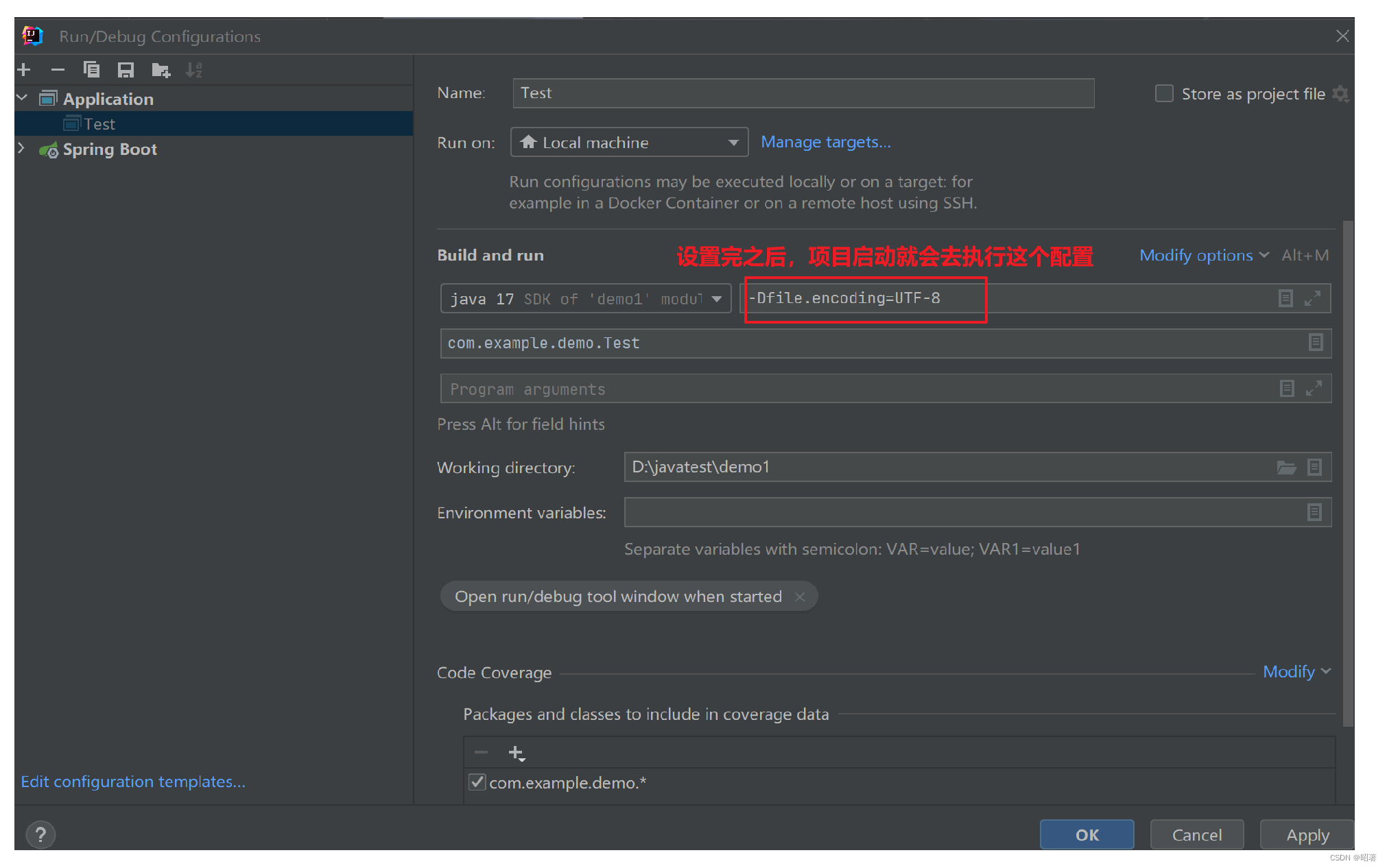
目录
1. RDB机制的配置
2. fork()函数和写时复制(Copy On Write)
什么是Copy On Write
系统fork中使用Copy On Write机制
3. RDB文件结构
RDB文件内容和内容顺序
InfoAuxFields是rdb信息数据
数据库数据
数据
数据存储格式
字符串编码
操作码
4. RDB的2个触发时机
RDB定时生成
rdbSave函数
rdbSaveRio函数写数据到rdb文件
5. Redis重启,加载RDB 文件
Redis是把数据储存在内存的键值数据库,而服务器一旦宕机,那内存中的数据将全部丢失。像MySQL那样,是有宕机后数据恢复机制的。那Redis也是有的,其有两种方式:AOF和RDB。该文章讲解RDB(Redis Database)。
RDB会在不同的时间点将内存中数据库快照以二进制形式写入到磁盘。
备注:RDB机制是比较好理解的,就是其文件的格式有点不好弄懂,因为是二进制内容,其写的格式就有点绕吧。要是看不太懂,可以先跳过RDB文件结构这节,不过要理解RDB的内容顺序才行,不然看关于写RDB文件的代码时候会比较乱。
1. RDB机制的配置
达到某些条件,就会进行RDB快照,而这些条件是在redis.conf文件中配置的。
#格式 save <seconds> <changes>
#在 seconds 时间内如果变更的键数量不少于 changes,则生成一次 RDBsave 3600 1 # 3600 秒内,至少变更 1 次,才会自动备份save 300 100save 60 10000save #这样是表示停用RDB
#save #注释掉save, 也是表示停用RDB的rdbcompression yes #对于存储到磁盘中的快照,是否启动 LZF 压缩算法,yes表示使用
rdbchecksum yes #否启动 CRC64 算法进行数据校验,默认是启用,这是会增加cpu消耗
dbfilename dump.rdb #快照备份文件的名字
rdb-del-sync-files nosave的配置会存储到server.saveparam。
struct redisServer {.............long long dirty; /* Changes to DB from the last save */long long dirty_before_bgsave; /* Used to restore dirty on failed BGSAVE */struct saveparam *saveparams; /* Save points array for RDB */int saveparamslen; /* Number of saving points */time_t lastsave; /* Unix time of last successful save */
};struct saveparam {time_t seconds;int changes;
