文章目录
文章目录
一、MySQL概述
1.数据库的概念
一个数据库服务器上,可以把很多有业务联系的表,放在一起,构成一个逻辑上的“数据集合”
数据库,是管理数据的软件->增删改查(CRUD)
Oracle 、MySQL 、SQLServer 、SQLite 是关系型数据库,使用“表”来组织数据
redis 、MongoDB、HBase 是非关系型数据库,使用“文档”/"键值对"来组织数据
MySQL
MySQL是一个“客户端-服务器”结构的软件
MySQL本体是服务器,在服务器这边来负责存储和管理数据。数据存储在硬盘上。
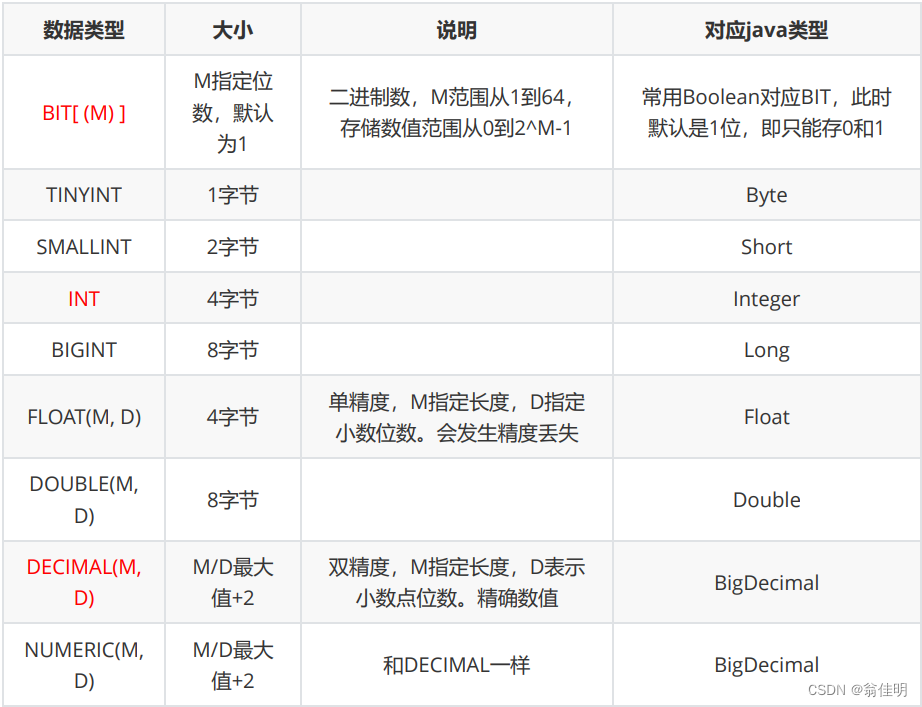
MySQL中支持的数据类型:
一个表,包含很多行,每一行也称为一条记录。一个行可以有很多列,每一列也称为是一个字段。每个列都是有一个具体的类型。
数值类型:
-
数值类型可以指定为无符号(unsigned),表示不取负数。
-
1字节(bytes)= 8bit
-
浮点数中,()用来表示精度:M表示小数的长度 D表示小数点后的位数
double(3,1) 表示数的长度是3,小数点后有1位 34.1 、12.3
-
此处的Double和Float和Java、C类似,都是通过IEEE745标准的浮点数。
-
DECIMAL:精度更高的浮点数(采用字符串的方式来存储小数),精度高、运算速度慢、空间开销大。
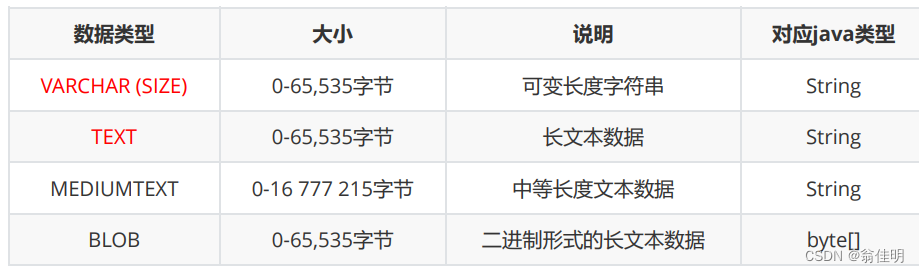
- varchar :变长的字符串 。size表示的是该类型里最多存储几个字符(不是字节)

- 保存时间戳
时间戳 :以1970年1月1日0时0分0秒为基准,计算当前时刻的基准时间的差值
2.数据库的操作
1.命令行客户端
2.图形化客户端
1.创建数据库
create database 数据库名字;
create database if not exists 数据库名字; //
- 如果已经存在,则不会再继续创建。在批量执行的情况下,避免sql报错。
在创建数据库的时候,可以手动指定字符集
character set 字符集名字
charset 字符集名字create database if not exists day5_09 charset utf8;
2.查看数据库
show databases;
sql命令都要以英文分号结束
3.选中数据库
use 数据库名;
数据库中,最重要的操作就是针对表进行增删改查。表是从属于数据库的,要准对表操作,就要先确定是那个数据库的表。
4.删除数据库
drop database 数据库名;
删除操作,删掉的不仅仅是database,同时也删掉了database中所有的表,以及表中的所有的数据。
线上数据库 / 生产环境数据库(被用户访问的数据库,存储真实的用户信息)
