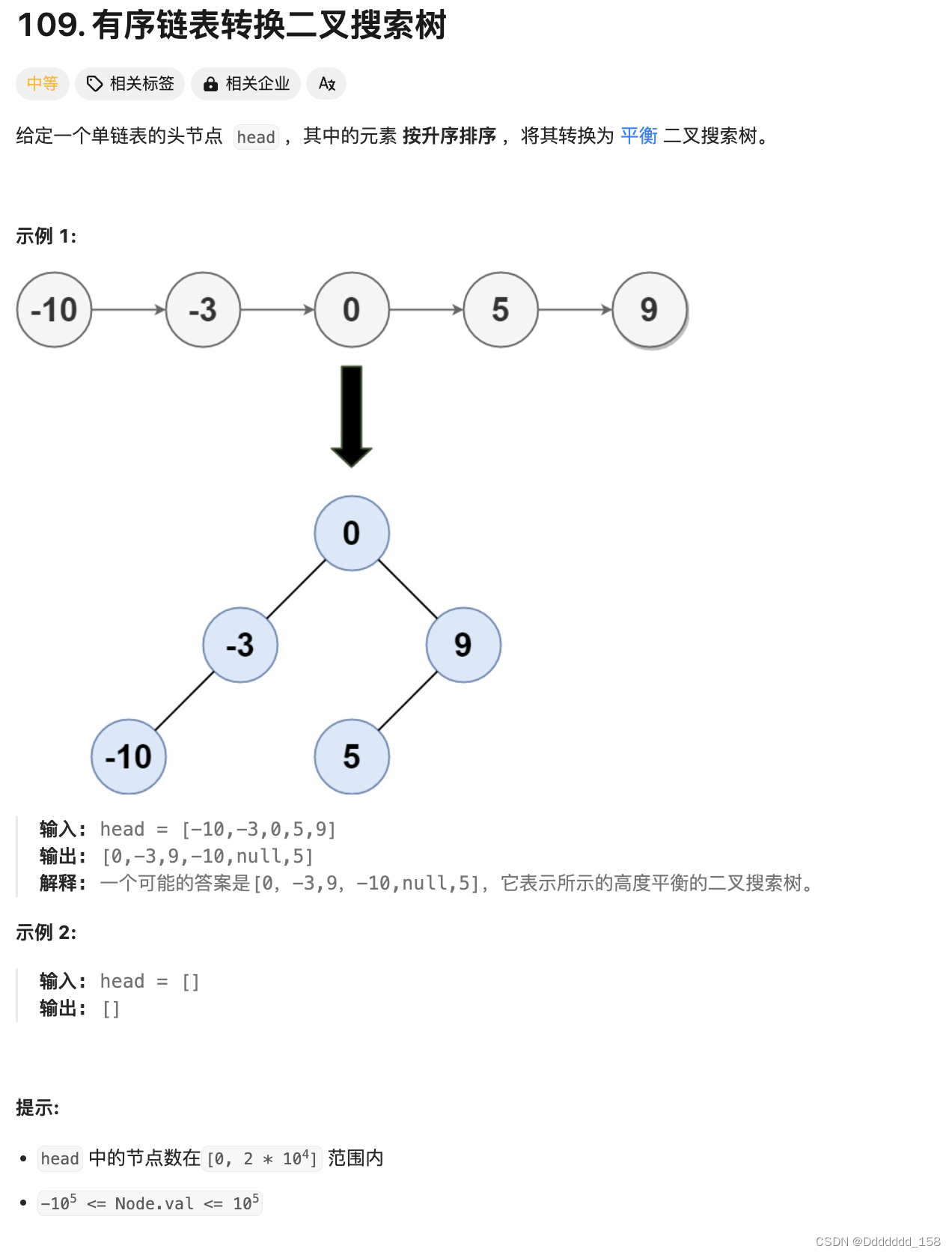
问题背景
Hive主要设计为一个用于大数据集的批处理查询引擎,并不是为实时查询或实时数据更新而设计的。它主要用于执行数据摘要、查询和分析。因此,Hive本身不支持实时数据更新或实时查询,它更适合用于对大量数据进行批量处理和分析。
分析
如果你需要实时更新数据,可能需要考虑其他技术或框架,比如Apache HBase、Apache Storm、Apache Flink或Apache Kafka等。这些技术可以更好地支持实时数据处理的需求。
- Apache HBase:是一个高可靠性、高性能、面向列的、可伸缩的分布式存储系统,适用于存储大规模的稀疏数据集。HBase支持对数据的实时读写。
- Apache Kafka:是一个分布式流处理平台,它能够让你以高吞吐量的方式处理实时数据流。
- Apache Storm:是一个实时大数据处理框架,用于实时计算。Storm可以用于实时分析、在线机器学习、连续计算、分布式RPC等场景。
- Apache Flink:是一个分布式流处理框架,它提供了数据流的分布式处理能力,可以用于实时数据处理和分析。
如果你的应用场景确实需要在Hive中处理实时数据,可以考虑将Hive与这些实时处理技术结合使用,例如,使用Apache Kafka来收集实时数据,然后使用Apache Storm、Apache Flink或其他实时处理框架处理数据,并将处理结果存储到Hive中进行进一步的批量分析。这样可以结合利用Hive的批处理能力和其他技术的实时处理能力。
hive_16">结合Hbase和hive
结合HBase和Hive使用可以让你在Hive中进行复杂的批量分析和查询,同时利用HBase提供的实时读写能力。这种结合使用的方案通常适用于需要同时处理在线事务处理(OLTP)和在线分析处理(OLAP)的场景。下面是一个大致的流程:
-
在HBase中创建表
首先,在HBase中创建一个表,这个表将用于存储你的实时数据。HBase是一个分布式的、可扩展的、面向列的存储系统,非常适合用来处理大量的实时数据。
create 'your_hbase_table', 'column_family' -
在Hive中创建外部表
接下来,在Hive中创建一个外部表,这个外部表链接到你在HBase中创建的表。这样做可以让你在Hive中直接查询HBase表中的数据。
CREATE EXTERNAL TABLE hive_table_name(key int, column1 string, column2 string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,column_family:column1,column_family:column2") TBLPROPERTIES("hbase.table.name" = "your_hbase_table");这里,STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’ 指定了Hive使用HBase的存储处理器,hbase.columns.mapping 指定了HBase表中列族和列的映射。