};int main(int argc, char **argv) {initServerConfig();........................if (argc >= 2) { //表示是指定配置文件启动的,比如: redis-server ./redis.conf.......................loadServerConfig(server.configfile, config_from_stdin, options);}................
}void initServerConfig(void) {//这些是默认的配置appendServerSaveParams(60*60,1); /* save after 1 hour and 1 change */appendServerSaveParams(300,100); /* save after 5 minutes and 100 changes */appendServerSaveParams(60,10000); /* save after 1 minute and 10000 changes */.......................
}函数调用: loadServerConfig————>loadServerConfigFromString
void loadServerConfigFromString(char *config) {int linenum = 0, totlines, i;sds *lines;int save_loaded = 0;lines = sdssplitlen(config,strlen(config),"\n",1,&totlines);for (i = 0; i < totlines; i++) {sds *argv;int argc;linenum = i+1;lines[i] = sdstrim(lines[i]," \t\r\n");/* Skip comments and blank lines */if (lines[i][0] == '#' || lines[i][0] == '\0') continue;/* Split into arguments */argv = sdssplitargs(lines[i],&argc);.................................../* Execute config directives */ //没有展示其他配置的解析........if (!strcasecmp(argv[0],"bind") && argc >= 2) {..............} else if (!strcasecmp(argv[0],"save")) { //就是这解析save的配置内容if (!save_loaded) {save_loaded = 1;resetServerSaveParams();}if (argc == 3) {int seconds = atoi(argv[1]);int changes = atoi(argv[2]);if (seconds < 1 || changes < 0) {err = "Invalid save parameters"; goto loaderr;}appendServerSaveParams(seconds,changes);} else if (argc == 2 && !strcasecmp(argv[1],"")) {resetServerSaveParams();}}}.....................
