2.7.3 快慢指针问题
无法高效获取长度,无法根据偏移快速访问元素,是链表的两个劣势。然而我们经常碰见诸如获取倒数第k个元素,获取中间位置的元素,判断链表是否存在环,判断环的长度等和长度与位置有关的问题。这些问题都可以通过灵活运用双指针来解决。
代码随想录:142.环形链表II
- 链表的中间结点
-
示例:
-
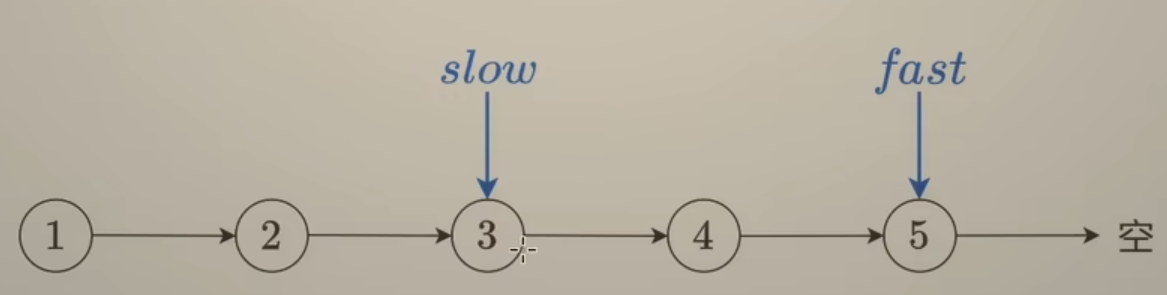
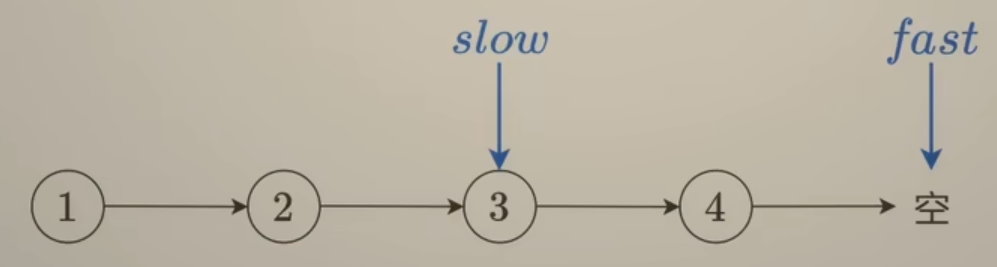
解题方法:快慢指针,定义一个快指针
fast每次执行走两步,定义一个慢指针slow每次走一步,当fast下一步为空或已经为空时,此时slow所指结点就是要找的中间结点. -
如图两种情况
-
代码:(⭐️重要模板)
//不带头结点的情况 LNode* middleNode(LNode *head) {LNode *fast = head, *slow = head;while(fast && fast -> next) {fast = fast -> next -> next;slow = slow -> next;}return slow; } //如果是带头结点的话将快慢指针修改为 fast = slow = head -> next即可; -
时空复杂度: O ( n ) / O ( 1 ) O(n)/O(1) O(n)/O(1)


扩展题:如果题目要2095. 删除链表的中间节点,那么可以设置一个pre指针一直保持在slow指针的前面一位,找到后执行删除结点操作就可以啦,代码如下:
//不带头结点
ListNode* deleteMiddle(ListNode* head) {if(head -> next == NULL) return NULL;ListNode *fast = head, *slow = head, *pre = head;while(fast && fast -> next) {pre = slow;slow = slow -> next;fast = fast -> next -> next;}pre -> next = slow -> next;delete(slow);return head;
}
- 环形链表
-
题目:给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
-
解题思路:设置快慢指针;快慢指针的特性 —— 每轮移动之后两者的距离会加一。当一个链表有环时,快慢指针都会陷入环中进行无限次移动,然后变成了追及问题。想象一下在操场跑步的场景,只要一直跑下去,快的总会追上慢的。当两个指针都进入环后,每轮移动使得慢指针到快指针的距离增加一,同时快指针到慢指针的距离也减少一,只要一直移动下去,快指针总会追上慢指针。
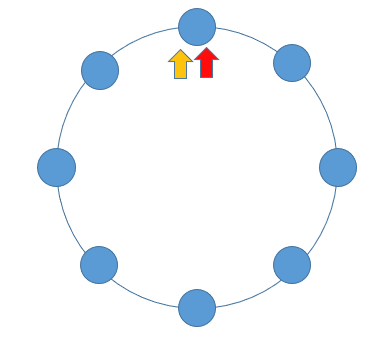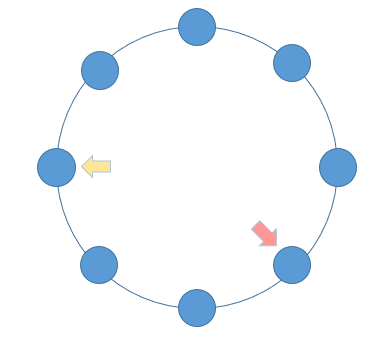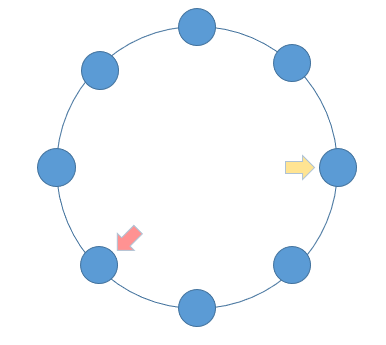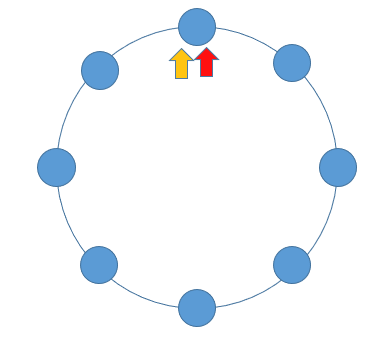
