题目详情:

解法一:暴力枚举
对于这道题,我们的第一思路就是暴力枚举,我们可以写一个四层的for循环进行暴力匹配,只要相加的结果等于0就进行统计。但是我们会发现,我们的事件复杂度为O(N^4)事件复杂度非常大,所以如果使用这个思路进行问题的解决一定会超时,所以我们采用其他思路进行题目的解答操作。
解法二:暴力枚举内部优化
对于这道题目来说,我第一感觉就是对暴力枚举策略进行优化操作。进行思考,我们会发现最内层的循环我们可以将其使用二分查找的算法进行优化,让我们的时间复杂度变成O(N^3*logN),对于重复的数据,我们只需要从一点向四周进行展开即可。操作如下图所示:

但是我们在编写好代码之后会发现存在特殊情况,会使得我们的算法的时间复杂度恢复为O(N^4),特殊情况如下:
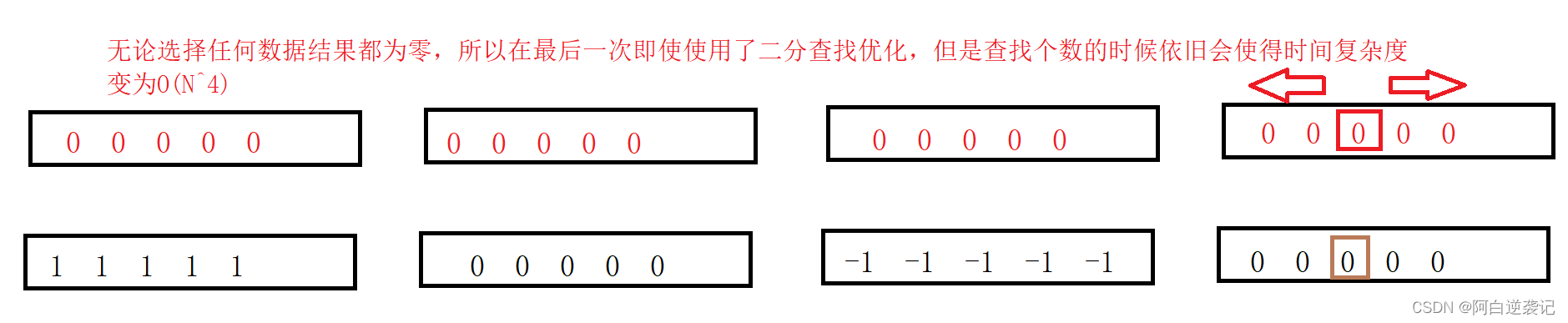
所以我们需要重新进行优化,我们可以提前对数组当中的数据进行处理,使用哈希表进行映射,哈希表的键为数组当中数据的值,哈希表的值为数组当中该值出现的次数。将上述代码实现结果如下:
class Solution {
public:int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {long long count = 0;long long target = 0;int n = nums1.size();//对数组当中的元素进行处理map<int, int> nums1Num;map<int, int> nums2Num;map<int, int> nums3Num;map<int, int> nums4Num;vector<vector<int>> nums1VNum;vector<vector<int>> nums2VNum;vector<vector<int>> nums3VNum;vector<vector<int>> nums4VNum;for (int i = 0; i < n; i++){nums1Num[nums1[i]]++;nums2Num[nums2[i]]++;nums3Num[nums3[i]]++;nums4Num[nums4[i]]++;}//之后由于map不支持随机访问也就是无法使用二分查找进行优化,所以我们采用vector的二维数组进行代替map执行之后的操作,将数据转化进入vector当中for (auto e : nums1Num){nums1VNum.push_back({ e.first,e.second });}for (auto e : nums2Num){nums2VNum.push_back({ e.first,e.second });}for (auto e : nums3Num){nums3VNum.push_back({ e.first,e.second });}for (auto e : nums4Num){nums4VNum.push_back({ e.first,e.second });}for (int i = 0; i < nums1VNum.size(); i++){for (int j = 0; j < nums2VNum.size(); j++){for (int k = 0; k < nums3VNum.size(); k++){//之后对最后一个数组进行优化target = 0 - (long long)nums1VNum[i][0] - nums2VNum[j][0] - nums3VNum[k][0];//也就是需要在最后一个数组当中查找target数据int left = 0;int right = nums4VNum.size() - 1;while (left <= right){int mid = left + (right - left) / 2;if (nums4VNum[mid][0] == target){//从mid开始向左右进行查找符合条件的数据count = count + nums1VNum[i][1] * nums2VNum[j][1] * nums3VNum[k][1] * nums4VNum[mid][1];break;}else if (nums4VNum[mid][0] > target){right = mid - 1;}else{left = mid + 1;}}}}}return count;
} //存在一个可以进行优化的算法
};
但是我的的代码依旧不能通过测试,代码运行的时间依旧过长,所以我们需要重新整理思路进行问题的解决。
解法三:两两合并法
在官方题解当中我们可以学到一个解法:我们可以将四个数组分成为两个一组的形式,将一组当中的两个数组进行相加合并,将两个数组当中的元素进行完全匹配相加,合并之后就可以将两组新的数据进行匹配,之后就可以将题目的要求修改为两个数组查找指定的值。需要注意的是:我们同样需要使用哈希表进行数据的处理,以提高代码的运行速率。
我们会发现这种算法的时间复杂度为O(N^2),其主要需要进行的操作就是数组的合并,以及之后的数据查找操作。根据上述思路所编写的代码如下所示:
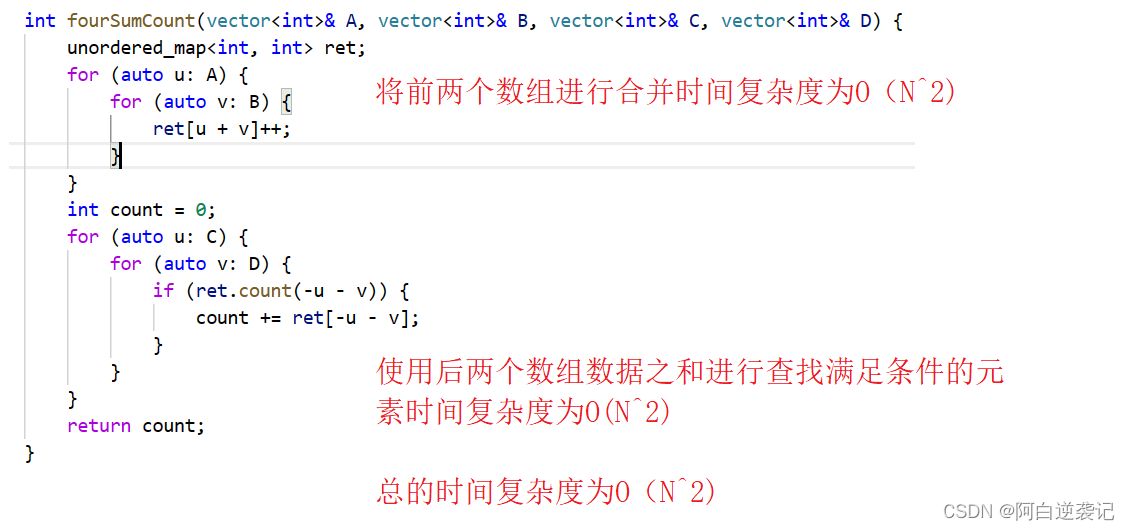
class Solution {
public:int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {unordered_map<int, int> ret;for (auto u: A) {for (auto v: B) {ret[u + v]++;}}int count = 0;for (auto u: C) {for (auto v: D) {if (ret.count(-u - v)) {count += ret[-u - v];}}}return count;}
}; 时间复杂度分析: