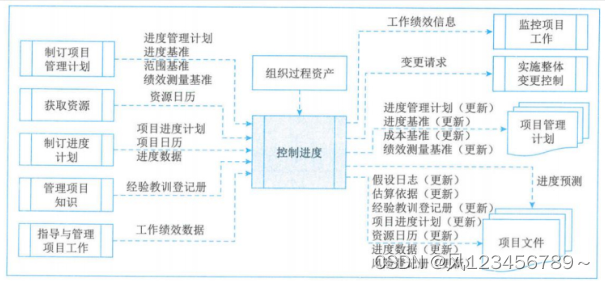
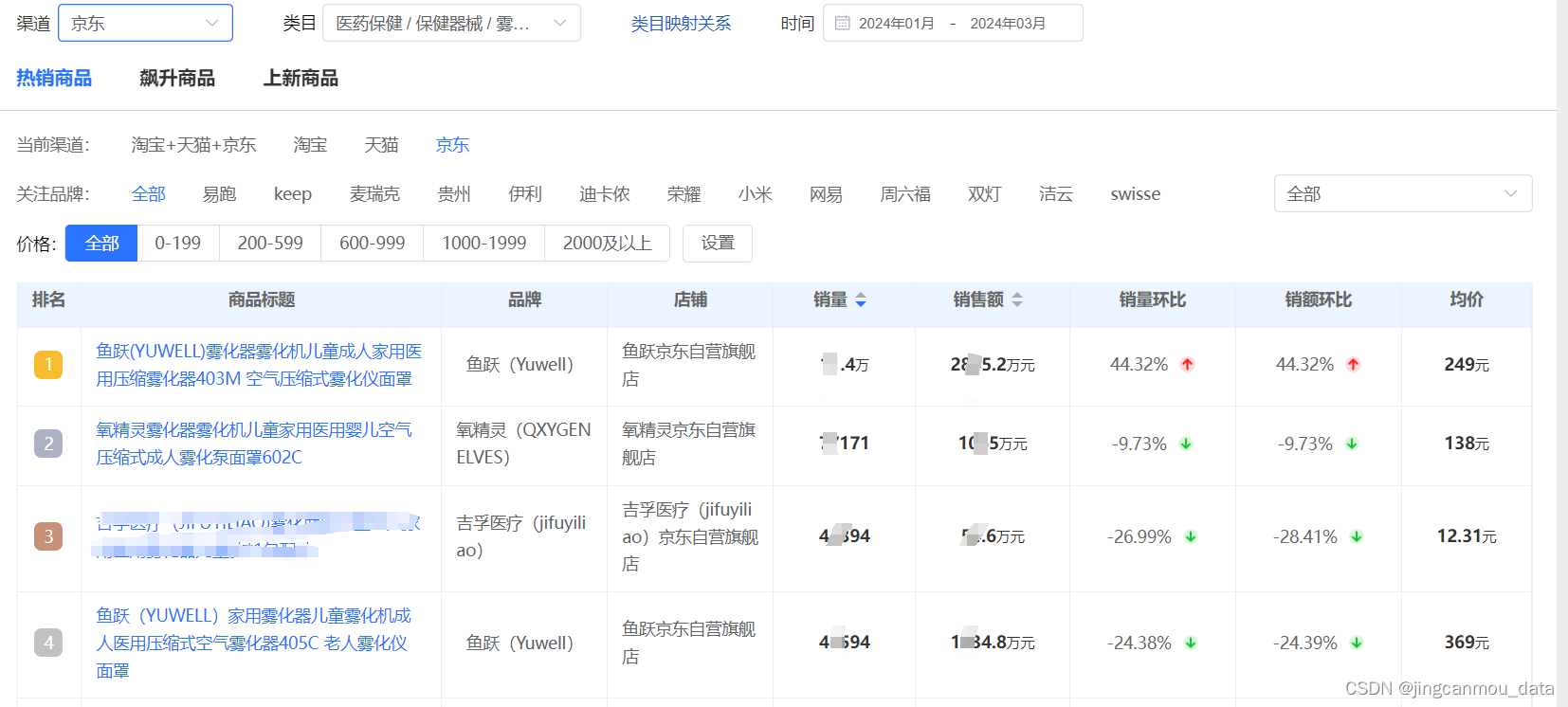
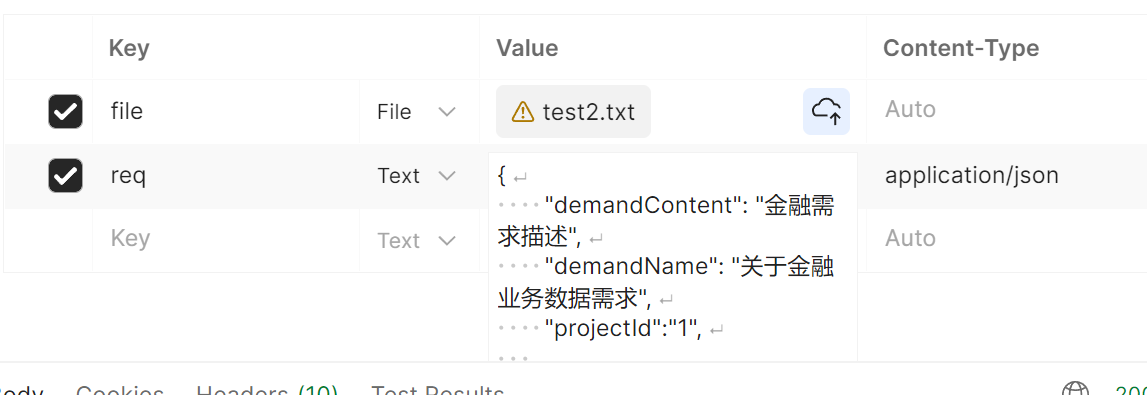
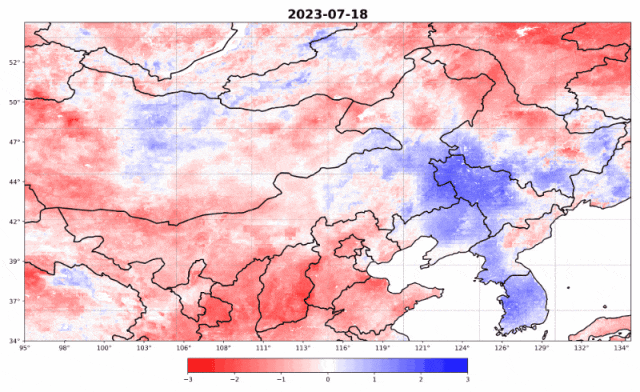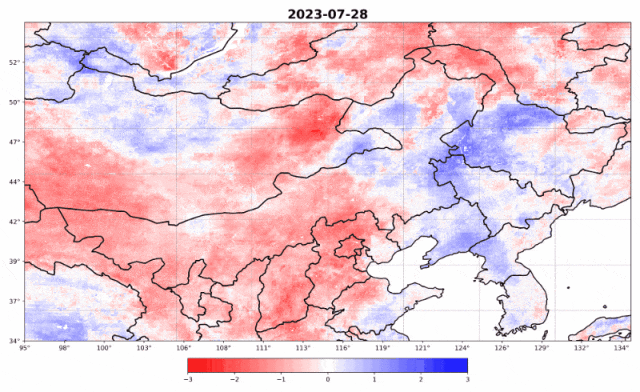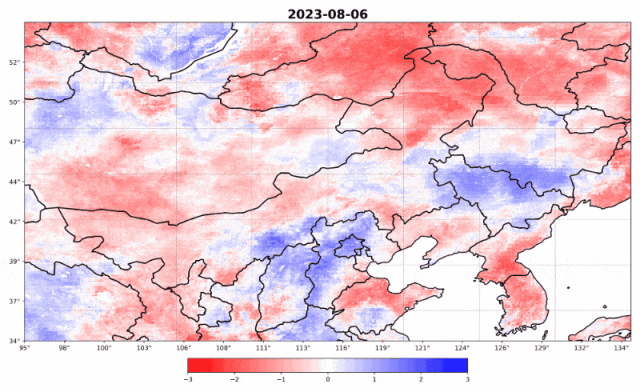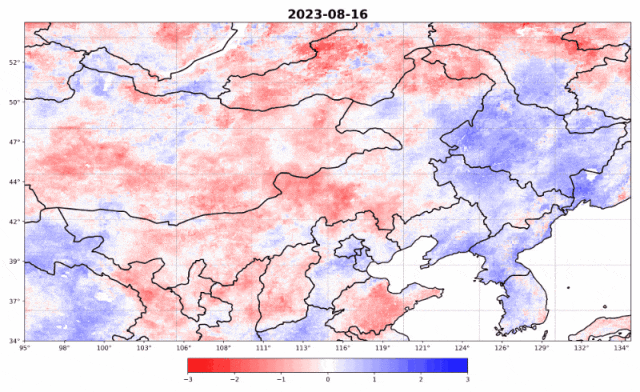
深度学习的数学知识点包括但不限于以下几个方面:
-
线性代数:
- 标量、向量、矩阵和张量:这些是线性代数的基础元素。标量是一个单独的数,向量是有序的数字列表,矩阵是二维数字网格,而张量则是更高维度的数据容器。
- 矩阵运算:包括加法、减法、乘法和转置等。深度学习中,大规模的并行计算常通过矩阵运算来实现,提高计算效率。