}void appendServerSaveParams(time_t seconds, int changes) {server.saveparams = zrealloc(server.saveparams,sizeof(struct saveparam)*(server.saveparamslen+1));server.saveparams[server.saveparamslen].seconds = seconds;server.saveparams[server.saveparamslen].changes = changes;server.saveparamslen++;
}2. fork()函数和写时复制(Copy On Write)
fork函数执行后,会产生一个新的子进程。其子进程会复制父进程的数据与堆栈空间,并继承父进程的用户代码、环境变量、已打来的文件代码等。而这里的复制就是使用了写时复制(COW,Copy on Write)机制。
什么是Copy On Write
写时复制的核心思想是 若有多个调用者同时请求相同资源,他们会共同获取相同的指针指向相同的资源,直到某个调用者视图修改资源的内容是,系统才会真正复制一个专用副本给该调用者,而其他调用者所见的最初的资源仍然保持不变,而该过程对其他的调用折是透明的,不被感知的。
此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被建立,因此多个调用者只是读取操作时可以共享同一份资源。
系统fork中使用Copy On Write机制
而在使用fork创建子进程时候,只有当进程需要修改资源时候才会真正执行数据的拷贝,之后就再进程自己的数据段进行修改数据。否则,若是进程只有读请求,实际上不需要执行资源的复制操作,只是需要对不同进程之间维护对资源的引用即可。
在fork()后,内核把父进程中的所有内存页的权限都设置为read-only,然后子进程的地址空间指向父进程。
当某个进程写内存时候,cpu检测到该内存页是read-only,就会触发异常中断(page-fault),陷入内核的一个中断例程。该中断例程中,内核会把触发异常的页复制一份,之后,父子进程就各自持有独立的一份了,之后进程再修改对应的数据。
其好处:
- 可减少分配和复制大量资源时带来的瞬间延时。
- 可减少不必要的资源分配。比如fork进程时,并不是所有的页面都需要复制,父进程的代码段和只读数据段都不被允许修改,所以无需复制。
缺点
- 如果在fork()之后,父子进程都还需要继续进行写操作,那么会产生大量的分页错误(页异常中断page-fault),这样就得不偿失。
3. RDB文件结构
要先了解二进制文件存储的内容是怎样的。一条客户端命令是以什么格式存储到RDB文件中的。
RDB文件内容和内容顺序
按照大内容来分的话,有以下几部分。
- 文件头:这部分内容保存了 Redis 的魔数(即是REDIS)、RDB 版本、Redis 版本、RDB 信息数据InfoAuxFields和模块数据。
- 文件数据部分:这部分保存了 Redis 数据库实际的所有键值对 和 键值对占用的内存大小等信息和lua脚本数据。
- 文件尾:这部分保存了 RDB 文件的结束标识符OP_EOF,以及整个文件的校验值checksum。这个校验值用来在 Redis server 加载 RDB 文件后,检查文件是否被篡改过。
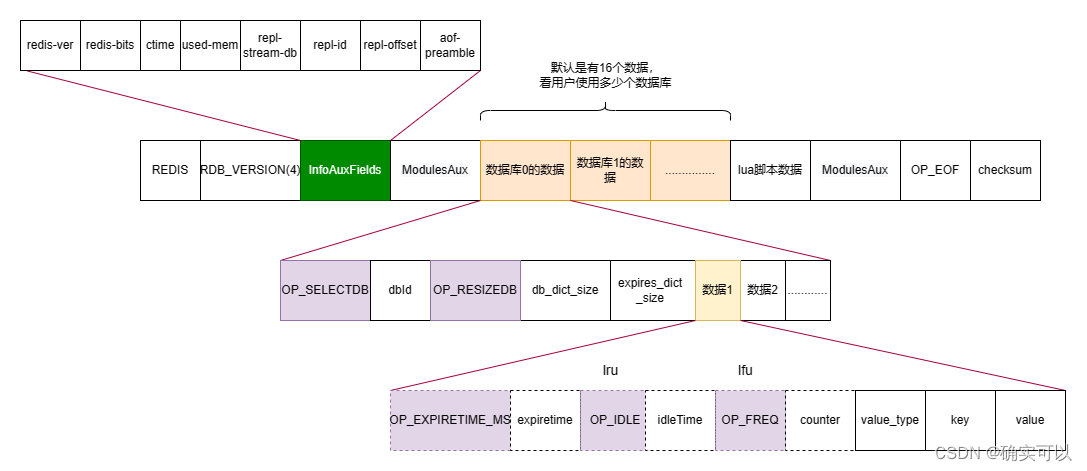
InfoAuxFields是rdb信息数据
- key 为 redis-ver, value 为当前 Redis 的版本, 比如 6.2.6 版本
- key 为 redis-bit, value 为当前 Redis 的位数, 64 位 / 32 位
- key 为 ctime, value 为 RDB 创建时的时间戳
- key 为 used-mem, value 为 dump 时 Redis 占的内存, 单位字节
- key 为 repl-steam-db, 和主从复制相关, 在 server.master 客户端中选择的数据库, 这个不一定有, 只有在当前的 RDB 文件是用作主从复制时才有值, 数据持久化时, 没有这个属性
- key 为 repl-id, 和主从复制相关, 当前实例 replication ID, 这个不一定有, 只有当前的 RDB 文件是用作主从复制时, 不是数据持久化时, 才有