bool hascycle(LNode *head) {LNode *fast = head, *slow = head;while(fast && fast -> next) {fast = fast -> next -> next;slow = slow -> next;if(fast = slow) {return true;}}return false; }
- 环形链表 II
-
题目:给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。不允许修改 链表。
-
解题思路:如下图,设置快慢指针,当二者相遇后,再让头结点指针和慢指针同步向后移动,当二者相遇时,此时第二个相遇点就是环的入口处;证明如下:
-
代码:
//不带头结点的版本: LNode* detectCycle(LNode *head) { //head即链表的第一个结点LNode *fast = head, *slow = head;while(fast && fast -> next) {fast = fast -> next -> next;slow = slow -> next;if(fast == slow) { //第一次快慢指针相遇点;while(head != slow) { //如果头指针和慢指针相遇,说明此时二者都到了环的入口处;head = head -> next;slow = slow -> next;}return slow;}}return NULL; }//带头结点的版本; LNode* detectCycle(LNode *head) { //此时head指向链表的头结点,数据域为空LNode *fast = head -> next, *slow = head -> next;while(fast && fast -> next) {fast = fast -> next -> next;slow = slow -> next;if(fast == slow) { //第一次快慢指针相遇点;LNode * p = head -> next;while(p != slow) { //如果p指针和慢指针相遇,说明此时二者都到了环的入口处;p = p -> next;slow = slow -> next;}return slow;}}return NULL; }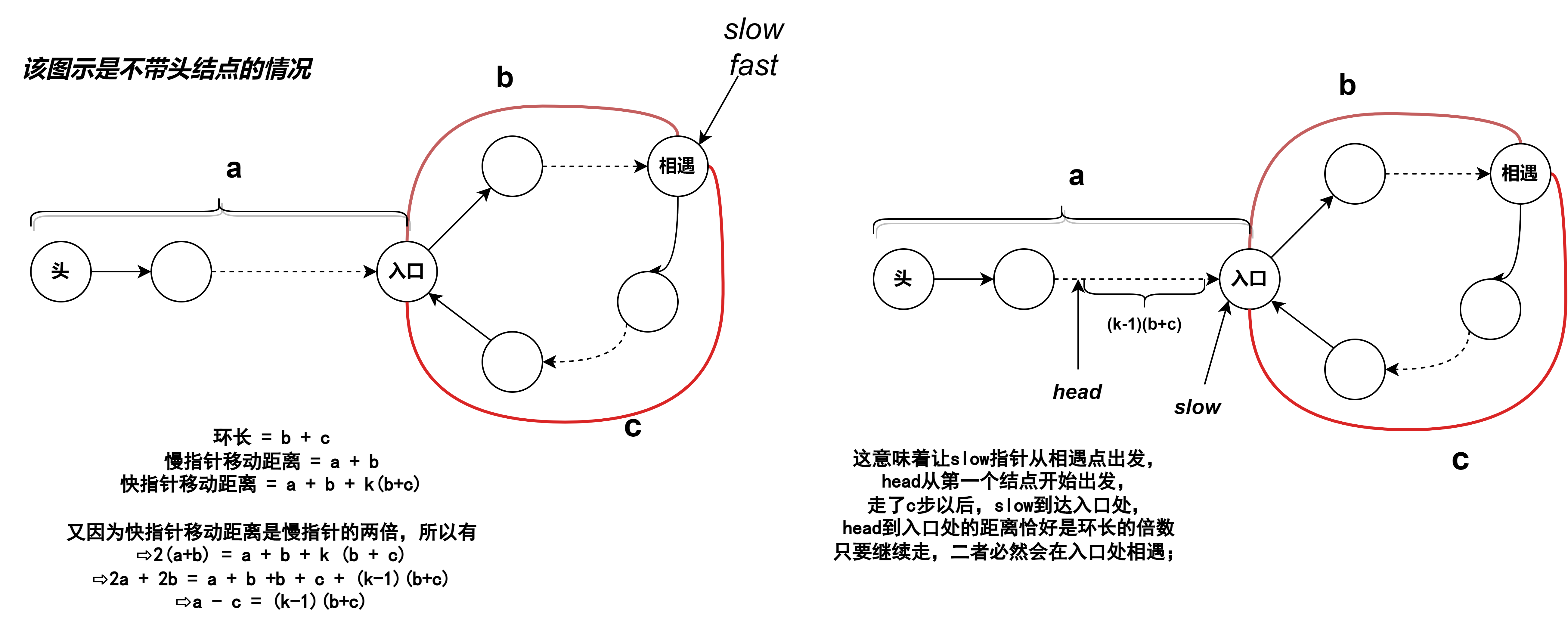
快慢指针相遇时,为什么慢指针的移动距离小于环长?:考虑最坏的情况,慢指针进入环时,快指针刚好在它前面一位,因为二者的相对速度差为1,因此快指针需要走(环长-1)次二者相遇,其他情况快指针需要走的次数都比这种情况需要走的少,即慢指针走的次数也一定比(环长-1)少,因此慢指针移动距离一定小于环长.
