1. 引言
尽管关于使用Deepspeed的Zero策略的博客已经满天飞了,特别是有许多经典的结论都已经阐述了,今天仍然被问到说,如果我只有4块40G的A100,能否进行全量的7B的大模型微调呢?
正所谓“纸上得来终觉浅,绝知此事要躬行。”不能以“何不食肉糜?”来回复人家说,为啥不用4块80G的A100呢。我们也知道,如果手上有3090/4090级别的显卡,那基本上就是走lora训练,没有任何问题。如果有4块80G的A100,则闭眼走全量微调。但是如果有4块40G的A100呢?甚至说4块32G的V100行不行呢?
先说结论,可以!
2. 背景知识介绍
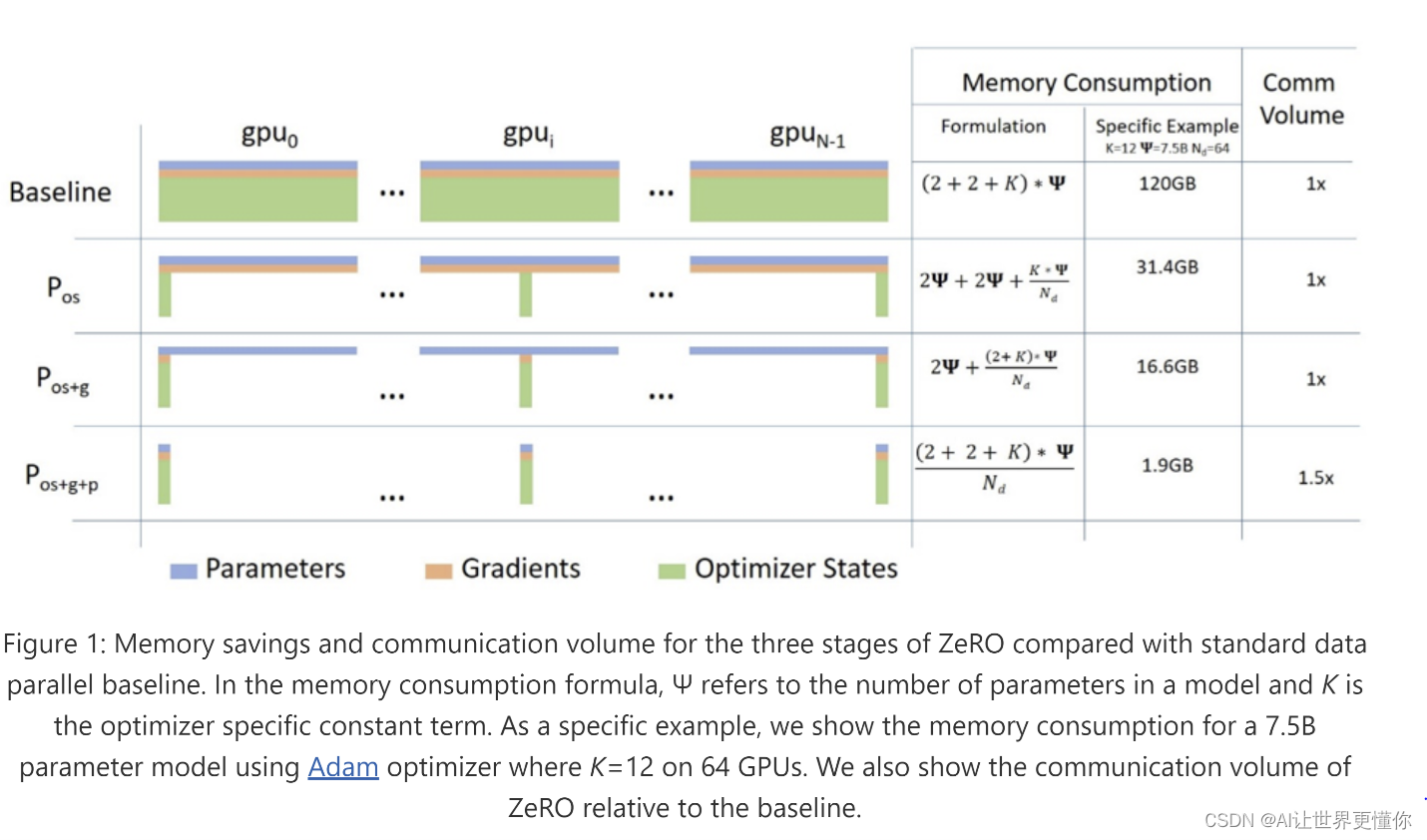
说到Deepspeed和Zero,相信大家对着一幅图一点都不陌生,被各个帖子广为传颂,用于介绍Zero-1/2/3之间的不同,非常形象直观,如果还想深入了解,参见《deepspeed官方介绍》(看一下,2021年Deepspeed就有这工具了,现在反而成了训练大模型的流行工具)。
2. 实验设置
我这里使用了1个50K样本的对话数据集,长度截断为1024,训练3个epoch,使用LLama_factory的脚本进行baichuan2的训练。其中zero_3的配置文件如下所示:
{"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": "auto","gradient_clipping": "auto","zero_allow_untested_optimizer": true,"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"bf16": {"enabled": "auto"},"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": true}
}
在4卡A100上,各个模式的训练情况如下:
| 模式 | batch大小 | 显存占用最大GPU | 训练时间 |
|---|---|---|---|
| Zero-3 | batch=2, accu=2 | 68GB | 15小时 |
| Zero-3 offloading param | batch=2, accu=2 | 21G | 41小时 |
| Zero-3 offloading optimizer+param | batch=2, accu=2 | 17G | 44小时 |
| Zero-3 offloading optimizer+param | batch=4, accu=4 | 21G | 13小时 |
| Zero-3 offloading optimizer+param | batch=8, accu=4 | 35G | 7小时 |
尽管使用了更大的batch_size可以更快地训练,但是最后一行需要50G的物理内存和100G的虚拟内存作为支撑。如果硬盘和内存的性能都不高的话,会更差一些。
因此,通过实验,我们可以知道,使用40G的A100也是可以训练的,但是通过offloading的方式可以将优化器和参数都存放到内存上,缓解显存占用情况。《Zero各个stage的状态详解》和《Zero的基础验算》会给出一个理论计算结果。
