匹配网络(Matching Networks)
- 深入解析:匹配网络(Matching Networks)的原理和应用
- 匹配网络的核心原理
- 工作原理
- 算法流程
- 匹配网络的实现
- 应用示例
- 结论
深入解析:匹配网络(Matching Networks)的原理和应用
在人工智能的领域中,匹配网络(Matching Networks)是一种专门设计来解决少样本学习问题的元学习方法。它们通过学习如何将新的未见过的样本与已知的少量样本进行比较和匹配,从而实现快速有效的学习。本篇博客将详细介绍匹配网络的工作原理、如何实现它们,以及它们在实际应用中的用途。
匹配网络的核心原理
匹配网络是一种端到端(end-to-end)的学习框架,设计用来直接从给定的支持集(support set)中学习样本之间的相似度,以便于对新样本进行分类。这种方法特别适合于处理那些只有非常少的标记数据可用的任务,例如,在医学图像识别或者语种识别中常常只有有限的样本可用。
工作原理
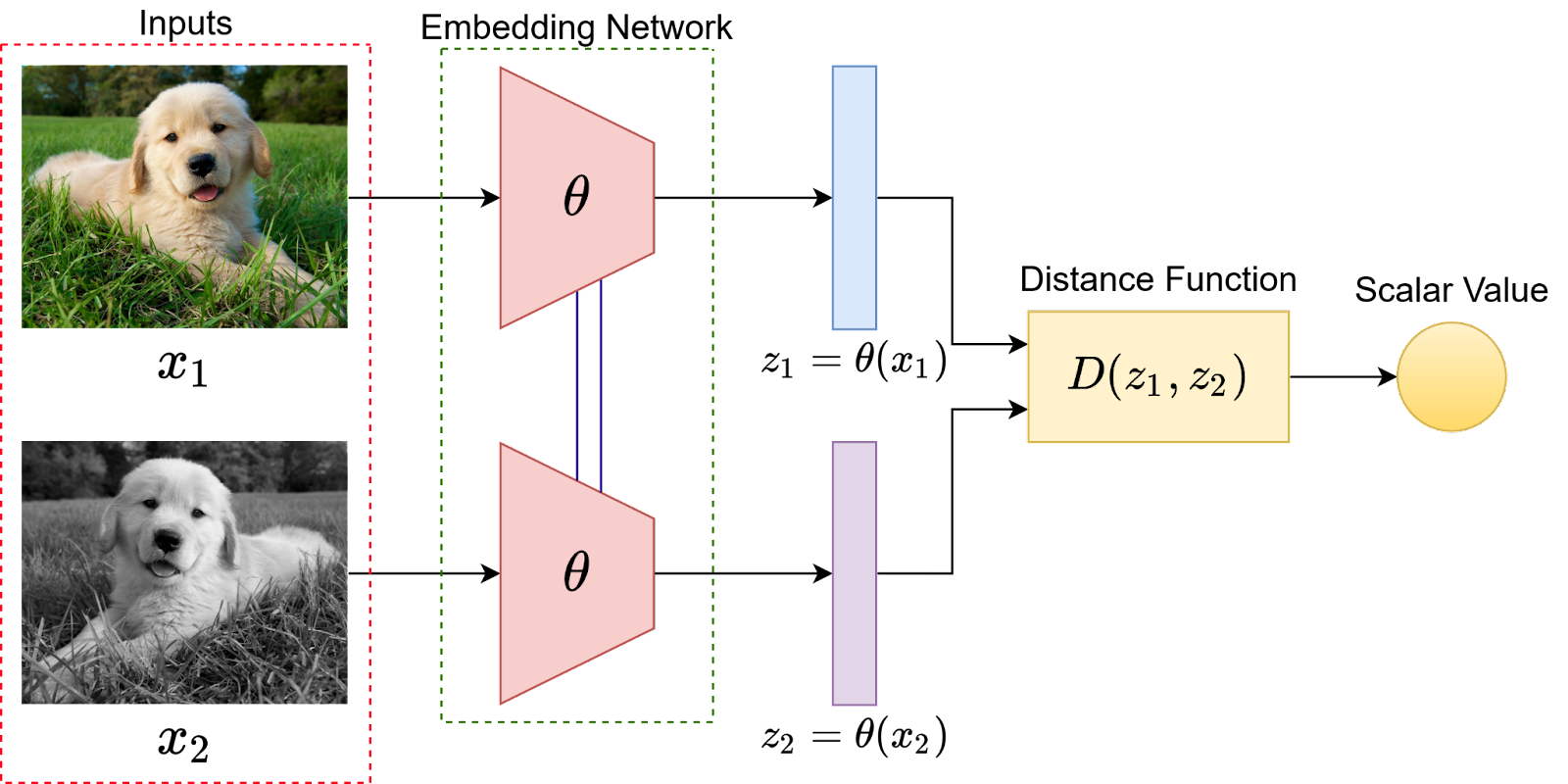
匹配网络的设计灵感来自于人类如何通过比较和匹配来快速学习新事物。它的核心是一个用于学习样本之间相似度的神经网络模型。在训练过程中,这种网络学会如何根据样本之间的相似度进行有效的权重分配,以预测未见样本的类别。
匹配网络使用了以下几个关键组件:
- 支持集(Support Set):这是一组已经标记好的样本,网络将使用这些样本来预测新样本的类别。
- 目标样本(Target Sample):这是需要被分类的新样本。
- 注意力机制(Attention Mechanism):用于计算支持集中每个样本与目标样本之间的相似度,并基于这些相似度分配权重。
算法流程
- 特征提取:首先,使用一个深度神经网络(通常是卷积神经网络,CNN)来提取支持集和目标样本的特征。
- 相似度计算:然后,计算目标样本的特征向量与支持集中每个样本的特征向量之间的相似度。
- 应用注意力机制:基于计算出的相似度,使用注意力机制为支持集中的每个样本分配一个权重。
- 分类:最后,根据加权后的支持集标签来预测目标样本的类别。
匹配网络的实现
匹配网络的实现通常涉及以下几个步骤:
- 数据准备:准备并预处理支持集和目标样本数据。
- 模型构建:构建用于特征提取的神经网络。
- 训练:通过最小化预测标签和真实标签之间的差异来训练网络。
- 评估和调优:在独立的验证集上评估模型的表现,并根据需要调整模型参数。
应用示例
匹配网络在许多需要处理少样本学习问题的领域都有应用,比如:
- 生物识别:如指纹识别、面部识别,在只有少数样本可用的情况下进行有效识别。
- 医学诊断:在仅有少量病例学习的情况下识别疾病。
- 自然语言处理:少样本翻译或少样本文本分类。
结论
匹配网络是一个强大的元学习工具,能够在少样本的情况下进行有效的快速学习。通过利用支持集来直接学习如何对新样本进行分类,匹配网络在多个领域展示了其强大的潜力。对于面对少样本学习挑战的研究者和开发者来说,掌握匹配网络的理论和实践是非常有价值的。