- key 为 repl-offset, 和主从复制相关, 当前实例复制的偏移量, 这个不一定有, 只有当前的 RDB 文件是用作主从复制时, 不是数据持久化时, 才有
- key 为 aof-preamble, value 为是否开启了 aof/rdb 的混合使用
数据库数据
- OP_SELECTDB: 首先是1个字节选db的操作数,后面是一个整数标识具体的dbId,这个整数是进行编码的,字节数个数范围是[1,9]。
- OP_RESIZEDB: 这个操作数标识后面接着的是这个db的数据大小dbsize,以及过期键的大小expireSize
- 数据: 一个个keyValue的键值对,每种数据类型的具体存储数据
数据
上图中虚线表示的是不一定会存在的数据
- OP_EXPIRETIME_MS: 一个字节表示后续的是这条数据的过期时间
- OP_IDLE: 一个字节表示后续的是这条数据的过期时间 (lru)
- OP_FREQ: 一个字节表示后续接着的是这条数据的访问计数个数 (lfu)
- value_type: 这条数据的类型
- key: 一个字符串存储这条数据的key
- value: 每种数据结构具体的数据类型
/* Map object types to RDB object types. Macros starting with OBJ_ are for* memory storage and may change. Instead RDB types must be fixed because* we store them on disk. */
#define RDB_TYPE_STRING 0
#define RDB_TYPE_LIST 1
#define RDB_TYPE_SET 2
#define RDB_TYPE_ZSET 3
#define RDB_TYPE_HASH 4
#define RDB_TYPE_ZSET_2 5 /* ZSET version 2 with doubles stored in binary. */
#define RDB_TYPE_MODULE 6
#define RDB_TYPE_MODULE_2 7 /* Module value with annotations for parsing withoutthe generating module being loaded. */
/* NOTE: WHEN ADDING NEW RDB TYPE, UPDATE rdbIsObjectType() BELOW *//* Object types for encoded objects. */
#define RDB_TYPE_HASH_ZIPMAP 9
#define RDB_TYPE_LIST_ZIPLIST 10
#define RDB_TYPE_SET_INTSET 11
#define RDB_TYPE_ZSET_ZIPLIST 12
#define RDB_TYPE_HASH_ZIPLIST 13
#define RDB_TYPE_LIST_QUICKLIST 14
#define RDB_TYPE_STREAM_LISTPACKS 15这几个就是数据类型的定义
数据存储格式
RDB文件是二进制格式的,上图是数据的顺序,那每个数据是怎么存储的呢?总体就是确定内容的长度,之后再写入内容。
而确定内容的长度,有两种方式
- 内容的长度是定长的, 我们就给他制定特有的内容类型, 这个内容类型本身就代表了后面内容的长度
- 内容的长度是不定长的, 就通过自定义的一套整数规则, 在内容前面加上一个符合整数规则的数字, 表示内容的长度
字符串编码
rbd对字符串编码主要是先看第一个字节的前两位,如果前两位不是11则表示的是以字符串的形式存储的,其不同的编码方式来计算出这个字符串的长度。
而对于前两位是11则表示这个字符串可以用整数来表示,而其不同的编码方式也表示这个整数的具体的值的长度。
最后还有一种前面两位以及最后两位都是11的表示这个字符串是通过lzf进行压缩的,而其后面则是这个压缩的字符串的具体相关的数据。 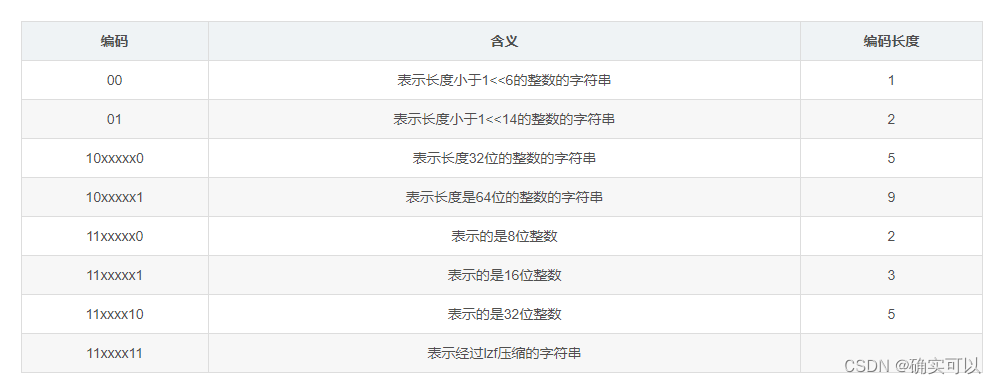
操作码
上面的 RDB 文件的逻辑结构中, 可以发现有一些属性, 在某些情况下是没有的, 这会造成什么问题呢?