力扣评论区解释:为何慢指针第一圈走不完一定会和快指针相遇: 首先,第一步,快指针先进入环 第二步:当慢指针刚到达环的入口时,快指针此时在环中的某个位置(也可能此时相遇) 第三步:设此时快指针和慢指针距离为x,若在第二步相遇,则x = 0; 第四步:设环的周长为n,那么看成快指针追赶慢指针,需要追赶n-x; 第五步:快指针每次都追赶慢指针1个单位,设慢指针速度1/s,快指针2/s,那么追赶需要(n-x)s 第六步:在n-x秒内,慢指针走了n-x单位,因为x>=0,则慢指针走的路程小于等于n,即走不完一圈就和快指针相遇
- 环形链表扩展题,求解环的长度
-
解题思路:当快慢指针相遇时,继续移动,因为二者的相对速度差为1,因此到了第二次相遇时,两次相遇之间的移动次数就是环的长度;如果继续扩展的话,求整个链表的结点数的话,需要用上题的思路统计head指针移动到环的入口处移动的次数+环长即可(注意入环处的结点不要重复计数);
//不带头结点版本; int LengthCycle(LNode *head) {LNode *fast = head, *slow = head;while(fast && fast -> next) {fast = fast -> next -> next;slow = slow -> next;if(fast = slow) { //第一次相遇fast = fast -> next -> next;slow = slow -> next;int length = 1;while(fast != slow) { fast = fast -> next -> next;slow = slow -> next; length ++;}return length; //第二次相遇,跳出循环;}} }求解整个环形链表的结点数代码略,思路已给;
- 真题: 重排链表
-
题目描述:给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln - 1 → Ln请将其重新排列后变为:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
-
解题方法:本题考察了快慢指针找中间结点/链表的原地逆置(反转链表)/链表的交叉连接三个重要手法,题目不难但是代码量大,对基础要求高;
class Solution {ListNode *middleNode(ListNode *head) { //求中间结点;ListNode* slow = head, *fast = head;while(fast && fast -> next) {fast = fast -> next -> next;slow = slow -> next;}return slow;}ListNode *reverseList(ListNode* head) { //将链表的后半段原地逆置ListNode *pre = NULL, *cur = head;while(cur) {ListNode* next = cur -> next;cur -> next = pre;pre = cur;cur = next;}return pre;}public:void reorderList(ListNode* head) { //交叉链接ListNode *middle = middleNode(head);ListNode *head2 = reverseList(middle);while(head2 -> next) {ListNode * next = head -> next; //保存后继结点,为了后面更新结点做准备ListNode *next2 = head2 -> next; //保存后继结点head -> next = head2;head2 -> next =next;head = next;head2 = next2;}} };- 时间复杂度: O ( n ) O(n) O(n),其中 n n n为链表节点个数。
- 空间复杂度: O ( 1 ) O(1) O(1),仅用到若干额外变量。
-
本题也有暴力解版本,把链表放进数组中,然后通过双指针法,一前一后,来遍历数组,构造链表。
class Solution { public:void reorderList(ListNode* head) {vector<ListNode*> vec;ListNode* cur = head;if (cur == nullptr) return;while(cur != nullptr) {vec.push_back(cur);cur = cur->next;}cur = head;int i = 1;int j = vec.size() - 1; // i j为之前前后的双指针int count = 0; // 计数,偶数去后面,奇数取前面while (i <= j) {if (count % 2 == 0) {cur->next = vec[j];j--;} else {cur->next = vec[i];i++;}cur = cur->next;count++;}if (vec.size() % 2 == 0) { // 如果是偶数,还要多处理中间的一个cur->next = vec[i];cur = cur->next;}cur->next = nullptr; // 注意结尾} };
- 回文链表
-
题目描述:给你一个单链表的头节点
head,请你判断该链表是否为回文链表。如果是,返回true;否则,返回false。 -
示例:
 ,返回true;
,返回true; ,返回
,返回false; -
解题思路:跟上题一样,先用快慢指针找到中间结点,然后将后半段逆置,再设置一个指针指向第一个结点,让它和指向中间结点的指针同时同速向表尾方向移动,边移动边比较节点值是否相等,若不相等则跳出循环返回
