模型体验
体验链接:
https://modelscope.cn/studios/qwen/Qwen1.5-110B-Chat-demo
为了便于大家比较,社区搭建了Llama3-70B-Instruct和Qwen1.5-110B-Chat的对比环境,体验链接:
https://www.modelscope.cn/studios/LLM-Research/Llama3-Qwen1.5-Arena
例如,多语言能力:

小学数学so easy:
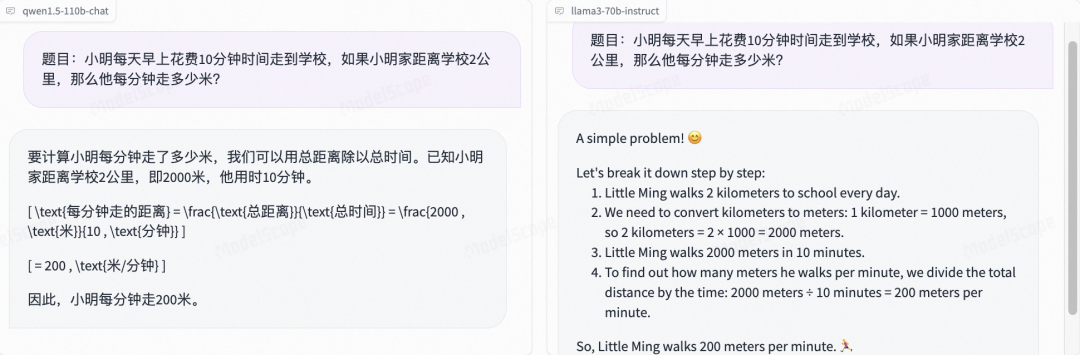
再难一点也不在话下:

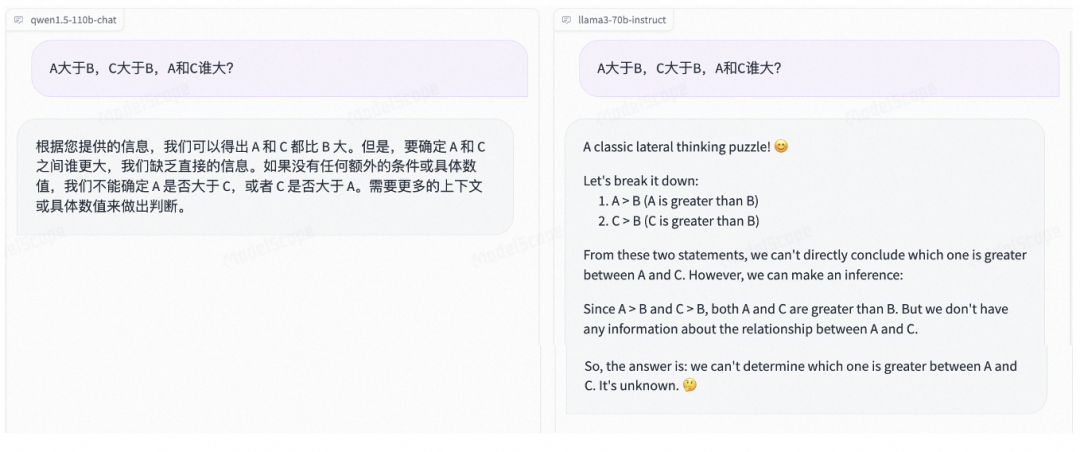
逻辑能力:
模型实战
模型下载
模型链接:
Qwen1.5-110B-Chat:
https://www.modelscope.cn/models/qwen/Qwen1.5-110B-Chat
Qwen1.5-110B:
https://www.modelscope.cn/models/qwen/Qwen1.5-110B
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen1.5-110B-Chat')模型推理
推理代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model ontomodel = AutoModelForCausalLM.from_pretrained("qwen/Qwen1.5-110B-Chat",torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen1.5-110B-Chat")prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