顺着二进制文件一直读下去, 虽然数据解析出来了, 但是我们不知道这个数据是什么。
为了应对这种不一定存在的情况, Redis 定义了一套 操作码, 通过操作码表示后面的数据是什么, 让解析出来的数据能真正赋值到对应的属性。
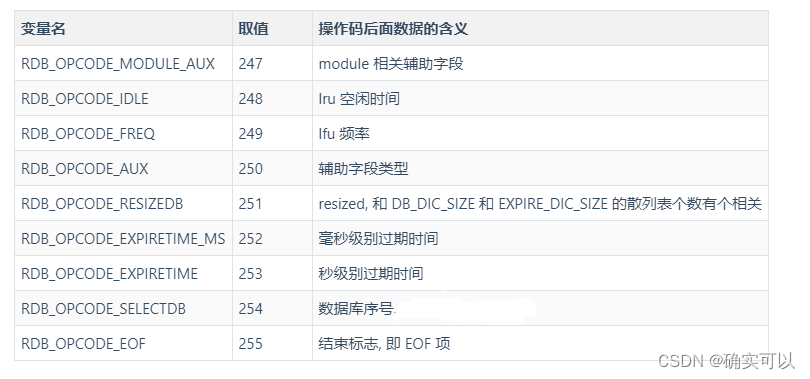
上图中紫色块的OP开头的就是操作码。
4. RDB的2个触发时机
- 用户发送命令来手动生成RDB
- save:由主进程执行,那么发送命令的客户端会被阻塞等到save结束,且为了保证镜像的一致,save期间Redis是只读的
- bgsave:这个是交由Redis的子进程来生成快照,父进程可以继续处理客户端请求。
- 通过定时函数serverCron,达到条件时自动生成RDB
用户手动发送bgsave生成RDB文件比较少见的,我们就只分析定时生成RDB文件。
RDB定时生成
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {...................................// 判断后台是否正在进行 RDB 或者 AOF 操作或者还有子进程阻塞在父级if (hasActiveChildProcess() || ldbPendingChildren()) {..............................} else { // 表示没有后台 RDB/AOF 在进行中,//进行检查是否需要立即开启 RDB/AOF// 遍历我们的触发规则列表 save 1000 1for (j = 0; j < server.saveparamslen; j++) {struct saveparam *sp = server.saveparams+j;if (server.dirty >= sp->changes && //当前修改过的key的数量 > 规则配置的key 修改数量值server.unixtime-server.lastsave > sp->seconds && //当前的时间 - 上次保存的时间 > 规则配置的时间频率 (server.unixtime-server.lastbgsave_try >CONFIG_BGSAVE_RETRY_DELAY ||server.lastbgsave_status == C_OK)){rdbSaveInfo rsi, *rsiptr;rsiptr = rdbPopulateSaveInfo(&rsi); //生成控制RDB生成的辅助变量rdbSaveInfo//开始RDB 保存数据rdbSaveBackground(server.rdb_filename,rsiptr);break;}}}....................if (!hasActiveChildProcess() &&server.rdb_bgsave_scheduled &&(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY ||server.lastbgsave_status == C_OK)) {rdbSaveInfo rsi, *rsiptr;rsiptr = rdbPopulateSaveInfo(&rsi);if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK)server.rdb_bgsave_scheduled = 0;}.........................
}上面的就是满足了配置好的规则触,就会执行rdbSaveBackground。其函数的实现如下:
- 若仍然有正在生成RDB文件的子进程,就立即返回,以防RDB定时任务和BGSAVE命令重叠。
- 保存当前的修改过的数据个数和更新时间戳, 并fork出子进程
- 在子进程中调用rdbSave函数生成RDB文件,并将子进程中修改的内容通过pipe发送给主进程,处理完后,会退出子进程。
- 主进程执行的,更新server的运行时数据,
server.rdb_child_type会记录刚刚 fork 的子进程 ID
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {pid_t childpid;// 1 .若仍然有正在生成RDB的子进程,则返回if (hasActiveChildProcess()) return C_ERR;//2 .保存当前的脏数据量 和 更新时间戳server.dirty_before_bgsave = server.dirty;server.lastbgsave_try = time(NULL);// .fork 子进程if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {int retval;/* Child */redisSetProcTitle("redis-rdb-bgsave");//子进程绑定到用户配置的CPU列表上,减少不必要的进程上下文切换redisSetCpuAffinity(server.bgsave_cpulist); //3 .生成RDB文件retval = rdbSave(filename,rsi);if (retval == C_OK) {//将子进程修改的内容,通过pipe发送给主进程sendChildCowInfo(CHILD_INFO_TYPE_RDB_COW_SIZE, "RDB");}exitFromChild((retval == C_OK) ? 0 : 1); //退出子进程} else {// 4 .父进程执行的if (childpid == -1) {server.lastbgsave_status = C_ERR;return C_ERR;}server.rdb_save_time_start = time(NULL);server.rdb_child_type = RDB_CHILD_TYPE_DISK;return C_OK;}return C_OK; /* unreached */
}rdbSave函数
子进程执行的就是rdbSave函数:
- 根据pid生成临时文件名,然后打开该文件
- 初始化rio对象,并根据用户配置设置rio对象的参数
- 使用rdbSaveRio函数把内存数据写入到临时文件
- 刷盘,确保把数据写到磁盘;之后重命名,替换旧文件;更新server中关于RDB的属性
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */
int rdbSave(char *filename, rdbSaveInfo *rsi) {char tmpfile[256];char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */FILE *fp = NULL;rio rdb;int error = 0;// 1 根据 pid 生成临时文件名,然后打开文件snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());fp = fopen(tmpfile,"w");//省略了对文件打开失败的处理...............// 2 初始化 rio 变量rioInitWithFile(&rdb,fp);startSaving(RDBFLAGS_NONE);// 根据用户配置设定 autosyncif (server.rdb_save_incremental_fsync)rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);// 3 将内存数据写入临时文件if (rdbSaveRio(&rdb,&error,RDBFLAGS_NONE,rsi) == C_ERR) {errno = error;goto werr;}// 4 刷盘,确保数据写到磁盘if (fflush(fp)) goto werr;if (fsync(fileno(fp))) goto werr;if (fclose(fp)) { fp = NULL; goto werr; }fp = NULL;// 5 重命名,替换旧文件if (rename(tmpfile,filename) == -1) {char *cwdp = getcwd(cwd,MAXPATHLEN);unlink(tmpfile);stopSaving(0);return C_ERR;}//更新server中的属性server.dirty = 0;server.lastsave = time(NULL);server.lastbgsave_status = C_OK;stopSaving(1);return C_OK;werr:if (fp) fclose(fp);unlink(tmpfile);stopSaving(0);return C_ERR;
}RDB 文件生成期间会频繁进行磁盘 I/O 操作。Redis 封装了 操作I/O的抽象层,叫做结构体rio,用来统一处理不同的存储介质(aof文件也是使用rio的)。上面代码中的rio对象就是这个。其相关的结构体如下:
struct _rio {// Backend functions.size_t (*read)(struct _rio *, void *buf, size_t len);size_t (*write)(struct _rio *, const void *buf, size_t len);off_t (*tell)(struct _rio *);int (*flush)(struct _rio *);void (*update_cksum)(struct _rio *, const void *buf, size_t len);/* The current checksum and flags (see RIO_FLAG_*) */uint64_t cksum, flags;/* number of bytes read or written */size_t processed_bytes;/* maximum single read or write chunk size */size_t max_processing_chunk;/* Backend-specific vars. */ //联合体union {/* In-memory buffer target. */struct {sds ptr;off_t pos;} buffer;/* Stdio file pointer target. */struct {FILE *fp;off_t buffered; /* Bytes written since last fsync. */off_t autosync; /* fsync after 'autosync' bytes written. */} file;/* Connection object (used to read from socket) */struct {connection *conn; /* Connection */off_t pos; /* pos in buf that was returned */sds buf; /* buffered data */size_t read_limit; /* don't allow to buffer/read more than that */size_t read_so_far; /* amount of data read from the rio (not buffered) */} conn;/* FD target (used to write to pipe). */struct {int fd; /* File descriptor. */off_t pos;sds buf;} fd;} io;
};typedef struct _rio rio;read、write、flush:对底层存储介质的读、写、刷盘操作函数指针;io:底层存储介质句柄,支持 file 文件、内存 buffer、conn 连接和管道文件描述符 fd。
rdbSaveRio函数写数据到rdb文件
该函数就是按照上面所讲的RDB文件格式和顺序把数据写入到文件中。
- 写入RDB_VERSION版本
- 写入辅助字段InfoAuxFields,写入模块数据
- 遍历所有的db(默认是16个db,默认是使用编号为0的db),把每个db的数据写入到文件中
- 把lua脚本内容写入rdb文件
- 写入模块内容
- 写入 EOF 文件结束标志
- 写入 CRC64 校验码
int rdbSaveRio(rio *rdb, int *error, int rdbflags, rdbSaveInfo *rsi) {dictIterator *di = NULL;dictEntry *de;char magic[10];uint64_t cksum;size_t processed = 0;int j;long key_count = 0;long long info_updated_time = 0;char *pname = (rdbflags & RDBFLAGS_AOF_PREAMBLE) ? "AOF rewrite" : "RDB";// 开启了 RDB 文件校验码功能if (server.rdb_checksum)rdb->update_cksum = rioGenericUpdateChecksum;// 1 写入RDB_VERSION 版本snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;// 2 写入辅助字段if (rdbSaveInfoAuxFields(rdb,rdbflags,rsi) == -1) goto werr;//触发模块回调, 这些模块,不明白if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr;// 3 遍历所有编号的 dbfor (j = 0; j < server.dbnum; j++) {redisDb *db = server.db+j;dict *d = db->dict;if (dictSize(d) == 0) continue;di = dictGetSafeIterator(d);// 4 写入 OPCODE_SELECTDB 标志,数据库 idif (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;if (rdbSaveLen(rdb,j) == -1) goto werr;// 5 写入 OPCODE_RESIZEDB 标志和数据库大小、过期字典大小uint64_t db_size, expires_size;db_size = dictSize(db->dict);expires_size = dictSize(db->expires);if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;if (rdbSaveLen(rdb,db_size) == -1) goto werr;if (rdbSaveLen(rdb,expires_size) == -1) goto werr;// 6 遍历所有键值对,写入 rdbwhile((de = dictNext(di)) != NULL) {sds keystr = dictGetKey(de);robj key, *o = dictGetVal(de);long long expire;initStaticStringObject(key,keystr);expire = getExpire(db,&key);if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;.....................................