false,若一直遍历结束都没有跳出循环,说明该链表是回文链表. -
注意后半段反转以后是这样的,也可以将链表断连一分为二,然后比较,但是只是单纯判断链表是否回文的话我觉得没有必要,我这样处理的话可以比较到中间结点结束即
p == middle时结束,但是注意当链表为[1,2]这种情况的话会出错,即有特殊情况要处理,所以不妨直接比较到p为NULL时结束。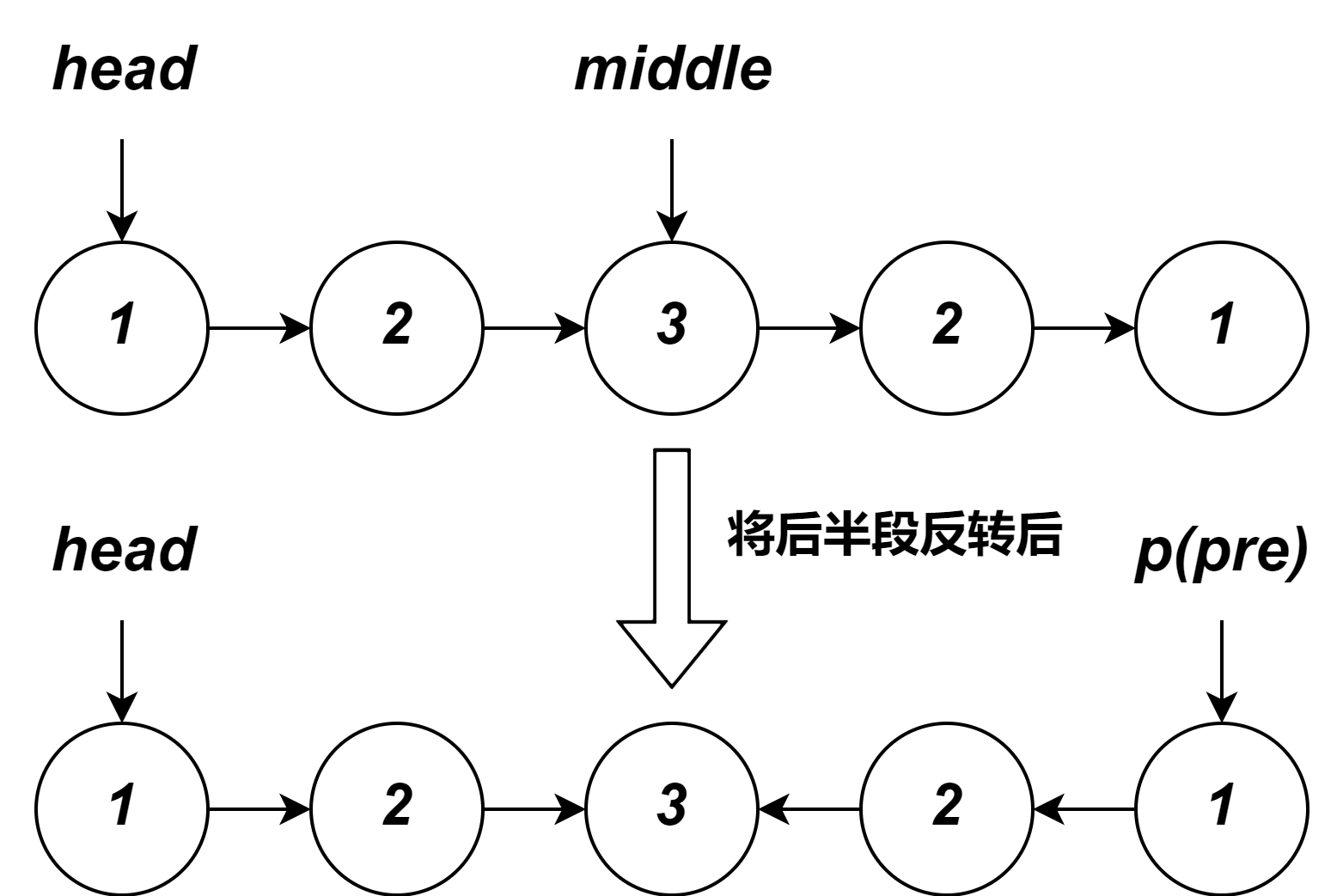
class Solution {ListNode *middleNode(ListNode *head) { //求中间结点模板;ListNode* slow = head, *fast = head;while(fast && fast -> next) {fast = fast -> next -> next;slow = slow -> next;}return slow;}ListNode *reverseList(ListNode* head) { //反转链表模板ListNode *pre = NULL, *cur = head;while(cur) {ListNode* next = cur -> next;cur -> next = pre;pre = cur;cur = next;}return pre;}public:bool isPalindrome(ListNode* head) {ListNode* middle = middleNode(head); //求中间结点;ListNode* p = reverseList(middle); //将链表后半段逆置while(p){ //下面开始依次比较节点值是否相等;if(p -> val != head ->val ){return false;}p = p -> next;head = head -> next;}return true;} };时空复杂度: O ( n ) / O ( 1 ) O(n)/O(1) O(n)/O(1)
-
其他方法:
-
由于数组具有随机访问的性质,可以考虑复制链表结点数值到数组中,然后用双指针法判断是否为回文链表;
class Solution { public:bool isPalindrome(ListNode* head) {vector<int> vals;while (head != NULL) {vals.push_back(head->val);head = head->next;}for (int i = 0, int j = vals.size() - 1; i < j; ++i, --j) {if (vals[i] != vals[j]) {return false;}}return true;} }; -
可以考虑用栈来做,将该链表所有结点值遍历输入到栈中,再依次弹出和链表元素比较;因为是回文所以链表反过来和正过来一模一样,用stack做很方便
class Solution {public boolean isPalindrome(ListNode head) {Stack<Integer> stack=new Stack<Integer>();ListNode cur=head;while(cur!=null){stack.push(cur.val);cur=cur.next;}while(head!=null){if(stack.pop()!=head.val)return false;head=head.next;}return true;} } //但是注意空间复杂度不符合O(1)的要求;
2.7.4 链表的排序问题
- 排序链表
给你链表的头结点
head,请将其按 升序 排列并返回 排序后的链表 。-
暴力方法:将链表中的值全部存入数组,再将其排序,最后创建一个新链表按顺序将其用尾插法插入新链表即可;只不过这样的话空间复杂度为 O ( n ) O(n) O(n),不是常数级别。
//带头结点版本 class Solution { public:ListNode* sortList(ListNode* head) {vector<int> vec; //创建一个数组待会将链表值装进去;ListNode *p = head -> next;while(p != NULL) {vec.push_back(p-> val);p = p -> next; //装值进表}sort(vec.begin(),vec.end()); //对数组进行排序,408考试的话建议默写一个快排模板调用一下,这样会少扣点分;ListNode *tail = head;for(int i = 0; i < vec.size();++i) { tail -> next = new ListNode(vec[i]); //将数组值创建结点并尾插入新链表;tail = tail -> next;} return head; } };时空复杂度为 O ( n l o g n ) / O ( n ) O(nlogn)/O(n) O(nlogn)/O(n),如果时间不够就用该方法,有能力的可以掌握一下归并排序的方法。
另外可以采用自顶向下的归并排序来解决这道题,这样的话这道题首先运用了
