一、下载spark和kyuubi的软件包
spark官网下载
https://spark.apache.org/downloads.html
kyuubi官网下载
https://www.apache.org/dyn/closer.lua/kyuubi/kyuubi-1.9.0/apache-kyuubi-1.9.0-bin.tgz
二、部署spark
1、spark配置spark-env.sh
YARN_CONF_DIR=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop/etc/hadoop
2、spark中使用hive元数据,需添加hive的hive-site.xml
三、配置kyuubi环境
1、kyuubi-defaults.conf
y
kyuubi.frontend.bind.host bigdata30
kyuubi.frontend.protocols THRIFT_BINARY,REST
kyuubi.frontend.thrift.binary.bind.port 10009
# kyuubi.frontend.rest.bind.port 10099
#
kyuubi.engine.type SPARK_SQL
kyuubi.engine.share.level USER
# kyuubi.session.engine.initialize.timeout PT3M# 高可用
kyuubi.ha.enabled true
kyuubi.ha.client.class org.apache.kyuubi.ha.client.zookeeper.ZookeeperDiscoveryClient kyuubi.ha.addresses bigdata30:2181,bigdata31:2181,bigdata32:2181
kyuubi.ha.namespace kyuubi# 如果启动了kerberos需要配置如下# kyuubi.ha.zookeeper.auth.type KERBEROSkyuubi.ha.zookeeper.auth.principal zookeeper/_HOST@HADOOP.COM
kyuubi.ha.zookeeper.auth.keytab /etc/security/keytabs/zookeeper.keytab# kyuubi 启动kerberos认证配置
kyuubi.authentication KERBEROS
kyuubi.kinit.principal hive/_HOST@HADOOP.COM
kyuubi.kinit.keytab /etc/security/keytabs/hive.keytab #kyuuibi pool
kyuubi.backend.engine.exec.pool.size 30
kyuubi.backend.engine.exec.pool.wait.queue.size 100#spark
spark.master yarn
# spark.driver.memory 2g
# spark.executor.memory 4g
# spark.driver.cores 1
# spark.executor.cores 3#spark sql优化
spark.sql.adaptive.enabled true
spark.sql.adaptive.forceApply false
spark.sql.adaptive.logLevel info
spark.sql.adaptive.advisoryPartitionSizeInBytes 256m
spark.sql.adaptive.coalescePartitions.enabled true