- 特征值和特征向量:对于理解数据的主要变化方向和压缩数据非常重要。
- 完备基和正交性:对于理解空间的表示和变换有关键作用。
-
微积分:
- 导数:描述函数局部变化的速度和方向,一阶导数在深度学习的反向传播中起到关键作用。
- 梯度下降法:一种优化算法,用于最小化损失函数,通过计算损失函数关于模型参数的梯度并沿梯度反方向更新参数。
-
概率论与数理统计:
- 概率分布:如高斯分布(正态分布),在深度学习中常用于建模数据的不确定性。
- 期望和方差:用于描述数据的中心趋势和离散程度。
- 极大似然估计:一种统计方法,用于估计概率模型的参数。
-
最优化方法:
- 牛顿法及其变种:如高斯-牛顿法、Levenberg-Marquardt方法等,用于求解非线性最小二乘问题或其他优化问题。
- 凸优化:凸函数和凸优化问题的理论在深度学习中很重要,因为它们具有良好的数学性质,便于求解全局最优解。
-
信息论:
- 熵和KL散度:用于度量信息的不确定性和两个概率分布之间的差异。在深度学习中,常用于评估模型学习到的数据分布与真实数据分布之间的差异。
示例:
- 线性代数示例:在深度学习中,图像可以被表示为一个三维张量(高度、宽度和颜色通道)。卷积神经网络(CNN)中的卷积操作可以看作是张量与卷积核之间的特殊矩阵乘法。
- 微积分示例:在训练神经网络时,我们使用反向传播算法计算损失函数关于模型参数的梯度,并据此更新参数以最小化损失。这涉及到求导数和链式法则的应用。
- 概率论与数理统计示例:在变分自编码器(VAE)中,我们使用多维高斯分布来建模数据的潜在表示,并利用KL散度来度量学习到的潜在分布与先验分布之间的差异。
- 最优化方法示例:在训练深度学习模型时,我们经常使用梯度下降法或其变种(如Adam、RMSprop等)来优化模型的参数。这些方法通过迭代地计算梯度并更新参数来寻找损失函数的最小值。
- 信息论示例:在训练生成对抗网络(GAN)时,我们可以使用KL散度或JS散度来衡量生成器生成的数据分布与真实数据分布之间的差异,从而指导生成器的训练过程。