快慢指针找中间结点的模板,然后对左右两部分子链表分别归并排序,再将这两段排序后的链表运用合并两个有序链表的模板合并起来便得到最终结果。class Solution { public:ListNode* sortList(ListNode* head) {return mergeSort(head);}ListNode* mergeSort(ListNode* head) { //运用了归并排序的思想if(head == NULL || head -> next == NULL) return head; //递归出口,没有结点或只有一个结点,无需排序,直接返回;ListNode *fast = head, *slow = head, *pre, *l, *r; while(fast && fast -> next) { //快慢指针找中间结点模板,注意这里的pre是用来标记中间结点的直接前驱的指针,用于后面将链表从中间一分为二;pre = slow;slow = slow -> next;fast = fast -> next -> next;}r = mergeSort(slow); //对右半部分进行归并排序;pre -> next = NULL; //将链表从中间断开;l = mergeSort(head); //对左半部分进行归并排序;return mergeTwoLists(l,r); //调用合并两个有序链表的函数将左右两部分合并;}ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) { //合并两个有序链表的模板,具体见上面;ListNode* dummy = new ListNode(0,nullptr),*p = list1,*q = list2, *cur = dummy;while(p && q) {if(p -> val < q -> val) {cur -> next = p;cur = cur -> next;p = p -> next;}else {cur -> next = q;cur = cur -> next;q = q -> next;}}if(q == NULL) cur -> next = p;else{cur -> next = q;}return dummy -> next;} };时间复杂度: O ( n l o g n ) O(nlogn) O(nlogn),其中 n n n是链表的长度。
空间复杂度: O ( l o g n ) O(logn) O(logn),其中 n n n是链表的长度。空间复杂度主要取决于递归调用的栈空间。
2.7.5 合并链表问题
-
解题思路:
迭代法,分别在两条链表的第一个结点处设置一个指针(双指针)然后边比较边将较小的结点插入新链表,较小结点的那个指针向后移动,当跳出循环说明有一个链表已经遍历结束,此时将剩余未遍历完的链表加入新链表即可。//带头结点的版本ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {if(list1 -> next == NULL) return list2;if(list2 -> next == NULL) return list1;ListNode * L = new ListNode(0,NULL); //新链表的头结点;ListNode *p = list1 -> next , *q = list2 -> next; //在两条链表的第一个结点处分别设置指针用于遍历当前链表;ListNode *tail = L; //tail是新链表的表尾指针,用于尾插法,注意在插入节点后及时更新让其始终处于表尾位置;while(p && q) {if(p -> val < q -> val) {tail -> next = p; //利用尾插法插入新结点;tail = p; //更新表尾指针;也可以在"if-else"循环外写"tail = tail -> next";p = p -> next; //更新用于遍历list1的指针}else {tail -> next = q;tail= q;q = q -> next;}}tail -> next = (p == NULL) ? q : p; //二目运算符,如果跳出循环后list1为空,将list2剩余部分接到cur后面,否则接另一条的剩余部分;return L;}时间复杂度: O ( n + m ) O(n+m) O(n+m),其中 n n n和 m m m分别为两个链表的长度。因为每次循环迭代中,
list1和list2只有一个元素会被放进合并链表中, 因此 while 循环的次数不会超过两个链表的长度之和。所有其他操作的时间复杂度都是常数级别的,因此总的时间复杂度为 O ( n + m ) O(n+m) O(n+m)空间复杂度: O ( 1 ) O(1) O(1)。我们只需要常数的空间存放若干变量。
-
当然,本题也可以用递归来解决,这里给出代码具体原理不再赘述
//不带头结点的版本 class Solution { public:ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {if (l1 == nullptr) {return l2;} else if (l2 == nullptr) {return l1;} else if (l1->val < l2->val) {l1->next = mergeTwoLists(l1->next, l2);return l1;} else {l2->next = mergeTwoLists(l1, l2->next);return l2;}} };时间复杂度: O ( n + m ) O(n+m) O(n+m),其中 n n n和 m m m分别为两个链表的长度。因为每次调用递归都会去掉 l1 或者 l2 的头节点(直到至少有一个链表为空),函数
mergeTwoList至多只会递归调用每个节点一次。因此,时间复杂度取决于合并后的链表长度,即 O ( n + m ) O(n+m) O(n+m)。空间复杂度: O ( n + m ) O(n+m) O(n+m),其中 n n n和 m m m分别为两个链表的长度。递归调用