spark.sql.adaptive.coalescePartitions.minPartitionNum 1
spark.sql.adaptive.coalescePartitions.initialPartitionNum 1
spark.sql.adaptive.fetchShuffleBlocksInBatch true
spark.sql.adaptive.localShuffleReader.enabled true
spark.sql.adaptive.skewJoin.enabled true
spark.sql.adaptive.skewJoin.skewedPartitionFactor 5
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 400m
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin 0.2
# spark.sql.adaptive.optimizer.excludedRules
spark.sql.autoBroadcastJoinThreshold -1
# Details in https://kyuubi.readthedocs.io/en/master/configuration/settings.html# #静态资源申请
# spark.executor.instances 2
# spark.executor.cores 2
# spark.executor.memory 2g# 动态资源申请
spark.dynamicAllocation.enabled true
# # ##false if prefer shuffle tracking than ESS
# spark.shuffle.service.enabled true
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 5
# spark.executor.cores 3
# spark.exevutor.memory 4g
spark.dynamicAllocation.executorAllocationRatio 0.5
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.cachedExecutorIdleTimeout 30min
# true if prefer shuffle tracking than ESS
spark.dynamicAllocation.shuffleTracking.enabled true
spark.dynamicAllocation.shuffleTracking.timeout 30min
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 1s
spark.cleaner.periodicGC.interval 5min
# # For a user named kent
# ___hive___.spark.dynamicAllocation.maxExecutors 10
2、kyuubi-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131
export SPARK_HOME=/home/soft/spark-3.5.1-bin-hadoop3
# export FLINK_HOME=/opt/flink
export HIVE_HOME=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hive