线下数据库 (在开发、测试阶段自己构造的“假的”数据)
为了避免误操作删除数据库,
1.要做好权限的限制
2.及时做好数据的备份
3.数据表的操作
- 操作表的前提是先选中数据库
use 数据库名;
1.创建表
create table 表名(列名 类型,列名 类型...);
create table student(id int,name varchar(10));
- 如果表名/列名和关键字相同,需要用反引号
引起来
2.查看当前数据库中的所有表
show tables;
3.查看指定表的结构
desc 表名;
- desc(describe描述)
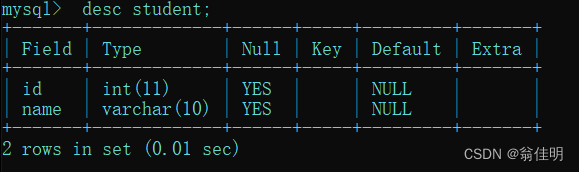
Field:表示字段(列)
这里的int(11)表示的是显示的宽度,显示的时候最多占11个字符,和存储的容量无关
Null:空值,表格中的这个格子是没有填写的,此处写作YES允许这一列为null
Key:表示当前这一列的约束
Default: 默认值。
Extra:额外信息。
4.删除表
drop table 表名;
删表比删数据库更严重,删库会在第一时间报错,可以第一时间进行处理。但是删表操作,程序不一定第一时间报错。发现时间就会更晚。
二、MySQL的编码问题
常见的编码类型
- ASCII编码:单字节(8bit)7bit存储数据,最高位是奇偶校验位(只支持英语)
- Latin1编码(ISO-8859-1):单字节编码,向下兼容ASCII,8位存储
Latin1编码采用了单字节内所有的空间,在支持Latin1编码的系统中传输和存储其他任何编码的字节流都不会被抛弃,也就是说,把其他任何编码的字节流当作Latin1编码看待都没有问题,MySQL的默认编码就是Latin1
- Unicode编码:将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码
Unicode是一个很大的符号集,可以容纳100多万个符号,只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储,如果所有字符都按照最大存储空间存储,那必然会浪费很大的空间,比如英文字母只需要1个字节,但是会用三个字节来存储。
-
UTF-8编码:变长编码,使用1~4个字节来表示一个符号
-
GBK编码:双字节编码。
mysql服务器默认使用latin1字符集,但是latin1不支持中文,客户端发送的GDK,经过连接器放到服务器时,发现服务器采用的是latin1格式,GBK是2字节编码,转换成latin1字节编码,就相当于大网捞小鱼,会丢失字节。存的数据就是错误的数据。mysql就不让进行存储,提示1366错误的原因。”"ERROR 1366 (HY000): Incorrect string value: ‘\xD5\xC5\xC8\xFD’ ““for column ‘sname’ at row 1”,此时需要将服务器的字符集设置成UTF8,通过变长编码保障数据的完整性。