mergeTwoLists函数时需要消耗栈空间,栈空间的大小取决于递归调用的深度。结束递归调用时mergeTwoLists函数最多调用 n + m n+m n+m 次,因此空间复杂度为 O ( n + m ) O(n+m) O(n+m).由于递归空间复杂度大,考试时一般采用迭代法。
- 进阶版:23. 合并 K 个升序链表
-
暴力做法:顺序合并,用一个变量 a n s ans ans来维护以及合并的链表,第 i i i次循环把第 i i i个链表和 a n s ans ans合并,答案保存到 a n s ans ans中。
ListNode* mergeKLists(vector<ListNode*>& lists) {ListNode* ans = NULL;int n = lists.size();for(int i = 0; i < n; ++i) {ans = mergeTwoLists(ans,lists[i]); //调用上面那个合并两条递增链表的函数; }return ans; }时间复杂度:假设每个链表的最长长度是 n n n。在第一次合并后, a n s ans ans的长度为 n n n;第二次合并后, a n s ans ans的长度为 2 × n 2×n 2×n,第 i i i次合并后, a n s ans ans的长度为 i × n i×n i×n。第 i i i次合并的时间代价是 O ( n + ( i − 1 ) × n ) = O ( i × n ) O(n+(i−1)×n)=O(i×n) O(n+(i−1)×n)=O(i×n),那么总的时间代价为
∑ i = 1 k ( i ∗ n ) = n ∑ i = 1 k i = n ( 1 + 2 + ⋯ + k ) = n ∗ k ( k + 1 ) 2 = O ( k 2 n ) \sum_{i = 1}^{k}(i*n)= n\sum_{i = 1}^{k}i = n(1+2+\cdots+k) = n*\frac{k(k+1)}{2}=O(k^2n) i=1∑k(i∗n)=ni=1∑ki=n(1+2+⋯+k)=n∗2k(k+1)=O(k2n)
其中k为链表条数,n为链表最长长度;空间复杂度:没有用到与 k 和 n k和n k和n规模相关的辅助空间,故渐进空间复杂度为 O ( 1 ) O(1) O(1)。
-
也可以使用多路归并+优先队列等方法,可以看力扣题解区,俺不会;
- 合并两个链表变体题
给你两个链表
list1和list2,它们包含的元素分别为 n 个和 m 个。请你将
list1中下标从 a 到 b 的全部节点都删除,并将list2接在被删除节点的位置。下图中蓝色边和节点展示了操作后的结果,请你返回结果链表的头指针。
-
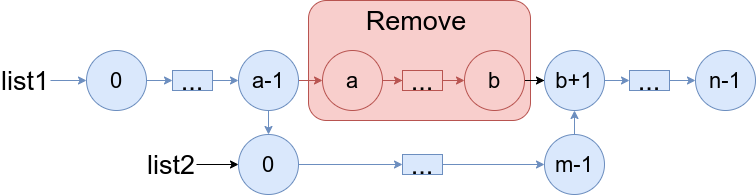
class Solution { public:ListNode* mergeInBetween(ListNode* list1, int a, int b, ListNode* list2) {ListNode* p = list1;for(int i = 0; i < a -1; ++i){ //找到第a-1个节点p = p -> next;}ListNode* q= p;int c = b - a + 2; //找到第b+1个结点;while(c--) {q = q -> next;}p -> next = list2;ListNode *r = list2; //找list2的最后一个节点;while(r -> next) {r = r -> next;}r -> next = q;return list1; } };时空复杂度: O ( n + m ) , O ( 1 ) O(n+m),O(1) O(n+m),O(1)
-
解题思路:本题和上面那题思路差不多,设置两个指针比较大小,只不过上面那题可以采用尾插法,而本题必须采用头插法,将比较得出的较小结点插入新链表,(因为如果采用尾插的话比较当前结点得出的较大结点不是所有节点中的最大结点,因此不可行),在跳出循环后不能直接将剩余链表接在其后面,依然需要一个一个用头插法插回新链表。
//带头结点版本 ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {ListNode* L = new ListNode(0,NULL); //新链表的头结点;ListNode*p = list1 -> next ,*q = list2 -> next; //在两条链表的第一个结点处分别设置指针while(p && q) {if(p -> val <= q -> val) {ListNode *next = p -> next; //由于后续要用到p-> next,但是下一步就更新了,所以先保存一下该指针p -> next = L -> next; //头插法经典操作;L -> next = p; p = next; //更新p指针}else {ListNode *next = q -> next;q -> next = L -> next; //头插操作L -> next = q; q = next;}}while(p) { //如果跳出循环后,list1还没有完全加入新链表,则继续将其用头插法插入到新链表中;ListNode *next = p -> next;p -> next = L -> next; //头插法L -> next = p; p = next;}while(q) {ListNode *next = q -> next;q -> next = L -> next; //头插法L -> next = q; q = next;}return L; }
2.7.6 拆分链表问题