}dictReleaseIterator(di);di = NULL; /* So that we don't release it again on error. */}// 所有 db 写完后,持久化 lua 脚本内容if (rsi && dictSize(server.lua_scripts)) {di = dictGetIterator(server.lua_scripts);while((de = dictNext(di)) != NULL) {robj *body = dictGetVal(de);if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1)goto werr;}dictReleaseIterator(di);di = NULL; /* So that we don't release it again on error. */}if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;// 写入 EOF 文件结束标志if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;// 写入 CRC64 校验码cksum = rdb->cksum;memrev64ifbe(&cksum);if (rioWrite(rdb,&cksum,8) == 0) goto werr;return C_OK;........................
}该函数内部有个核心函数rdbSaveKeyValuePair(在while循环中的),负责将内存数据键值对写入磁盘文件。
/* Save a key-value pair, with expire time, type, key, value. */
int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime) {int savelru = server.maxmemory_policy & MAXMEMORY_FLAG_LRU;int savelfu = server.maxmemory_policy & MAXMEMORY_FLAG_LFU;/* Save the expire time */if (expiretime != -1) {if (rdbSaveType(rdb,RDB_OPCODE_EXPIRETIME_MS) == -1) return -1;if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1;}/* Save the LRU info. */if (savelru) {uint64_t idletime = estimateObjectIdleTime(val);idletime /= 1000; /* Using seconds is enough and requires less space.*/if (rdbSaveType(rdb,RDB_OPCODE_IDLE) == -1) return -1;if (rdbSaveLen(rdb,idletime) == -1) return -1;}/* Save the LFU info. */if (savelfu) {uint8_t buf[1];buf[0] = LFUDecrAndReturn(val);if (rdbSaveType(rdb,RDB_OPCODE_FREQ) == -1) return -1;if (rdbWriteRaw(rdb,buf,1) == -1) return -1;}/* Save type, key, value */if (rdbSaveObjectType(rdb,val) == -1) return -1; // 写入键值对类型标志if (rdbSaveStringObject(rdb,key) == -1) return -1; //写入keyif (rdbSaveObject(rdb,val,key) == -1) return -1; //写入value/* Delay return if required (for testing) */if (server.rdb_key_save_delay)debugDelay(server.rdb_key_save_delay);return 1;
}可以看到,Redis写入RDB文件时,是调用了很多rdbSaveXXX函数的。不同的后缀就是用于写入不同类型的数据。以rdbSaveType为例:
int rdbSaveType(rio *rdb, unsigned char type) {return rdbWriteRaw(rdb,&type,1);
}static ssize_t rdbWriteRaw(rio *rdb, void *p, size_t len) {if (rdb && rioWrite(rdb,p,len) == 0)return -1;return len;
}static inline size_t rioWrite(rio *r, const void *buf, size_t len) {if (r->flags & RIO_FLAG_WRITE_ERROR) return 0;while (len) {size_t bytes_to_write = (r->max_processing_chunk && r->max_processing_chunk < len) ? r->max_processing_chunk : len;if (r->update_cksum) r->update_cksum(r,buf,bytes_to_write);if (r->write(r,buf,bytes_to_write) == 0) {r->flags |= RIO_FLAG_WRITE_ERROR;return 0;}buf = (char*)buf + bytes_to_write;len -= bytes_to_write;r->processed_bytes += bytes_to_write;}return 1;
}5. Redis重启,加载RDB 文件
Redis 在启动过程中调用 loadDataFromDisk() 来完成 RDB 的加载。调用的函数链路:loadDataFromDisk——>rdbLoad——>rdbLoadRio。
int main(int argc, char **argv) {.......................if (!server.sentinel_mode) {..........loadDataFromDisk();}
