⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
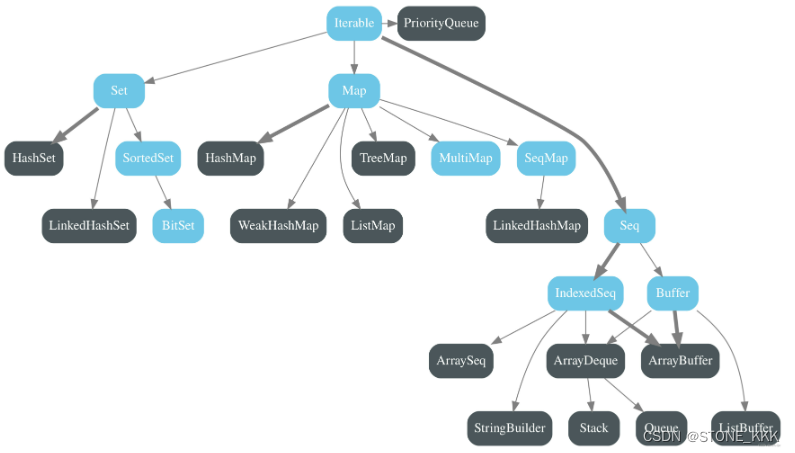
语音识别--单声道转换与降采样
- 单声道转换与降采样
- 一、任务需求
- 二、任务目标
- 1、掌握单声道转化方法
- 2、掌握音频降采样方法
- 三、任务环境
- 1、jupyter开发环境
- 2、python3.6
- 3、tensorflow2.4
- 四、任务实施过程
- 1、单声道转换
- 2、降采样
- 五、任务小结
- 说明
单声道转换与降采样
一、任务需求
在本实验中,我们将通过平均跨通道的样本将音频信号转换为单声道。
从应用的角度上看,多声道转单声道,与降采样都可以有效降低音频的大小,当然,伴随而来的是质量下降。但很多情况下,并不是越清晰的音频越好,因此单声道转换和降采样就能够派上大用途了。
要求:在librosa中,使用函数librosa.to_mono实现单声道转换的功能。
二、任务目标
1、掌握单声道转化方法
2、掌握音频降采样方法
三、任务环境
1、jupyter开发环境
2、python3.6
3、tensorflow2.4
四、任务实施过程
1、单声道转换
import librosa
filename = '/home/jovyan/datas/sorohanro_-_solo-trumpet-06.hq.ogg'
y, sr = librosa.load(filename, mono=False)
y.shape
(2, 117601)
从音频的shape上看得出来,这是一个双声道的音频。
为了让你能看的更加清晰,对声道变换理解的更加透彻,我们在这里将双声道声波绘制出来。
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
# 绘制双声道声波第一个通道
plt.subplot(2,1,1)
plt.plot(y[0,:1000])
# 绘制双声道声波第二个通道
plt.subplot(2,1,2)
plt.plot(y[1,:1000],c='g')
这是同一个音频文件的双声道声波图,接下来我们要将双声道音频,转化为单声道。转化方法非常简单,通过librosa.to_mono就可以实现。
y_mono = librosa.to_mono(y)
y_mono.shape
(117601,)
plt.figure(figsize=(15,2))
# 将双声道合并为一个通道
plt.plot(y_mono[:1000],c='r')
2、降采样
filename = '/home/jovyan/datas/sorohanro_-_solo-trumpet-06.ogg'
# 获取采样率
sr = librosa.get_samplerate(filename)
sr
22050
y, sr = librosa.load(filename, sr=sr, mono=False) len(y),sr
(117601, 22050)
# 使用resample降采样
y_8k = librosa.resample(y, sr, 8000)
y.shape, y_8k.shape
((117601,), (42668,))
可以看到,经过librosa.resample降采样后的音频采样点,从117601降低到42668,降低一半还多。
当然,降采样的采样率并不能随意减少,想象一下,一个音频文件,只有一个采样点会怎样?所以通常来说,在音频的一个最小周期上,至少要保证两个采样点才可以。
为了比较降采样前后的变化,我们播放两个声音。
import IPython.display as ipd
ipd.display(ipd.Audio(y,rate=22050))
ipd.display(ipd.Audio(y_8k,rate=8000))
听起来好像并没什么不同,为了加强确认,我们画出波形图看一看。
plt.figure(figsize=(14,4))
plt.subplot(211)
plt.plot(y)
plt.subplot(212)
plt.plot(y_8k)
五、任务小结
本节实验我们学习了如何将双声道转换为单声道,并学习了音频降采样方法。
从波形图上看,两个声音在细微上还是存在一些不同,但差距不大,如果并不是特别追求音频质量的话,显然8k音频也是能用的,最关键的是,文件大小缩小了一半有余。
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我