# export FLINK_HADOOP_CLASSPATH=/path/to/hadoop-client-runtime-3.3.2.jar:/path/to/hadoop-client-api-3.3.2.jar
# export HIVE_HADOOP_CLASSPATH=${HADOOP_HOME}/share/hadoop/common/lib/commons-collections-3.2.2.jar:${HADOOP_HOME}/share/hadoop/client/hadoop-client-runtime-3.1.0.jar:${HADOOP_HOME}/share/hadoop/client/hadoop-client-api-3.1.0.jar:${HADOOP_HOME}/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar
export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop
export YARN_CONF_DIR=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop/etc/hadoop
export KYUUBI_JAVA_OPTS="-Xmx10g -XX:MaxMetaspaceSize=512m -XX:MaxDirectMemorySize=1024m -XX:+UseG1GC -XX:+UseStringDeduplication -XX:+UnlockDiagnosticVMOptions -XX:+UseCondCardMark -XX:+UseGCOverheadLimit -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./logs -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -verbose:gc -Xloggc:./logs/kyuubi-server-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=20M"
export KYUUBI_BEELINE_OPTS="-Xmx2g -XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+UseCondCardMark"
3、创建keytab文件到配置指定路径
如果是高可用的每个机器放置好keytab文件
[root@bigdata31 ~]# ll /etc/security/keytabs/
总用量 12
-rw-r--r-- 1 root root 970 4月 28 23:12 hive.keytab
-rw-r--r-- 1 root root 1040 4月 28 21:47 zookeeper.keytab4、启动与关闭
sudo -u hive bin/kyuubi start
sudo -u hive bin/kyuubi stop
或则
sudo -u hive bin/kyuubi restart四、测试连接
1、beline连接
1.1、非ha方式
[root@bigdata30 apache-kyuubi-1.9.0-bin]# beeline -u 'jdbc:hive2://bigdata30:10009/;principal=hive/_HOST@HADOOP.COM'
Connecting to jdbc:hive2://bigdata30:10009/;principal=hive/_HOST@HADOOP.COM
Connected to: Spark SQL (version 3.5.1)
