如何保证消息的可靠传输?如果消息丢了怎么办
数据的丢失问题,可能出现在生产者、MQ、消费者中。
(1)生产者发送消息时丢失:
①生产者发送消息时连接MQ失败
②生产者发送消息到达MQ后未找到Exchange(交换机)
③生产者发送消息到达MQ的Exchange后,未找到合适的Queue(队列)
④消息到达MQ后,处理消息的进程发生异常
(2)MQ导致消息丢失:
消息到达MQ,保存到队列后,尚未消费就突然宕机
(3)消费者处理消息时:
①消息接收后尚未处理突然宕机
②消息接收后处理过程中抛出异常
生产者丢失
(1)可以选择用 RabbitMQ 提供的事务功能,就是生产者发送数据之前开启RabbitMQ 事务channel.txSelect,然后发送消息,如果消息没有成功被RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务channel.txRollback,然后重试发送消息;如果收到了消息,那么可以提交事务channel.txCommit。这样会导致吞吐量下来,因为太耗性能。另一种方案就是:
(2)生产者发送消息时连接MQ失败可以开启生产者超时重试机制
(3)在少数情况下,也会出现消息发送到MQ之后丢失的现象,比如:生产者发送消息到达MQ后未找到Exchange、生产者发送消息到达MQ的Exchange后,未找到合适的Queue、消息到达MQ后,处理消息的进程发生异常。针对上述情况,RabbitMQ提供了Publisher Confirm和Publisher Return两种确认机制。在开启确认机制后,在MQ成功收到消息后会返回确认消息给生产者,返回的结果有以下几种情况:
①当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常原因,同时返回ack的确认信息,代表投递成功
②临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
③持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
④其它情况都会返回NACK,告知投递失败
其中ack和nack属于Publisher Confirm机制,ack是投递成功;nack是投递失败。而return则属于Publisher Return机制。默认两种机制都是关闭状态,需要通过配置文件来开启。
(4)publisher-confirm-type有三种模式可选:
①none:关闭confirm机制
②simple:同步阻塞等待MQ的回执
③correlated:MQ异步回调返回回执
一般我们推荐使用correlated,回调机制。
(5)事务机制和cnofirm机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是confirm机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息RabbitMQ 接收了之后会异步回调你一个接口通知你这个消息接收到了。所以一般在生产者这块避免数据丢失,都是用confirm机制的。
MQ中丢失
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:交换机持久化、队列持久化、消息持久化
消费者丢失
(1)消费者确认机制:
①为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制(Consumer Acknowledgement)。即:当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息(比如消息格式有问题),RabbitMQ从队列中删除该消息
②由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
- none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用
- manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活
- auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:
a.如果是业务异常,会自动返回nack;
b.如果是消息处理或校验异常,自动返回reject;
我们选择auto:自动模式即可
(2)失败重试机制
①当消费者出现异常后,消息会不断requeue(重新入队)到队列,再重新发送给消费者,然后再次异常,再次requeue到队列,无限循环,导致mq的消息处理飙升,带来不必要的压力:
②为了应对上述情况Spring又提供了消费者失败重试机制:在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
③开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试;重试达到最大次数后,Spring会返回reject,消息会被丢弃
④Spring允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义的,它有3个不同实现:
a.RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
b.ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
c.RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
(3)业务幂等性:幂等是一个数学概念,用函数表达式来描述是这样的:f(x) = f(f(x)),例如求绝对值函数。
在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。
-
方案一:给每个消息都设置一个唯一id,利用id区分是否重复消息
①每一条消息都生成一个唯一的id,与消息一起投递给消费者
②消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
③如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理
④我们该如何给消息添加唯一ID呢?
其实很简单,SpringAMQP的MessageConverter自带了MessageID的功能,我们只要开启这个功能即可 -
方案二:业务判断
业务判断就是基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。例如我们当前案例中,处理消息的业务逻辑是把订单状态从未支付修改为已支付。因此我们就可以在执行业务时判断订单状态是否是未支付,如果不是则证明订单已经被处理过,无需重复处理。
相比较而言,消息ID的方案需要改造原有的数据库,所以我更推荐使用业务判断的方案。
兜底方案
(1)虽然我们利用各种机制尽可能增加了消息的可靠性,但也不好说能保证消息100%的可靠。万一真的MQ通知失败该怎么办呢?有没有其它兜底方案,能够确保订单的支付状态一致呢?
(2)其实思想很简单:既然MQ通知不一定发送到交易服务,那么交易服务就必须自己主动去查询支付状态。这样即便支付服务的MQ通知失败,我们依然能通过主动查询来保证订单状态的一致
如何保证消息的顺序性
(1)先看看顺序会错乱的场景:RabbitMQ:一个 queue,多个 consumer,这不明显乱了;
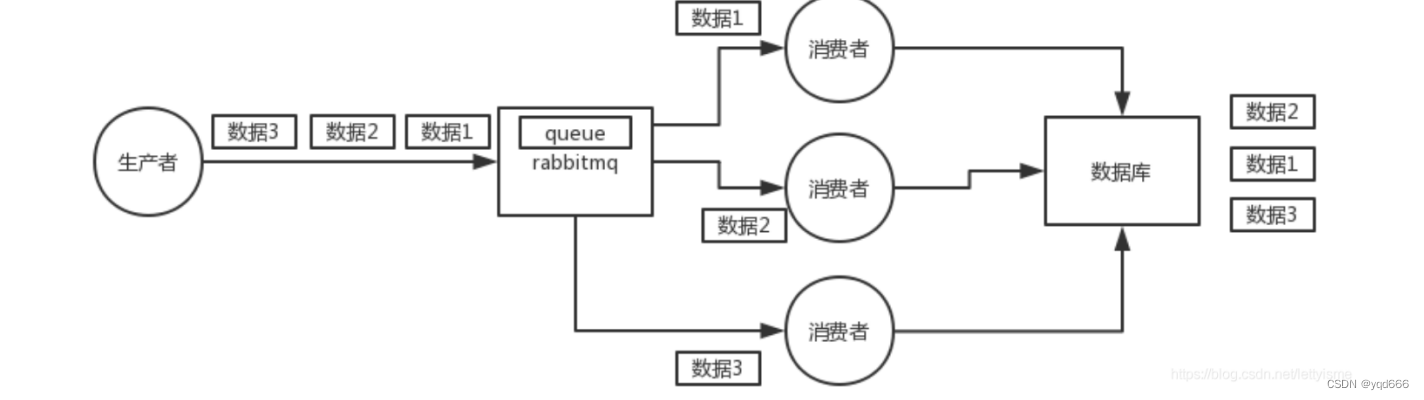
(2)解决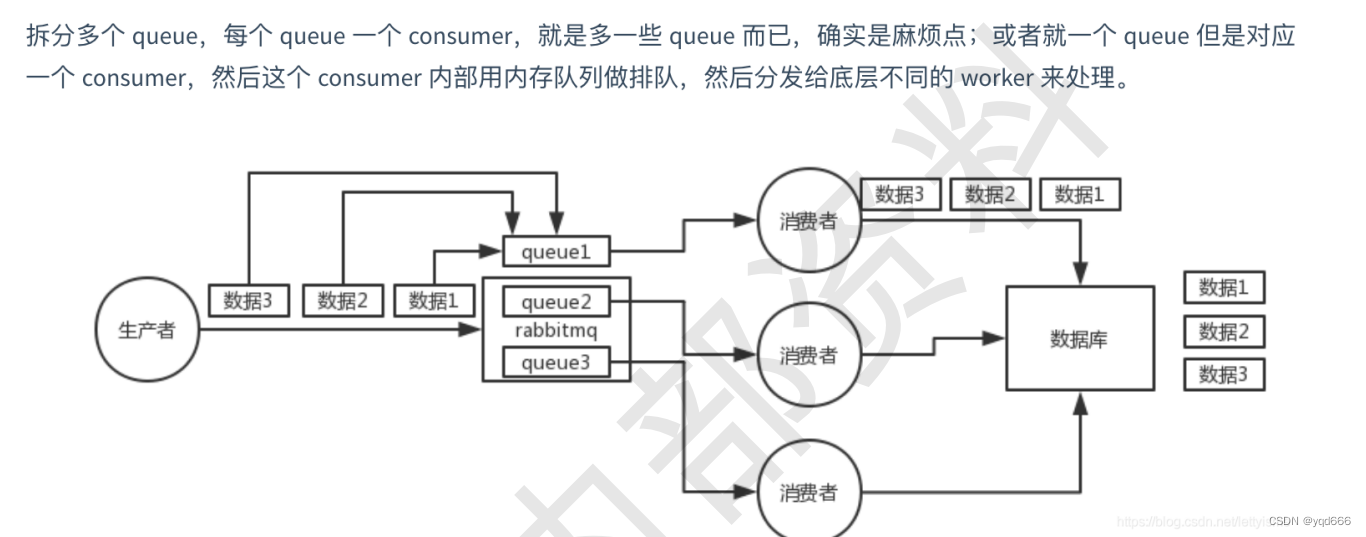
RabbitMQ的交换机有哪些?
(1)Direct Exchange:直连交换机,根据Routing Key(路由键)进行投递到不同队列。
(2)Fanout Exchange:扇形交换机,采用广播模式,根据绑定的交换机,路由到与之对应的所有队列。
(3)Topic Exchange:主题交换机,对路由键进行模式匹配后进行投递,符号#表示一个或多个词,*表示一个词。
(4)Header Exchange:头交换机,不处理路由键。而是根据发送的消息内容中的headers属性进行匹配。
什么是死信队列?死信队列是如何导致的?
什么是死信队列
(1)当一个消息在队列中变成死信之后,它能被重新发送到另一个交换机
中,即死信交换机,绑定到死信交换机的队列就称为死信队列。
(2)死信队列本身也是一个普通的消息队列,可以通过设置一些参数将其设置为死信队列
(3)死信队列是一个用于存放无法被消费的消息的队列,这些消息被称为死信
死信队列是如何导致的
(1)消息过期:
当一个消息过期后,它就会被发送到死信队列。这通常是由于消息的TTL(Time To Live)过期导致的。
(2)消息被拒绝:
当一个消费者拒绝处理某个消息时,这个消息就会被发送到死信队列。这通常是由于消息格式不正确或者无法处理等原因导致的。
(3)队列满了:
当一个队列已经满了,新的消息就无法进入该队列。这时,新的消息就会被发送到死信队列。