1. 评测工作
在大模型微调和RAG工作都在进行的同时,我们搭建了一套评测数据集。这套数据集有山东大学周易研究中心背书。主要考察大模型对于易学基本概念与常识的理解与掌握能力。
1.1. 构建评测集
在周易研究中心的指导下,我们构建出了一套用以考察大模型对易学基本概念的掌握能力的数据集。
这套数据集是纯手工制作的,没有用之前之前的自动语料生成技术。因为我们要确保评测集100%的正确性和权威性。因此手写了170个四选一的单选题,配有分类与正确答案,让大模型进行回答。
怎么评估大模型在这个评测数据集上的性能?
我们对回答结果与正确结果进行比对,评估大模型的能力(准确来说,是Solve Rate,问题解决率)。其中,Solve Rate计算公式如下:
这里,SR是Solve Rate,分子是解决的问题数(也即大模型给出的答案能和正确答案对的上的问题数),分母是问题总数。
评测数据集的结构
评测数据集的一行的结构如下所示:

其中:
- A列:一个有关周易(易学)的问题,有且仅有一个明确的答案。
- B~E列:这个问题的4个选项,分别对应A\B\C\D。其中有且仅有一个正确答案。
- F列:这个问题的正确答案。
- G列:该问题的分类
共170行,对应170个问题。
1.2. 构建测试过程
我们打算与目前现有的大模型对比,进行基准(baseline)测试。由于评测数据集和测试脚本完成编写后,我们微调的大模型还没有能够集成到服务器上。因此一开始我只跑了三个大模型:
在这个实验中,我们想探究知识库对于会给大模型的能力带来多少提升。我这里就以这个基准测试举例了,重点介绍这个Baseline Test的Working Pipeline。(后续,我们会加入经过结构化文本构成的数据集微调的大模型,并有带/不带知识库两种类型,另外还可以加入国内外已有通用大模型,例如文心一言、ChatGPT等)。
配置测试环境
这里我通过一个json文件对基线测试的环境进行配置。
{"sources": ["./source/test_data.xlsx"],"targets": ["./target/target1"],"prompt": {"one_out_of_four": "我现在有一个关于周易的问题,是一个四选一选择题,请你帮我回答。题目是:{question},选项是:{options},答案是:(请你回答)。请直接回答,不要解释。"},"test_args": {"origin_llm_kb": {"url": "http://zy.tessky.top/chat/knowledge_base_chat","top_k": 20,"score_threshold": 1.00,"llm_models": ["chatglm3-6b", "zhipu-api", "openai-api"],"prompt_name": ["default","text","empty"],"knowledge_base_name": "faiss_zhouyi","temperature": 0.7},"zhipu_ai": {"api_key": "you should never know this,my dear friends,use your own api keys","model": "glm-4"}}
}- sources:由于我们可能有多份评测数据集,所以是一个评测集文件的路径的数组
- targets:每个评测集文件基线测试的目标文件(保存每一个问题的评测结果的json文件)的路径数组
- prompt:不同评测集对应的prompt模板,比如我是四选一任务。
- test_args:不同大模型的参数,这个要根据具体情况配置了。
测试过程
我构建测试过程如下:
1. 首先,初始化所有将要进行基线测试的大模型的实例到一个dict中。(后面我会说这个实例如何构建)例如这里就是带知识库的chatglm3-6b和chatglm-4(zhipu_ai)。
def init_models(configuration: json) -> dict[str, chat_interface]:m = {}# ours:带知识库但是不带微调大模型的olk = origin_llm_kb()m['origin_llm_kb'] = olk# zhipuai:glm-4zpa = zhipu_ai(configuration)m['zhipu_ai'] = zpareturn m其中,其中key是在config/batch_evaluation.json中test_args中配置的key(我们要用这个key反解析配置文件中的大模型对话时的参数)。
2. 随后,遍历配置文件中的每一个评测集(当然我们这个例子中目前就还只有一个)。
for i in range(len(srcs)):src = srcs[i]target = targets[i]3. 再后,对之前初始化好的dict做kv对遍历,调用其中每个实例的处理评测数据集并进行大模型对话的方法,对当前评测集,返回一个List[dict],也即字典的数组:
for chat, handler in chats.items():print(f"{chat} evaluating {src} ......")dicts = handler.deal_one_out_of_four_xlsx(src, config)
4. 最后将这个字典的数组转为json,保存到目标json文件中
with open(os.path.join(target, f"{chat}.json"), 'w', encoding='utf-8') as tf:json_str = json.dumps(dicts, ensure_ascii=False, indent=4)tf.write(json_str)print(f"{chat} evaluated {src}")os.system('cls')大模型对话实例构建
测试过程搭好了一个通用的框架,因为对于每一个大模型,他都要跑这套流程去做评测。但是剩下的部分就是每个大模型自己的工作了(请求大模型对话的接口往往不同)。不过其中还是有一些公共的部分的,也就是处理excel表格的部分。
抽象基类处理excel表格
因此我选择了建立一个抽象基类,把请求大模型进行对话的部分封装为一个抽象方法,让后面的子类去实现,而处理excel表格的公共部分,就在抽象基类中实现。形成代码的继承复用。
import json
from abc import ABC, abstractmethod
from typing import List, Union
from openpyxl import load_workbookclass chat_interface(ABC):@abstractmethoddef request_chat(self, query: str, config: json) -> Union[dict, json]:pass# 针对4选1的xlsxdef deal_one_out_of_four_xlsx(self, path: str, config: json) -> List[dict]:wb = load_workbook(filename=path)shs = wb.sheetnamesres = []for sh in shs:ws = wb[sh]try:index = 1for row in ws.iter_rows(min_row=1, values_only=True):# row 