-
使用HBase进行实时数据处理
通过使用HBase的API或者其他工具来对HBase表进行实时数据的插入、更新和查询操作。HBase非常适合处理大量的随机、实时的读/写访问。
-
使用Hive进行数据分析
由于Hive表是链接到HBase表的,你可以直接在Hive中对HBase表中的数据进行查询和分析。Hive提供了SQL-like的查询语言(HiveQL),可以让你执行复杂的数据分析和处理任务。
SELECT * FROM hive_table_name WHERE key = some_value; -
维护和优化
- 数据同步:确保HBase和Hive之间的数据同步,虽然Hive表直接链接到HBase表,但是在某些情况下可能需要考虑数据一致性和同步的问题。
- 性能优化:根据查询的需要,可能需要在HBase中设计合理的行键、列族和列,以及在Hive中进行适当的索引和分区,以优化查询性能。
数据同步问题
在结合使用HBase和Hive时,可能存在的“数据同步”问题主要涉及以下几个方面:
- 数据一致性
- 实时性:HBase支持实时数据更新,这意味着数据可以随时被插入、更新或删除。而Hive查询通常用于批处理和分析,可能不会立即反映HBase中的最新数据变更。因此,使用Hive查询HBase表时,可能会遇到数据一致性问题,即Hive查询的结果可能不是最新的数据状态。
- 数据可见性:在某些情况下,HBase中的数据更新(如插入或删除操作)可能需要一段时间才能在Hive查询中可见,这取决于Hive和HBase之间的集成方式以及数据存储的配置。
- 元数据同步
- 表结构变更:如果你更改了HBase表的结构(例如,添加或删除列),则需要在Hive中相应地更新外部表的定义,以确保Hive查询能正确理解HBase表的结构。这种表结构的变更需要手动在Hive中进行同步更新。
- 表和列映射:在Hive中创建外部表时,需要定义HBase表的列映射。如果HBase表的列族或列发生变化,Hive中的映射也需要相应更新,以保持查询的准确性。
- 性能和优化
- 数据访问模式:HBase和Hive的数据访问模式不同。HBase优化了随机读写操作,适合实时数据处理;而Hive更适合批量数据处理和分析。在使用Hive查询HBase数据时,需要考虑查询性能,可能需要对HBase的数据模型或Hive查询进行优化,以提高查询效率。
- 数据存储和索引:在HBase中,合理设计行键和使用列族可以优化数据存储和访问性能。在Hive中,可能需要使用分区、索引等特性来优化查询性能。这些优化措施需要根据实际的数据访问模式和查询需求来设计和调整。
总结
结合HBase和Hive使用,可以让你充分利用HBase的实时数据处理能力和Hive的强大数据分析能力,适用于需要同时处理OLTP和OLAP的场景。但是在实际应用中,需要根据具体的业务需求和数据特性,合理设计和调整数据架构,以确保HBase和Hive的有效集成和使用。