ListNode* oddEvenList(ListNode* A) {ListNode* B = new ListNode(0,NULL); //创建B链表的头结点,并且指向空;ListNode *tail1 = A, *tail2 = B, *p = A-> next; //分别设置两条链表的表尾指针,再用一个p指针用来遍历原链表;A -> next = NULL; //将A结点与原链表断连;while(p != NULL) {tail1 -> next = p; //将当前处于奇数位置的链表结点插入A链表的表尾处;tail1 = p; //更新链表A的表尾指针;p = p -> next; //更新p指针,向后移动遍历原链表;tail2 -> next = p; //将当前处于偶数位置的链表结点插入B链表的表尾处;tail2 = p; //更新链表B的表尾指针;if(p) { //如果当前结点为空,说明已经插入完毕;p = p -> next;}}tail1 -> next = NULL; //将A链表表尾断连;return B; }如果题目是:给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。请注意,偶数组和奇数组内部的相对顺序应该与输入时保持一致。你必须在 O(1) 的额外空间复杂度和 O(n) 的时间复杂度下解决这个问题。
解题思路:按照上面的套路将链表一分为二,然后将链表B插入链表A后面就可以完成该题;
ListNode* oddEvenList(ListNode* A) {ListNode* B = new ListNode(0,NULL); ListNode *tail1 = A, *tail2 = B, *p = A-> next; A -> next = NULL; while(p != NULL) {tail1 -> next = p; tail1 = p; p = p -> next; tail2 -> next = p; tail2 = p; if(p) { }}tail1 -> next = B-> next; //修改之处,将A链表的表尾指针指向B链表的第一个结点就可以完成题目要求;return A; //返回插入后的A链表; }
- 奇偶链表变体题:
设 C = [ a 1 , b 1 , a 2 , b 2 , a 3 , b 3 , ⋯ ] C ={[a1, b1, a2, b2, a3, b3,\cdots]} C=[a1,b1,a2,b2,a3,b3,⋯]为线性表,采用带头结点的单链表存放,设计一个就地算法,将其拆分为两个线性表,使得 A = [ a 1 , a 2 , ⋅ ⋅ ⋅ , a n ] , B = [ b n , ⋅ ⋅ ⋅ , b 2 , b 1 ] A = {[a1, a2, ···, an}], B = {[bn,···,b2, b1}] A=[a1,a2,⋅⋅⋅,an],B=[bn,⋅⋅⋅,b2,b1],并返回B链表。
-
解题思路:与上一题大致思路相等,只是不同的是,奇数位置按尾插法插入链表表尾,偶数位置采用头插法插到B链表中。
ListNode* oddEvenList(ListNode* A) {ListNode* B = new ListNode(0,NULL); //创建B链表的头结点,并且指向空;ListNode *tail1= A, *p = A-> next, *q; //设置A链表的表尾指针,再用一个p指针用来遍历原链表;A -> next = NULL; //将A结点与原链表断连;while(p != NULL) {tail1 -> next = p; //将当前处于奇数位置的链表结点利用尾插法插入A链表的表尾处;tail1 = p; //更新链表A的表尾指针;p = p -> next; //更新p指针,向后移动遍历原链表;q = p; //由于处于偶数位置的结点需要头插回B链表,所以其后继指针会变动,因此提前保存一下;q -> next = B -> next; //将偶数位置结点插入B链表;B -> next = q; if(p) {p = p -> next}}tail1 -> next = NULL; //将A链表表尾断连;return B; }当然本题也可以变成返回将这两条链表合体后的链表,只不过结尾多了一句
tail1 -> next = B -> next, return A即可。这里再赘述一遍,上面的是带有头结点的版本,如果去leetcode上写的话都是没有头结点的版本,只需要自己设置一个新的
dummy结点指向头结点便与此题一样了!
- 分隔链表
-
题目描述:给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有
小于 x的节点都出现在 大于或等于x的节点之前;你应当 保留 两个分区中每个节点的初始相对位置。
-
示例:
1.
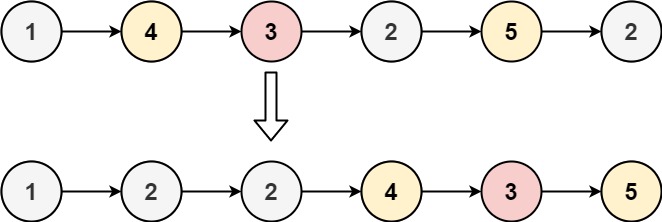
输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5] -
解题思路:和第一题奇偶链表思路差不多,设置两条新链表,再用一个指针p来遍历链表,比x小的用尾插法放入第一条链表,比x大的用尾插法加入第二条链表,最后将两条链表链接起来返回即可;
用尾插法可以保证两个分区中的每个结点的相对位置不变,这也是尾插法的重要性质。