是一个元组,包含了当前行的所有数据question = row[0]options = [f'A:{row[1]}', f'B:{row[2]}', f'C:{row[3]}', f'D:{row[4]}']answer = row[5]question_type = row[6]query = config["prompt"]["one_out_of_four"].format(question=question, options=options)response = self.request_chat(query=query, config=config)print(f'{index}.{query}')print(response)res.append({"question": question,"options": options,"correct_answer": answer,"type": question_type,"kb_answer": response["answer"],})index += 1except Exception as e:print(f'迭代处理excel表格时发生异常:{e}')return resreturn res
- 这里的request_chat就是交给后续继承这个抽象基类的子类实现的抽象方法,用来请求大模型对话。
- deal_one_out_of_four_xlsx是处理四选一excel表格的公共逻辑:
- 首先通过openpyxl库打开.xlsx文件
- 随后遍历每张worksheet
- 开启sheet的迭代器,遍历每一行,根据上述每行的结构,取出:
- 问题
- 选项数组
- 正确答案
- 类型
- 随后,构建prompt模板,调用request_chat进行询问。
- 将结果封装为dict,添加到字典的数组中
- 返回该数组
子类实现
之后,我们只需要为不同大模型编写一个request_chat的接口就可以。
1. 对于我们自己搭建的服务器上的chatglm3-6b的大模型,之前我写过请求的方式,详情请见于:创新实训2024.05.28日志:记忆化机制、基于MTPE与CoT技术的混合LLM对话机制-CSDN博客
这里我直接说request_chat方法的实现:
class origin_llm_kb(chat_interface):def request_chat(self, query: str, config: json) -> Union[dict, json]:args = config["test_args"]["origin_llm_kb"]request_body = {"query": query,"knowledge_base_name": args["knowledge_base_name"],"top_k": args["top_k"],"score_threshold": args["score_threshold"],"model_name": args["llm_models"][0],"temperature": args["temperature"],"prompt_name": args["prompt_name"][0],}try:response = requests.post(url=args["url"], headers={"Content-Type": "application/json"}, json=request_body)except Exception as e:response = '{\'answer\':\'发生异常' + str(e) + '\'}'return json.loads(response.text[response.text.find('{'):response.text.rfind('}') + 1])这里的请求体的各个参数全部都是之前提到的配置文件中配置好的。
