spark官网关于spark有状态编程介绍比较少,本文是一篇个人理解关于spark状态编程。
官网关于状态编程代码例子:
spark/examples/src/main/scala/org/apache/spark/examples/sql/streaming/StructuredComplexSessionization.scala at v3.5.0 · apache/spark (github.com)
一般的流计算使用窗口函数可以解决大部分问题,但是一些比较复杂的业务,窗口函数无法解决,比如需要的数据范围大于你设定的时间窗口,那么就需要状态编程处理中间状态。
案例:
数据一秒一条被spark消费,我需要找到的绿色部分代表再生(再生开始PFltRgn_stRgnActv,PFltRgn_stRgnActvHld变为两个1,再生结束变为两个0),我需要知道PFltRgn_ctRgnSuc再生阶段变化是否大于等于2(true: 意味再生成功)
如果开一个5s滚动窗口(红色框框),窗口内无法解决这个需求,那么我就需要记录每个窗口中当符合再生条件(绿色)PFltRgn_ctRgnSuc的最小值和最大值(这个就是中间状态)
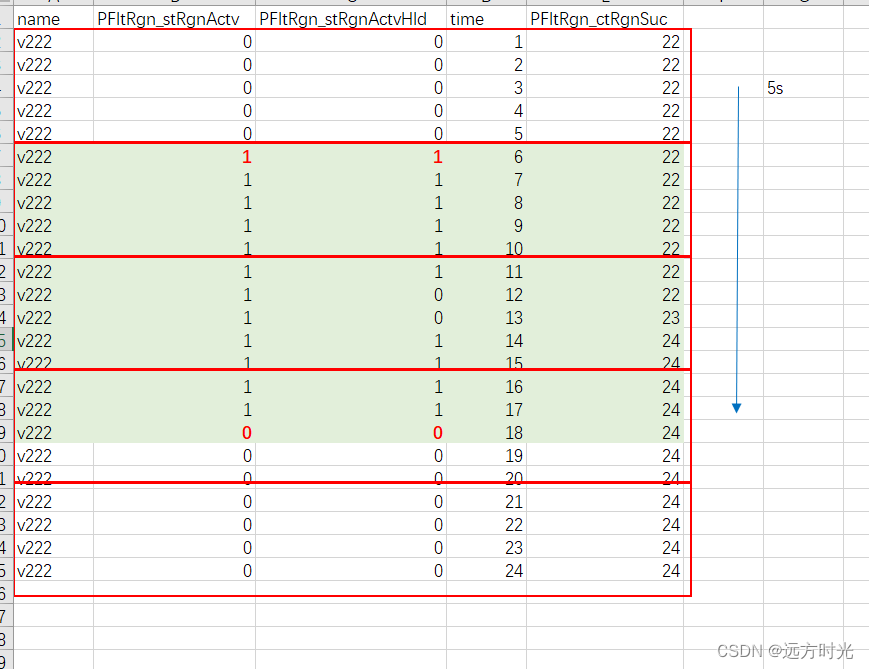
代码调试中:.....