在创建数据库的时候,需要设置charset = utf8
cmd chcp//查看本机的字符集//活动代码页: 936
window客户端的字符集: 936 ->GBK
我们发现,客户端输入的字符集是GBK,MySQL服务器建表时存储数据采用的字符集是utf8
在这个过程中,经历了编码的转换。
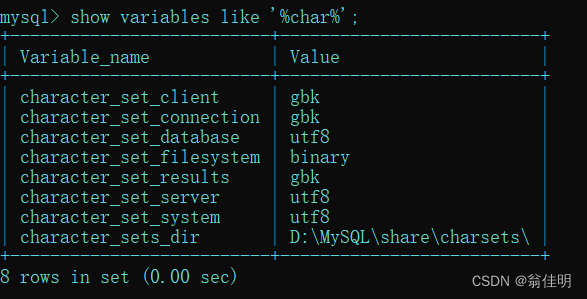
show character set;
//查看数据库支持的所有的字符集status;
// 查看系统当前状态,里面可以看到部分字符集设置。show variables like '%char%'
// 查看系统字符集设置,包括所有的字符集设置
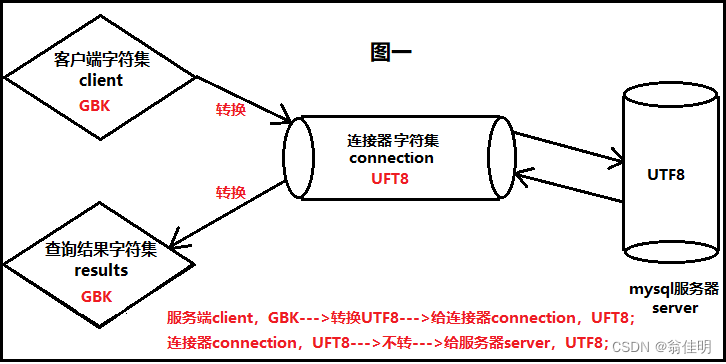
通过connection 连接器来实现转换
连接器的工作流程
1.客户端的字符先发给连接器,转换成连接器的编码格式,进行临时存储。
2.连接器再次转换成服务器需要的编码
3.服务器返回的结果,先通过连接器,转换成与客户端一致的编码
方法一:连接器的UTF8
1)设置客户端的字符集
set character_set_client=gbk;
2)设置连接器的字符集
set character_set_connection=utf8;
3)设置返回结果的字符集
set character_set_results=gbk;
-
cmd中的字符集是GBK,同理要在cmd上显示的结果也是GBK编码的。
-
服务器指定的是utf8格式
1.客户端输入的GBK会先通过连接器,转换成UTF8,临时存储在连接器中
2.连接器发现服务器的编码类型也是UTF8,直接发送给服务器进行存储
3.服务器直接把UTF8的数据发给连接器,连接器发现客户端的编码方式是GBK,于是进行转换。
方法二:连接器是GBK
set names gbk;
相当于下面三行
set character_set_client=gbk;
set character_set_connection=gbk;
set character_set_results=gbk;
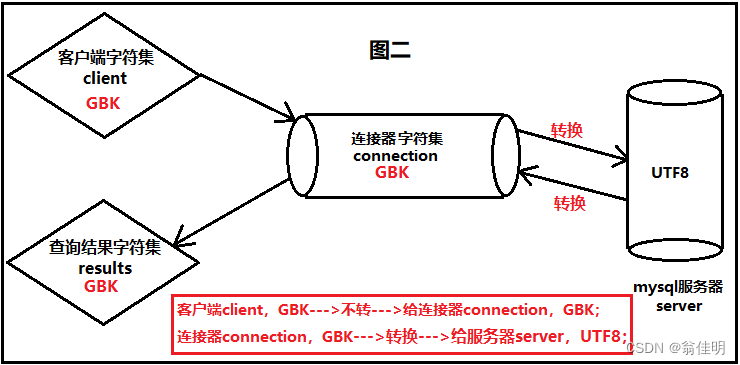
1.客户端发送的是GBK格式,连接器此时也是GBK格式的,顺利通过连接器
2.连接器向服务器发送数据,发现服务器是UTF8格式的,进行转换
3.服务器先向连接器发送数据的时候,发现连接器的GBK格式的,同样要进行转换。连接器返回客户端时,由于都是GBK格式的,直接返回cmd进行显示。
点击移步博客主页,欢迎光临~