LlaMA 3 系列博客
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (五)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (六)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (七)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (八)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(一)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(二)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(三)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(四)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(五)
你好 GPT-4o!
大模型标记器之Tokenizer可视化(GPT-4o)
大模型标记器 Tokenizer之Byte Pair Encoding (BPE) 算法详解与示例
大模型标记器 Tokenizer之Byte Pair Encoding (BPE)源码分析
大模型之自注意力机制Self-Attention(一)
大模型之自注意力机制Self-Attention(二)
大模型之自注意力机制Self-Attention(三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (一)


Code Llama 是 Llama2 的改进版本,专门用于协助与代码相关的任务,例如编写、测试、解释或完成代码段。集成在 Huggingface Transformer框架中,使用 Code Llama 非常简单。
本文将深入探讨设置 Code Llama 和利用提示来实现预期结果的实际方面。
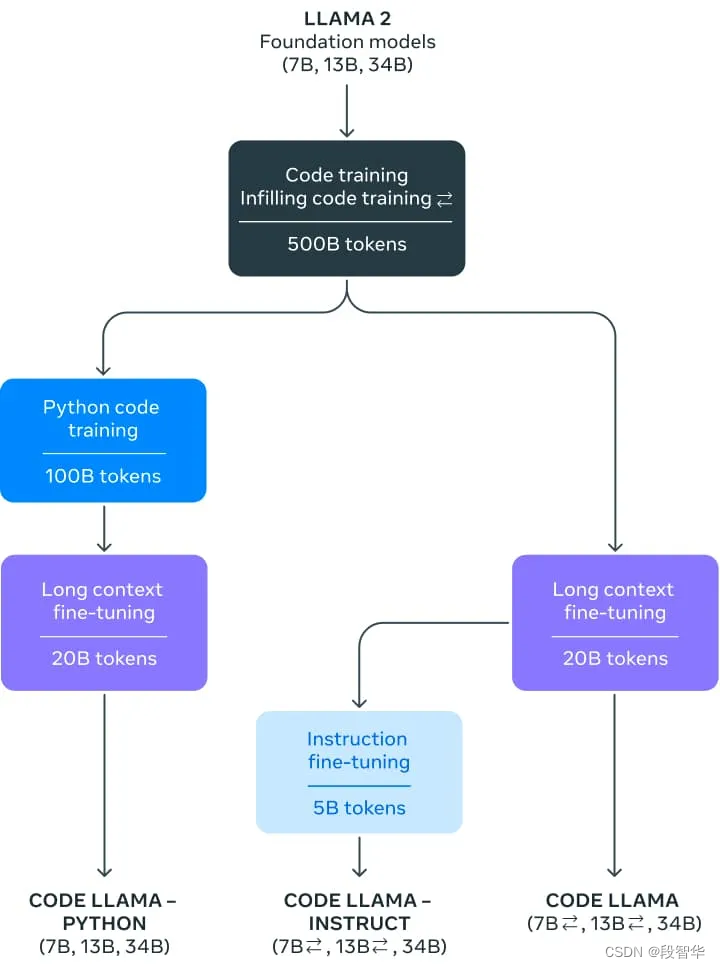
本质上,Code Llama 是 Llama 2 的迭代,在包含 5000 亿个代码数据标记的庞大数据集上进行训练,以创建两种不同的风格:Python 专家(1000 亿个额外标记)和指令微调版本,其中能够理解自然语言指令。
该模型提供各种权重类别,包括 7、13 或 340 亿个参数,以满足不同的用例。
-
Code Llama 支持多种编程语言,包括 Python、C++、Java、PHP、C#、Typescript 和 Bash。
-
Code Llama 在 16k 上下文窗口上进行训练。此外,这三个模型变体还进行了额外的长上下文微调,使它们能够管理最多 100,000 个标记的上下文窗口。
-
由于 RoPE 扩展的最新发展,将 Llama 2 的 4k 上下文窗口增加到 Code Llama 的 16k(可以推断到 100k)是可能的。社区发现 Llama 的位置嵌入可以线性插值或在频域中插值,这可以通过微调轻松过渡到更大的上下文窗口。在 Code Llama 的情况下,频域缩放是通过松弛完成的:微调长度是缩放的预训练长度的一小部分,从而赋予模型强大的外推能力。