}/* Function called at startup to load RDB or AOF file in memory. */
void loadDataFromDisk(void) {long long start = ustime();if (server.aof_state == AOF_ON) {loadAppendOnlyFile(server.aof_filename) //加载AOF文件 } else {rdbSaveInfo rsi = RDB_SAVE_INFO_INIT;errno = 0; /* Prevent a stale value from affecting error checking *///加载RDB文件 ======================if (rdbLoad(server.rdb_filename,&rsi,RDBFLAGS_NONE) == C_OK) {..................} else if (errno != ENOENT) {//写错误日志............exit(1);}}
}int rdbLoad(char *filename, rdbSaveInfo *rsi, int rdbflags) {FILE *fp;rio rdb;int retval;if ((fp = fopen(filename,"r")) == NULL) return C_ERR;startLoadingFile(fp, filename,rdbflags);rioInitWithFile(&rdb,fp);retval = rdbLoadRio(&rdb,rdbflags,rsi);fclose(fp);stopLoading(retval==C_OK);return retval;
}rdbLoadRio函数就是根据前面讲的RDB文件格式来解析数据。
/* Load an RDB file from the rio stream 'rdb'. On success C_OK is returned,* otherwise C_ERR is returned and 'errno' is set accordingly. */
int rdbLoadRio(rio *rdb, int rdbflags, rdbSaveInfo *rsi) {uint64_t dbid;int type, rdbver;redisDb *db = server.db+0;char buf[1024];int error;long long empty_keys_skipped = 0, expired_keys_skipped = 0, keys_loaded = 0;rdb->update_cksum = rdbLoadProgressCallback;rdb->max_processing_chunk = server.loading_process_events_interval_bytes;//读取 RDB 开头的九个字节if (rioRead(rdb,buf,9) == 0) goto eoferr;buf[9] = '\0';if (memcmp(buf,"REDIS",5) != 0) {serverLog(LL_WARNING,"Wrong signature trying to load DB from file");errno = EINVAL;return C_ERR;}rdbver = atoi(buf+5);if (rdbver < 1 || rdbver > RDB_VERSION) {serverLog(LL_WARNING,"Can't handle RDB format version %d",rdbver);errno = EINVAL;return C_ERR;}/* Key-specific attributes, set by opcodes before the key type. */long long lru_idle = -1, lfu_freq = -1, expiretime = -1, now = mstime();long long lru_clock = LRU_CLOCK();while(1) {sds key;robj *val;/* Read type. */if ((type = rdbLoadType(rdb)) == -1) goto eoferr;/* Handle special types. */if (type == RDB_OPCODE_EXPIRETIME) {expiretime = rdbLoadTime(rdb);expiretime *= 1000;if (rioGetReadError(rdb)) goto eoferr;continue; /* Read next opcode. */} else if (type == RDB_OPCODE_EXPIRETIME_MS) {expiretime = rdbLoadMillisecondTime(rdb,rdbver);if (rioGetReadError(rdb)) goto eoferr;continue; /* Read next opcode. */} else if (type == RDB_OPCODE_FREQ) {uint8_t byte;if (rioRead(rdb,&byte,1) == 0) goto eoferr;lfu_freq = byte;continue; /* Read next opcode. */} else if (type == RDB_OPCODE_IDLE) {/* IDLE: LRU idle time. */uint64_t qword;if ((qword = rdbLoadLen(rdb,NULL)) == RDB_LENERR) goto eoferr;lru_idle = qword;continue; /* Read next opcode. */} else if (type == RDB_OPCODE_EOF) {/* EOF: End of file, exit the main loop. */break;} else if (type == RDB_OPCODE_SELECTDB) {/* SELECTDB: Select the specified database. */if ((dbid = rdbLoadLen(rdb,NULL)) == RDB_LENERR) goto eoferr;if (dbid >= (unsigned)server.dbnum) {exit(1);}db = server.db+dbid;continue; /* Read next opcode. */}//还有很多else if,判断了很多情况..............................}//当 RDB 文件版本大于等于 5 时,检验 CRC64if (rdbver >= 5) {uint64_t cksum, expected = rdb->cksum;if (rioRead(rdb,&cksum,8) == 0) goto eoferr;if (server.rdb_checksum && !server.skip_checksum_validation) {memrev64ifbe(&cksum);.........................}}
}