我们服务器的接口返回的大模型的回答是一个json格式的字符串,因此只需要找到最外围括号,然后把json字符串反解析成json对象即可返回。(在python中,dict和json对象是可以通用的,所以不用担心转不成dict)
2. 对于智谱清言的chatglm4,可以查阅它的官方文档,在之前的一篇博客中:创新实训2024.04.11日志:self-instruct生成指令_self instruct 中的seed是什么-CSDN博客
我已经提到过如何使用chatglm-4进行大模型对话请求,这里不再赘述:
class zhipu_ai(chat_interface):def __init__(self, config: json):args = config['test_args']['zhipu_ai']self.client = ZhipuAI(api_key=args['api_key'])self.model = args['model']def request_chat(self, query: str, config: json) -> Union[dict, json]:try:response = self.client.chat.completions.create(model=self.model,messages=[{"role": "user","content": query}])except Exception as e:response = '{\'answer\':\'发生异常' + str(e) + '\'}'return responsereturn {"answer": response.choices[0].message.content}由于请求智谱AI需要一个客户端,因此在类实例创建时,我们先给他注入一个客户端,省的每次request_chat都得重新注入开销太大。
测试结果
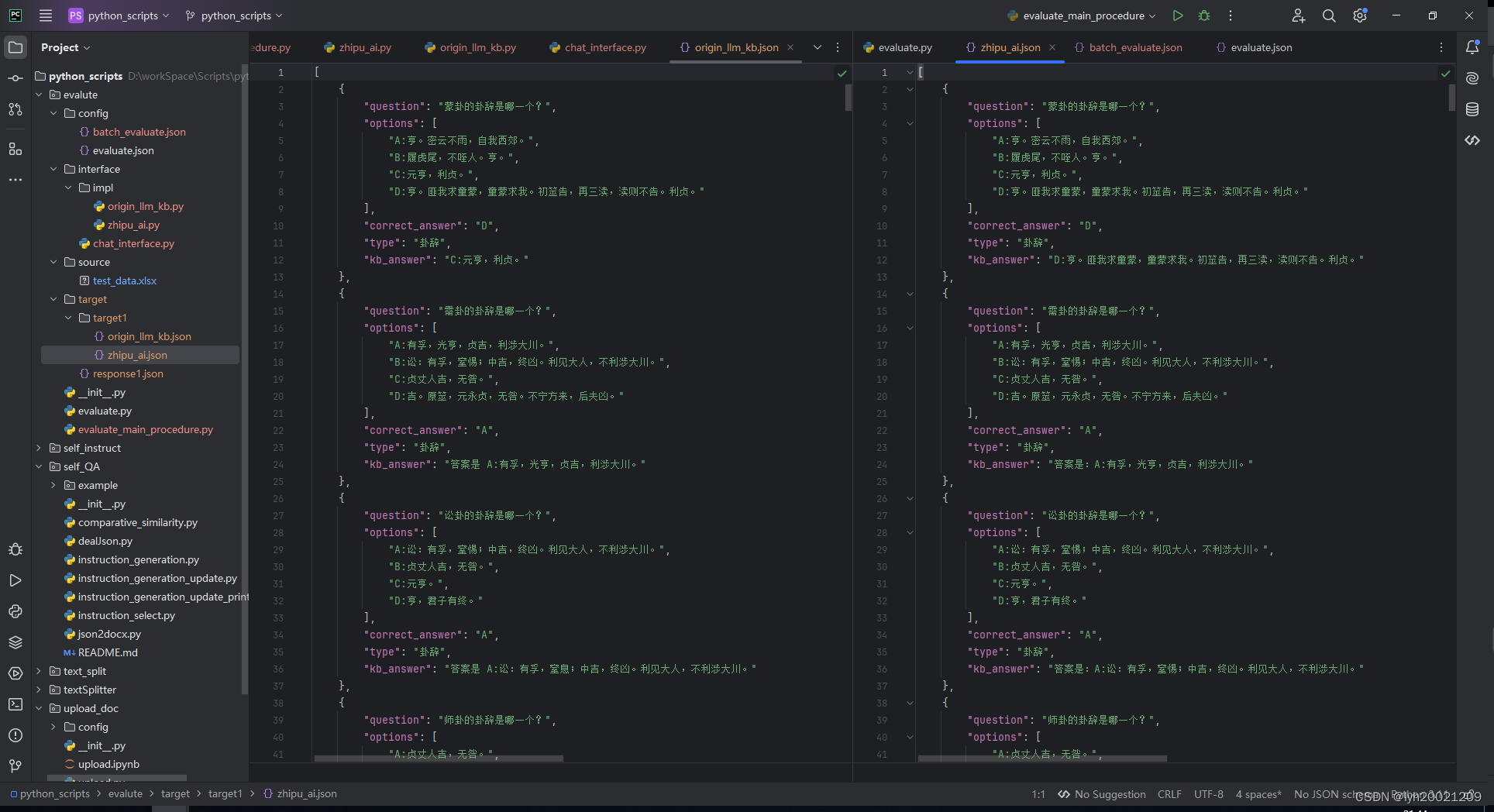
可以看到,两个大模型分别将他们的回答写到了json文件中。
2. 性能评估
有了测试结果,我们就能根据之前的公式(1)进行性能评估了。首先我们要做一个统计,也就是json文件中每个json对象里的大模型的回答是否和正确答案一致。这一部分的实现由另一个队友完成,具体见于:
创新实训-结果统计-CSDN博客
实际结果如下:
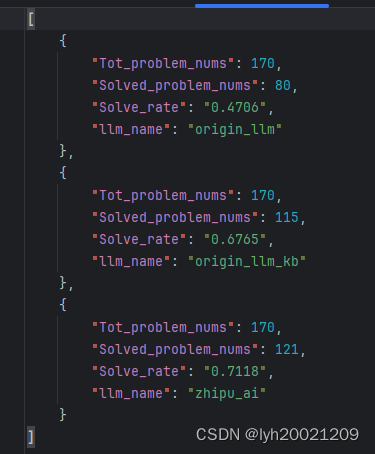
其中,origin_llm和origin_llm_kb分别是不带知识库和带知识库的初始大模型chatglm3-6b的正确率,而zhipu_ai是智谱AI目前提供接口的chatglm4-14b的回答。
而带知识库的回答中,还有一个大模型没有明确说选项,但是回答对了的:
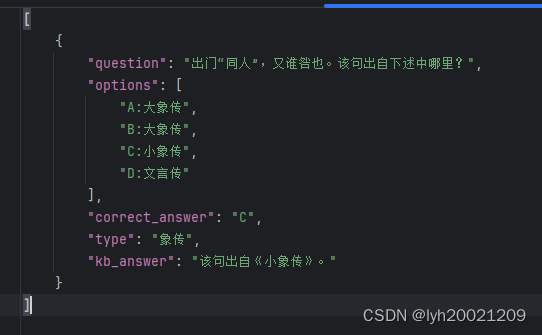
因此实际上带知识库的glm3-6b的回答正确的个数是116个。
| llm | 是否微调 | 是否带知识库 | 回答正确数量 | 问题总数 | Solve Rate |
| glm3-6b | × | × | 80 | 170 | 47.06% |
| glm3-6b | × | √ | 116 | 170 | 68.23% |
| glm4-14b | × | × | 121 | 170 | 71.18% |
可以看到,RAG技术为大模型的生成回答的准确性带来了巨大的提升。从80到116,共计提升了
的准确性 。
后续,我们将继续将微调后的大模型部署到服务器,再跑一遍这个基线测试,生成更加完成的结果。