从transformers4.33 开始,可以使用 Code Llama 并利用 HF 生态系统中的所有工具,例如:
- 训练和推理脚本和示例
- 安全文件格式 ( safetensors)
- bitsandbytes 与(4 位量化)和 PEFT(参数高效微调)等工具集成
- 使用模型运行生成的实用程序和助手
- 导出模型以进行部署的机制
关于数据类型的注释
使用 Code Llama 等模型时,查看模型的数据类型非常重要。
-
32 位浮点 ( float32):PyTorch 关于模型初始化的约定是加载模型float32,无论模型权重以何种精度存储。transformers为了与 PyTorch 保持一致,也遵循此约定。
-
16 位 Brain 浮点 ( bfloat16):Code Llama 已以此精度进行训练,因此我们建议使用它进行进一步训练或微调。
-
16 位浮点 ( float16):建议使用此精度运行推理,因为它通常比 bfloat16更快,并且评估指标相对于 bfloat16没有明显的退化 。
如上所述,transformers使用加载权重float32(无论模型存储的精度如何),因此dtype在加载模型时指定所需的权重非常重要。如果您想微调 Code Llama,建议使用bfloat16,因为使用float16可能会导致溢出和 NaN。如果运行推理,建议使用float16,因为bfloat16可能会更慢。
使用示例
7B 和 13B 模型可用于文本/代码补全或填充。以下代码片段使用该pipeline界面来演示文本完成。只要您选择 GPU 运行时,它就可以在 Colab 的免费层上运行。
from transformers import AutoTokenizer
import transformers
import torchtokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline("text-generation",model="codellama/CodeLlama-7b-hf",torch_dtype=torch.float16,device_map="auto",
)sequences = pipeline('def fibonacci(',do_sample=True,temperature=0.2,top_p=0.9,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,max_length=100,
)
for seq in sequences:print(f"Result: {seq['generated_text']}")运行结果为:
Result: def fibonacci(n):if n == 0:return 0elif n == 1:return 1else:return fibonacci(n-1) + fibonacci(n-2)def fibonacci_memo(n, memo={}):if n == 0:return 0elif n == 1:returnCode Llama 专门研究代码理解,但它本身就是一种语言模型。您可以使用相同的生成策略来自动完成注释或一般文本。
代码填充
这是特定于代码模型的专门任务。该模型经过训练,可以生成与现有前缀和后缀最匹配的代码(包括注释)。这是代码助理通常使用的策略:要求他们填充当前光标位置,并考虑其前后出现的内容。
此任务在7B 和 13B 型号的基本版本和指令版本中可用。它不适用于任何 34B 型号或 Python 版本。
要成功使用此功能,您需要密切注意用于训练此任务模型的格式,因为它使用特殊的分隔符来识别提示的不同部分。幸运的是,TransformersCodeLlamaTokenizer使这变得非常容易,如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torchmodel_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.float16
).to("cuda")prompt = '''def remove_non_ascii(s: str) -> str:""" <FILL_ME>return result
'''input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
output = model.generate(input_ids,max_new_tokens=200,
)
output = output[0].to("cpu")filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
print(prompt.replace("<FILL_ME>", filling))输出结果
def remove_non_ascii(s: str) -> str:""" Remove non-ASCII characters from a string.Args:s: The string to remove non-ASCII characters from.Returns:The string with non-ASCII characters removed."""result = ""for c in s:if ord(c) < 128:result += creturn result评估
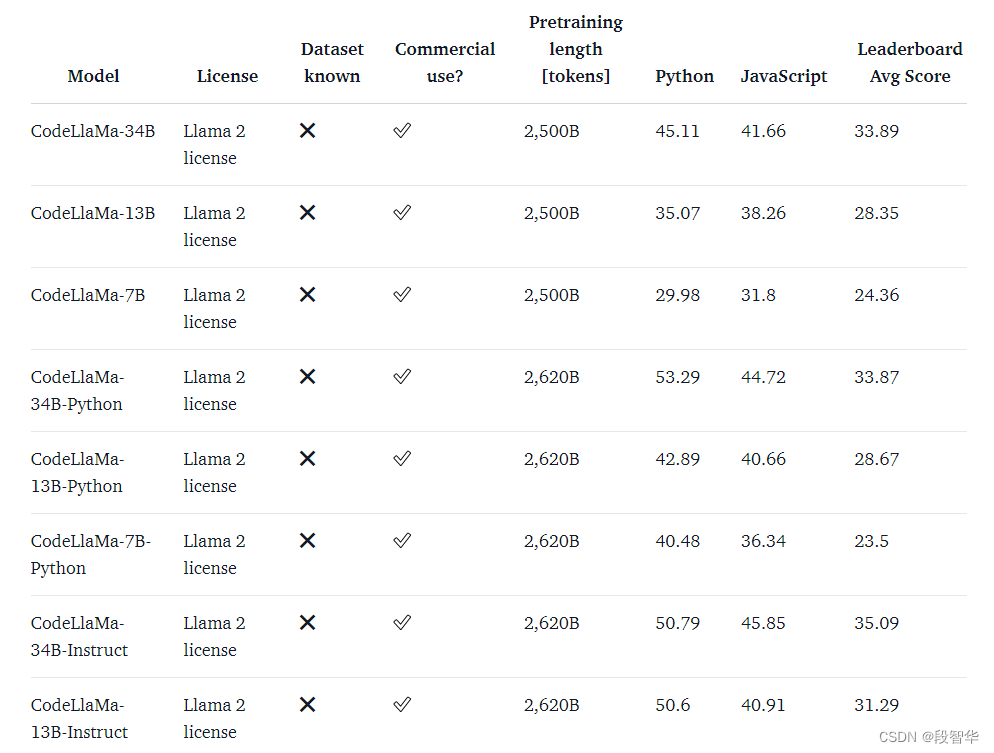
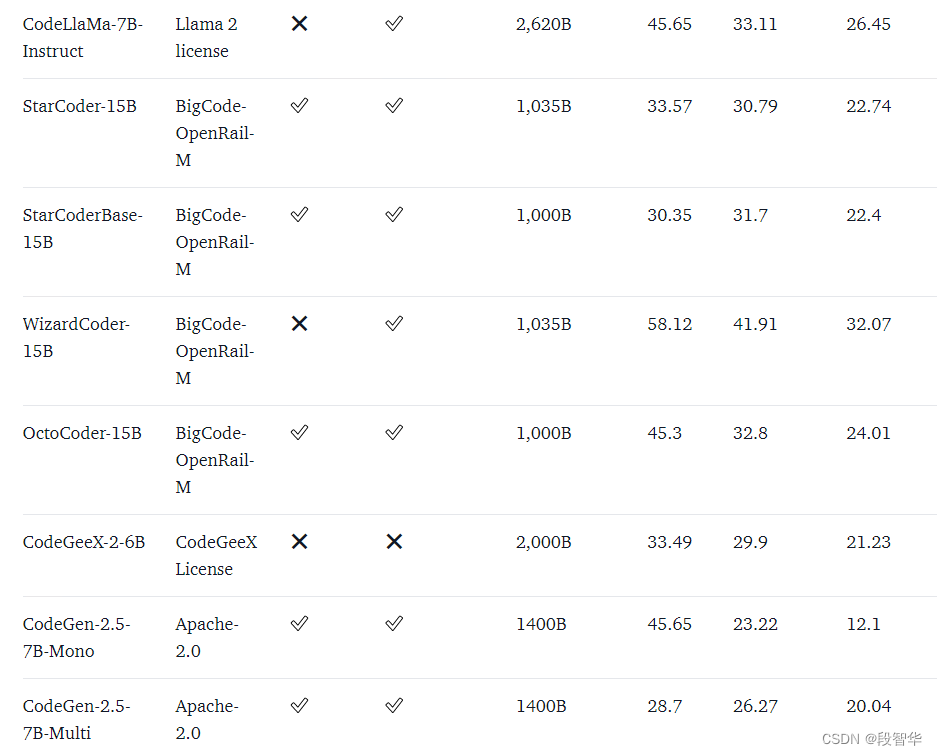
代码的语言模型通常在 HumanEval 等数据集上进行基准测试。它由编程挑战组成,其中模型带有函数签名和文档字符串,并负责完成函数体。然后通过运行一组预定义的单元测试来验证所提出的解决方案。最后,报告通过率,描述有多少解决方案通过了所有测试。 pass@1 率描述了模型在一次尝试时生成通过解决方案的频率,而 pass@10 描述了从 10 个提议的候选方案中至少有一个解决方案通过的频率。
虽然 HumanEval 是一个 Python 基准测试,但我们已经付出了巨大努力将其转换为更多编程语言,从而实现更全面的评估。其中一种方法是MultiPL-E,它将 HumanEval 翻译成十多种语言。我们正在基于它托管一个多语言代码排行榜,以便社区可以比较不同语言的模型,以评估哪种模型最适合他们的用例。
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。

![虚拟化技术[1]之服务器虚拟化](https://img-blog.csdnimg.cn/direct/ea6fe95ceaa94b96aa65f3d4e2681b97.png)