//不带头结点版本 class Solution { public:ListNode* partition(ListNode* head, int x) {ListNode *dummy1 = new ListNode(0,NULL), *dummy2 = new ListNode(0,NULL); //设置两条新链表的头结点;ListNode *tail1 = dummy1, *tail2 = dummy2, *p = head; //两条链表的表尾指针,p指针用来遍历链表;while(p) {if(p -> val < x) {tail1 -> next = p; //利用尾插法插入第一条链表表尾;tail1 = p;}else{tail2 -> next = p; 利用尾插法插入第二条链表表尾;tail2 = p;}p = p -> next; //p结点向后移动遍历;}tail1 -> next = dummy2 -> next; //将第二条链表接在第一条链表后面;tail2 -> next = NULL; //注意释放临时结点的next指针以免超出内存限制;否则有可能成环;return dummy1 -> next;} };
2.7.7 其他链表问题
- **相交链表**2012年真题
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:题目数据 保证 整个链式结构中不存在环。注意,函数返回结果后,链表必须 保持其原始结构 。
如图
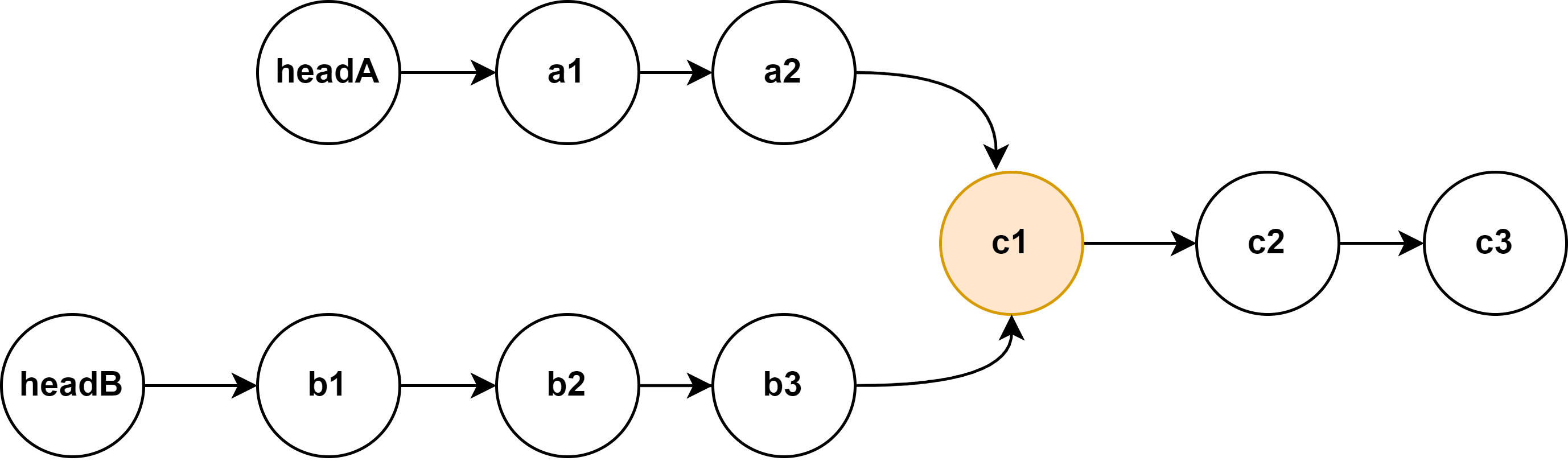
-
暴力解:先分别遍历两条链表求得其长度,然后设置两个指针分别指向表头,先让位于较长链表的那个指针先往后移动长度差距离,然后两个指针同时向后遍历,如果在遍历过程中发现相等则返回该结点,否则继续遍历,如果走到链尾也没有发现元素相等,则说明没有相交,返回NULL,这种方法需要遍历两次链表;不过该种方法空间复杂度也是 O ( 1 ) O(1) O(1),也算不错。
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *p = headA -> next, *q = headB-> next, *p1 = p, *q1 = q;int n1 = 0, n2 = 0;while(p){n1 ++;p = p -> next;}while(q) {n2++;q = q -> next;}if(n1 < n2) {for(int i = 0; i < n2 - n1; ++i) {q1 = q1 -> next;} while(p1){if(p1 == q1 ) {return p1;}else{p1 = p1 -> next;q1 = q1 -> next;}}return NULL;}else{for(int i = 0; i < n1 - n2; ++i) {p1 = p1 -> next;} while(p1){if(p1 == q1 {return p1;}else{p1 = p1 -> next;q1 = q1-> next;}}return NULL;} }
最优解:本题的难点在于由于两条链表的长度可能不同,两条链表之间的结点无法对应;这时我们可以分别在两条链表的第一个结点处设置一个指针,然后其中一条链表的指针走到结束时回到另一条链表的第一个结点处继续往后走,由于两个指针走过的距离一样长,因此如果两条链表相交的话,那么一定会相遇;否则则两个指针一直走到结束,其走过的路程为两条链表长度和的2倍;
// 设A的长度为a+c,B的长度为b+c;其中c为A、B的公共部分; // 拼接AB、BA:A+B=a+c+b+c B+A=b+c+a+c;由于a+c+b=b+c+a,因此二者必定在c的起始点处相遇 //带头结点做法 ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *curA=headA -> next,*curB=headB -> next;while(curA!=curB){// 每次判断当前点是否为空的好处是:避免A B无公共部分,再走完A+B和B+A后,会在nullptr处相遇curA = curA ? curA->next : headB -> next;curB = curB ? curB->next : headA -> next;}return curA; //只要是对的人,就算开始错过了,最终还是会再次相遇在一起的。 }//不带头结点做法 ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *curA=headA,*curB=headB;while(curA!=curB){// 每次判断当前点是否为空的好处是:避免A B无公共部分,再走完A+B和B+A后,会在nullptr处相遇curA=curA?curA->next:headB;curB=curB?curB->next:headA;}return curA; } -
b+c B+A=b+c+a+c;由于a+c+b=b+c+a,因此二者必定在c的起始点处相遇
//带头结点做法
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *curA=headA -> next,*curB=headB -> next;
while(curA!=curB){
// 每次判断当前点是否为空的好处是:避免A B无公共部分,再走完A+B和B+A后,会在nullptr处相遇
curA = curA ? curA->next : headB -> next;
curB = curB ? curB->next : headA -> next;
}
return curA; //只要是对的人,就算开始错过了,最终还是会再次相遇在一起的。
}
//不带头结点做法
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *curA=headA,*curB=headB;while(curA!=curB){// 每次判断当前点是否为空的好处是:避免A B无公共部分,再走完A+B和B+A后,会在nullptr处相遇curA=curA?curA->next:headB;curB=curB?curB->next:headA;}return curA;}```