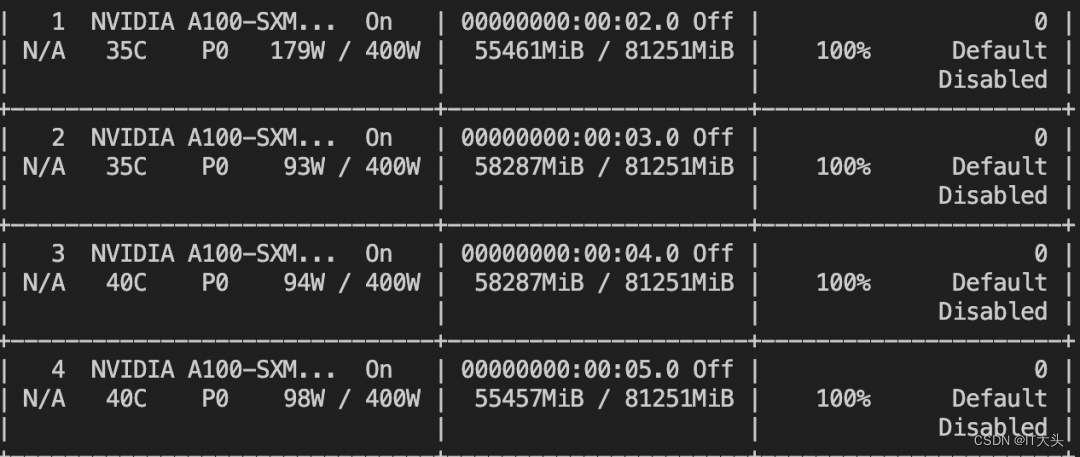
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]显存要求(4卡A100,230G显存):
模型训练
魔搭社区的微调框架SWIFT已经支持了Qwen1.5全系列模型的微调和推理。
下面我们以自我认知任务为例针对千问1.5-110b-chat模型为例给出训练参数配置:
nproc_per_node=4
CUDA_VISIBLE_DEVICES=0,1,2,3 \
NPROC_PER_NODE=$nproc_per_node \
swift sft \--model_type qwen1half-110b-chat \--sft_type lora \--tuner_backend peft \--dtype AUTO \--output_dir output \--ddp_backend nccl \--num_train_epochs 2 \--max_length 2048 \--check_dataset_strategy warning \--lora_rank 8 \--lora_alpha 32 \--lora_dropout_p 0.05 \--lora_target_modules ALL \--gradient_checkpointing true \--batch_size 1 \--weight_decay 0.1 \--learning_rate 1e-4 \--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \--max_grad_norm 0.5 \--warmup_ratio 0.03 \--eval_steps 100 \--save_steps 100 \--save_total_limit 2 \--logging_steps 10 \--use_flash_attn true \--deepspeed default-zero3 \--self_cognition_sample 2000 \--model_name 小白 'Xiao Bai' \--model_author AI 疯人院 \训练loss:
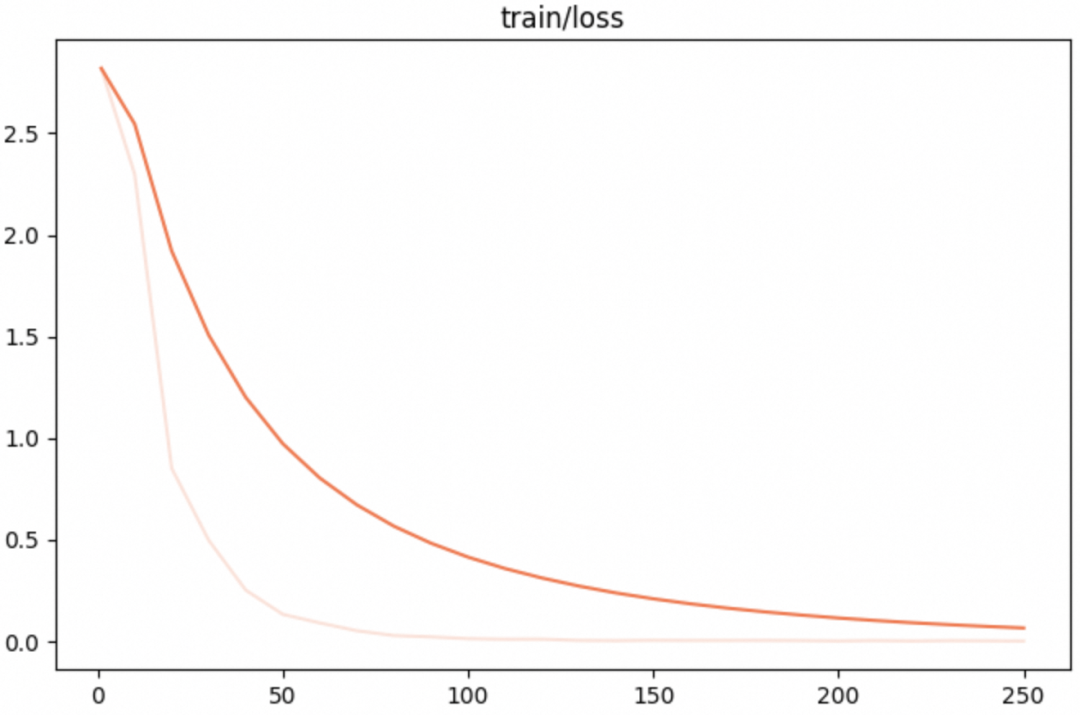
可以看到其收敛非常平滑。
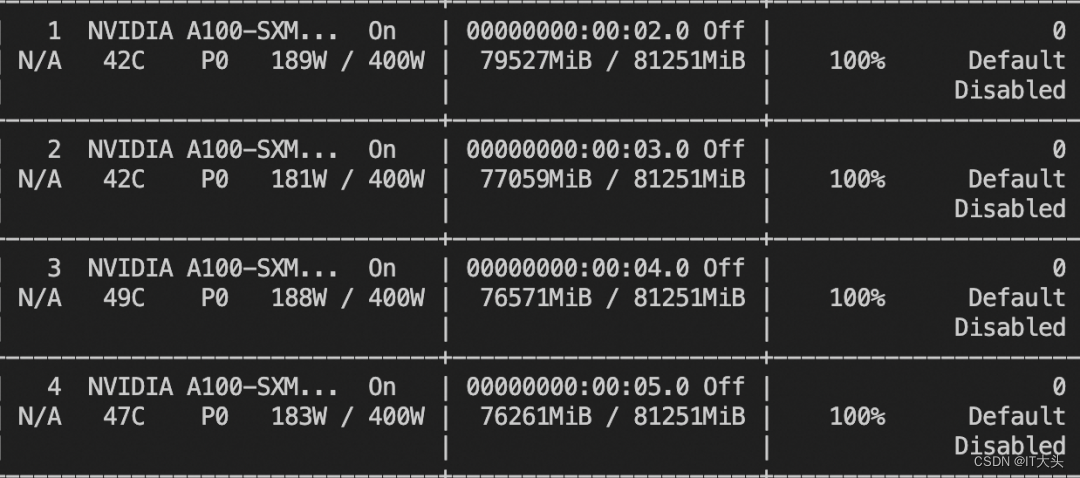
训练的显存使用情况:
训练后推理可以使用如下脚本(注意将--ckpt_dir替换为训练log输出的weights路径):
# Experimental environment: 4*A100
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift infer \--ckpt_dir "/output/qwen1half-110b-chat/vx-xxx/checkpoint-xx" \--load_dataset_config true \--max_length 2048 \--eval_human true \--use_flash_attn false \--max_new_tokens 2048 \--temperature 0.1 \--top_p 0.7 \--repetition_penalty 1. \--do_sample true \--merge_lora_and_save false \自我认知对话测试:

通用对话测试:

交流群进群方式--->关注公众号(AI疯人院) 输入框输入--->加群 或点击讨论交流