Driver: Hive JDBC (version 2.1.1-cdh6.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.1.1-cdh6.2.1 by Apache Hive
0: jdbc:hive2://bigdata30:10009/>
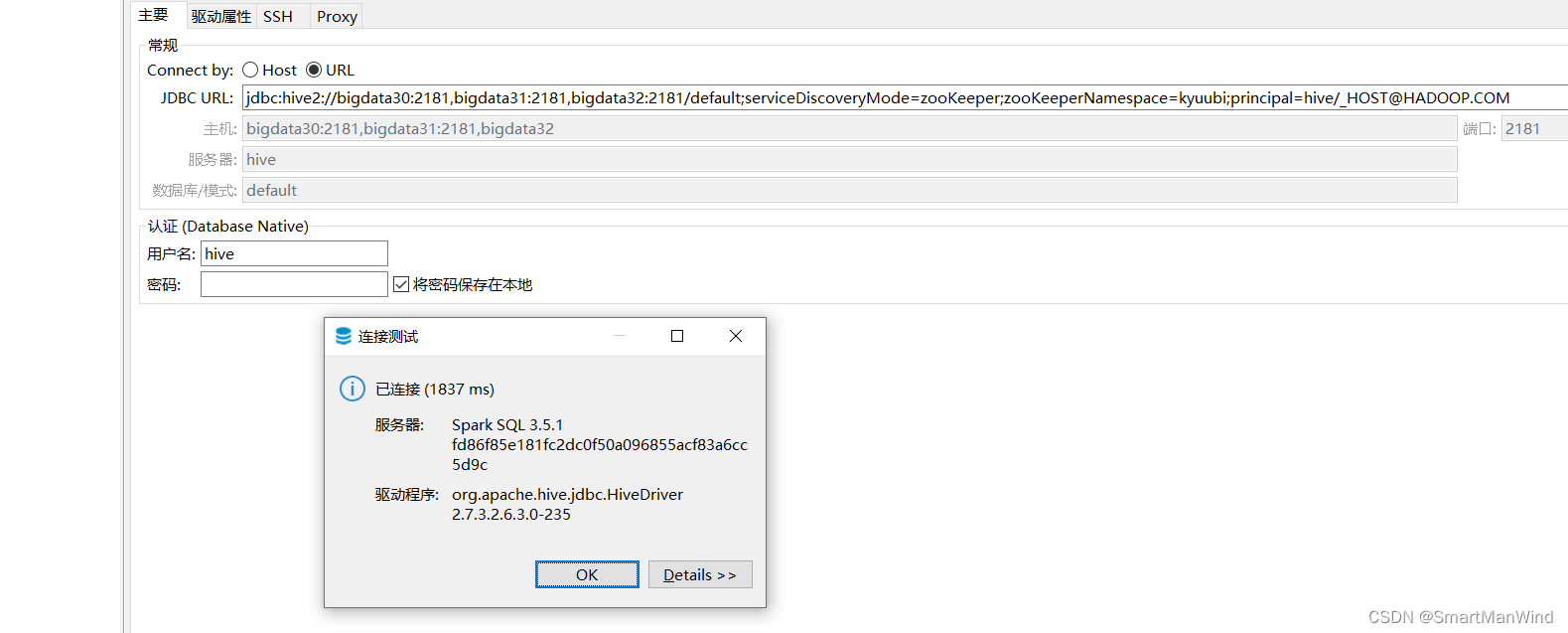
1.2、ha方式连接
beeline -u 'jdbc:hive2://bigdata30:2181,bigdata31:2181,bigdata32:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi;principal=hive/_HOST@HADOOP.COM'
[root@bigdata30 apache-kyuubi-1.9.0-bin]# beeline -u 'jdbc:hive2://bigdata30:2181,bigdata31:2181,bigdata32:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi;principal=hive/_HOST@HADOOP.COM'
Connecting to jdbc:hive2://bigdata30:2181,bigdata31:2181,bigdata32:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi;principal=hive/bigdata30@HADOOP.COM
24/04/28 22:56:40 [main]: INFO jdbc.HiveConnection: Connected to 10.8.3.30:10009
Connected to: Spark SQL (version 3.5.1)
Driver: Hive JDBC (version 2.1.1-cdh6.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.1.1-cdh6.2.1 by Apache Hive
0: jdbc:hive2://bigdata30:2181,bigdata31:2181>2、dbeaver连接
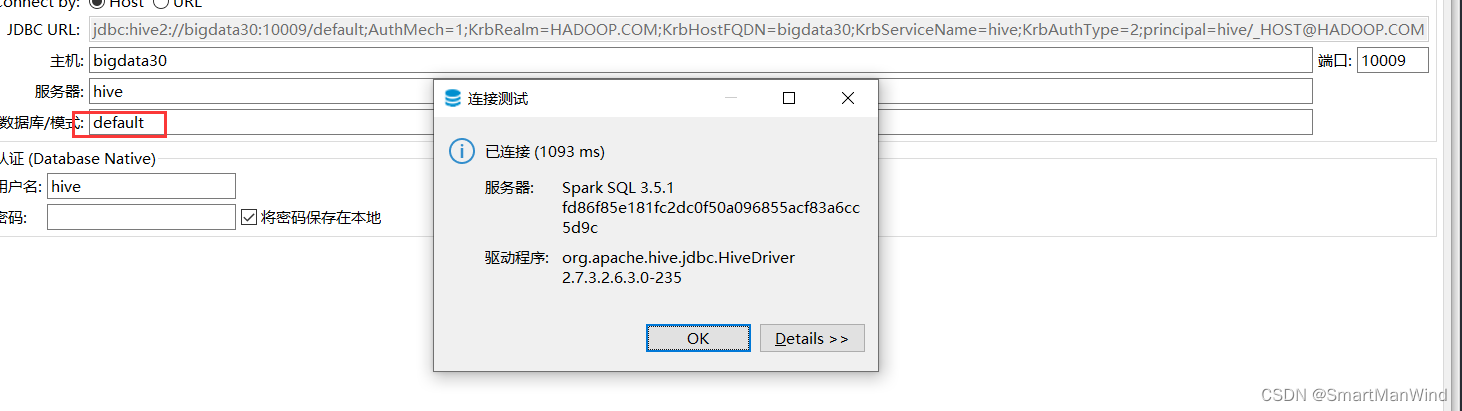
软件包 hive-jdbc-uber-2.6.3.0-235.jar
2.1、非ha连接
url模板
jdbc:hive2://{host}[:{port}][/{database}];AuthMech=1;KrbRealm=HADOOP.COM;KrbHostFQDN={host};KrbServiceName={server};KrbAuthType=2;principal={user}/_HOST@HADOOP.COM
连接信息
jdbc:hive2://bigdata30:10009/default;AuthMech=1;KrbRealm=HADOOP.COM;KrbHostFQDN=bigdata30;KrbServiceName=hive;KrbAuthType=2;principal=hive/_HOST@HADOOP.COM
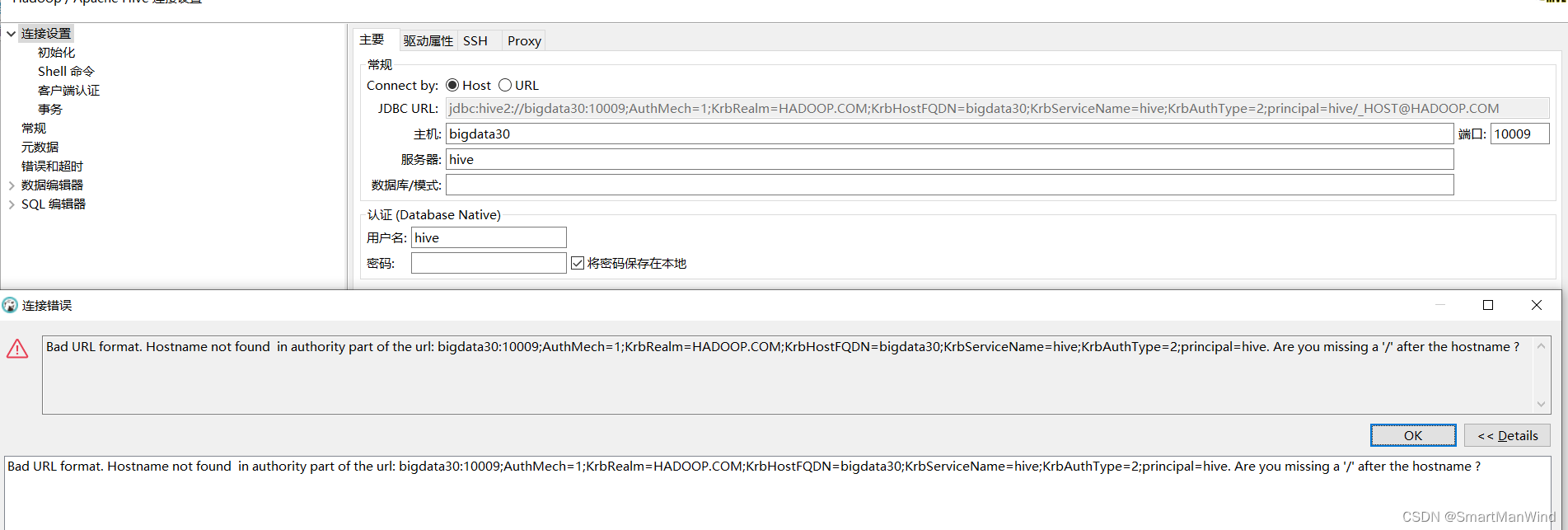
还有一种类似beline的连接方式,非常精简,看着清爽:
jdbc:hive2://{host}[:{port}][/{database}];principal={user}/_HOST@HADOOP.COM
jdbc:hive2://bigdata30:10009/default;principal=hive/_HOST@HADOOP.COM
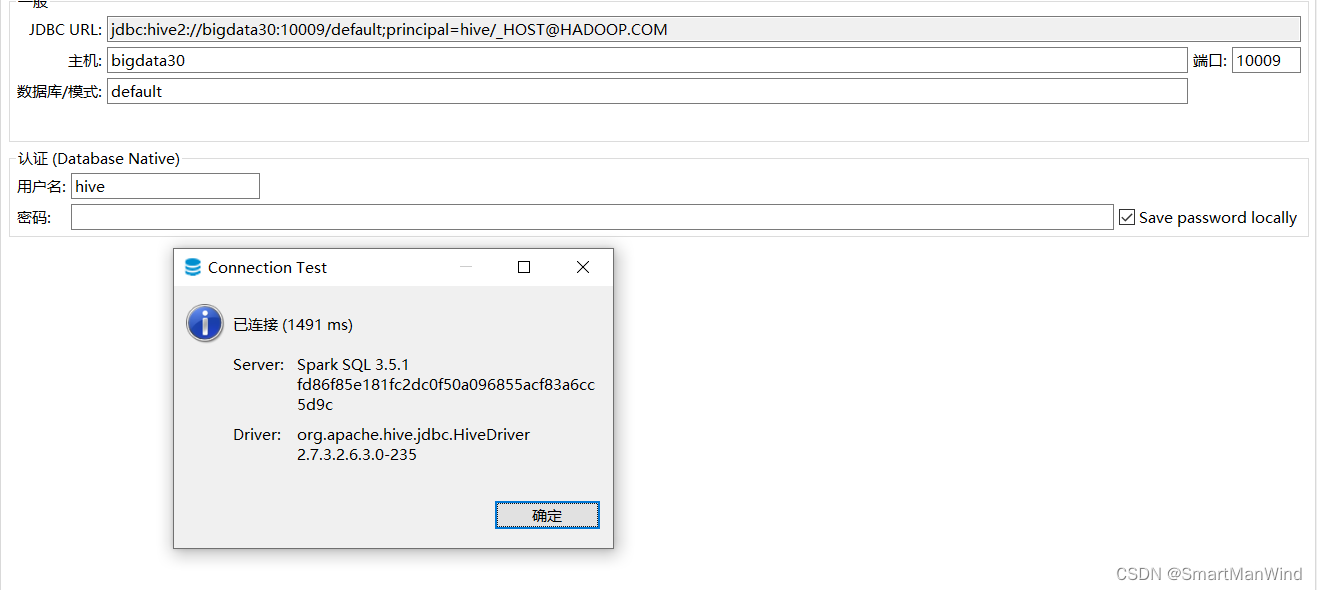
注意数据库信息必须填写,否则会报错
2.2、ha连接