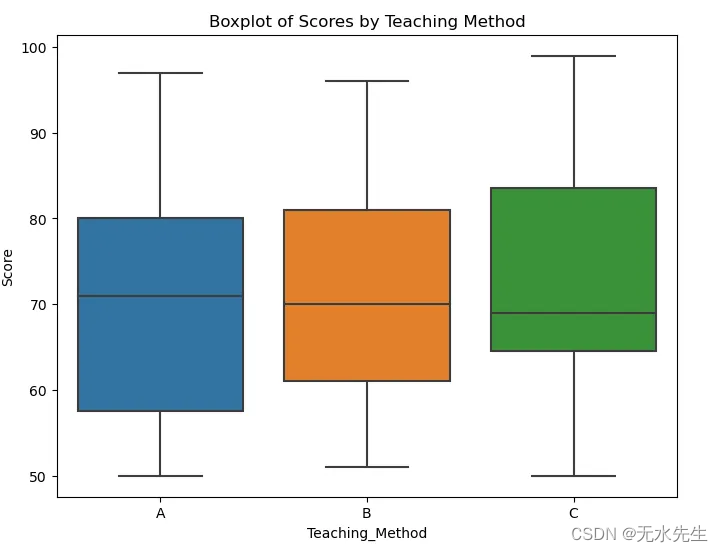
print(outliers)plt.figure(figsize=(8, 6))
sns.boxplot(x='Teaching_Method', y='Score', data=data)
plt.title('Boxplot of Scores by Teaching Method')
plt.show()# Outliers:
# Empty DataFrame
# Columns: [Participant, Teaching_Method, Time, Score]
# Index: []
3/ 让我们运行测试: 现在我们已经确认满足了假设,我们可以继续进行测试。
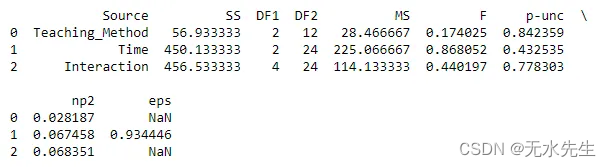
anova = mixed_anova(dv='Score', within='Time', between='Teaching_Method', subject='Participant', data=data)print(anova)
让我们分析每个假设:
1/ 时间的主要影响:由于 p 值 (0.432535) 大于 0.05,我们无法否定原假设。这意味着没有重要证据表明时间对分数有重大影响。
2/ 教学方法的主要效果:同样,由于 p 值 (0.842359) 大于 0.05,我们无法否定原假设。没有重要证据表明教学方法对分数有显着影响。
3/ 交互效果:同样,由于 p 值 (0.778303) 大于 0.05,我们无法否定原假设。没有显著的证据表明教学方法和时间对分数之间存在交互作用。
注意:
效应大小 (ηp²) 和 Epsilon (ε) :
效应大小(ηp²)值较小,表明自变量解释的方差比例相对较低。
Epsilon (ε) 提供有关可能违反球形的信息。然而,由于我们已经用 Mauchly 检验证实了球形度,因此 epsilon 值在这里是补充的。
如果您希望我们涵盖特定主题,请随时告诉我!您的意见将有助于塑造我的内容的方向,并确保它保持相关性和吸引力