3. 其他一些训练小Tricks
3.1 使用offloading遇到AttributeError: ‘DeepSpeedCPUAdam‘ object has no attribute ‘ds_opt_adam错误
这是由于cuda和cuda tookit的版本不一致造成的,理论上,nvidia-smi的cuda版本优先级比nvcc -V的cuda版本优先级要高,因此nvidia-smi的cuda是硬约束条件,需要保证nvcc -V的cuda版本<=nvidia-smi的cuda版本。在此基础上,就可以使用《deepspeed使用zero3 + offload报错》提供的方案:
export DS_SKIP_CUDA_CHECK=1
来解决这个错误,将此变为警告。
如果想本质解决这个问题,而又有管理员权限的话,可以考虑映射一下两者,具体参考《nvcc和cuda版本不一致问题怎么解决》。
3.2 使用offloading报错RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and CPU!
这是由于Deepspeed V0.14.1的BUG导致的,回退到V0.14.0即可。也可以参见DeepSpeed的issues。(这是一个好习惯,首先先看项目的Issue里有没有相关问题。)
3.3 训练策略
将batch_size设置为1,通过梯度累积实现任意的有效batch_size
如果OOM则,设置–gradient_checkpointing 1 (HF Trainer),或者 model.gradient_checkpointing_enable()
如果OOM则,尝试ZeRO stage 2
如果OOM则,尝试ZeRO stage 2 + offload_optimizer
如果OOM则,尝试ZeRO stage 3
如果OOM则,尝试offload_param到CPU
如果OOM则,尝试offload_optimizer到CPU
如果OOM则,尝试降低一些默认参数。比如使用generate时,减小beam search的搜索范围
如果OOM则,使用混合精度训练,在Ampere的GPU上使用bf16,在旧版本GPU上使用fp16
如果仍然OOM,则使用ZeRO-Infinity ,使用offload_param和offload_optimizer到NVME
一旦使用batch_size=1时,没有导致OOM,测量此时的有效吞吐量,然后尽可能增大batch_size
开始优化参数,可以关闭offload参数,或者降低ZeRO stage,然后调整batch_size,然后继续测量吞吐量,直到性能比较满意(调参可以增加66%的性能)
3.4 训练速度和显存需求
从左到右,越来越慢
Stage 0 (DDP) > Stage 1 > Stage 2 > Stage 2 + offload > Stage 3 > Stage 3 + offloads
从左到右,所需GPU显存越来越少
Stage 0 (DDP) < Stage 1 < Stage 2 < Stage 2 + offload < Stage 3 < Stage 3 + offloads
关于Zero-0/1/2/3/infinity的配置文件样例,参见《Deepspeed详解》和《分布式训练实践》。