文章目录
- 概要
- 原理及实现
- 归并排序
- 定义
- 性能
- 代码Python
- 快速排序
- 定义
- 代码
- 小结
概要
接上回
在上篇说过经典的算法>排序算法,有冒泡,插入,选择;归并,快排。其中讲了冒泡,插入,选择;这一回写归并和快排。
原理及实现
原理是很好玩的,如果不喜欢,先记住,总有一天会用得上的。
原理挺有意思的,喜欢就去研究,不喜欢就记住一些常用的,以备不时之需。先聊聊归并吧。
归并排序
本来想找个定义,看了下维基百科,也不是很满意的概念,如下:
定义
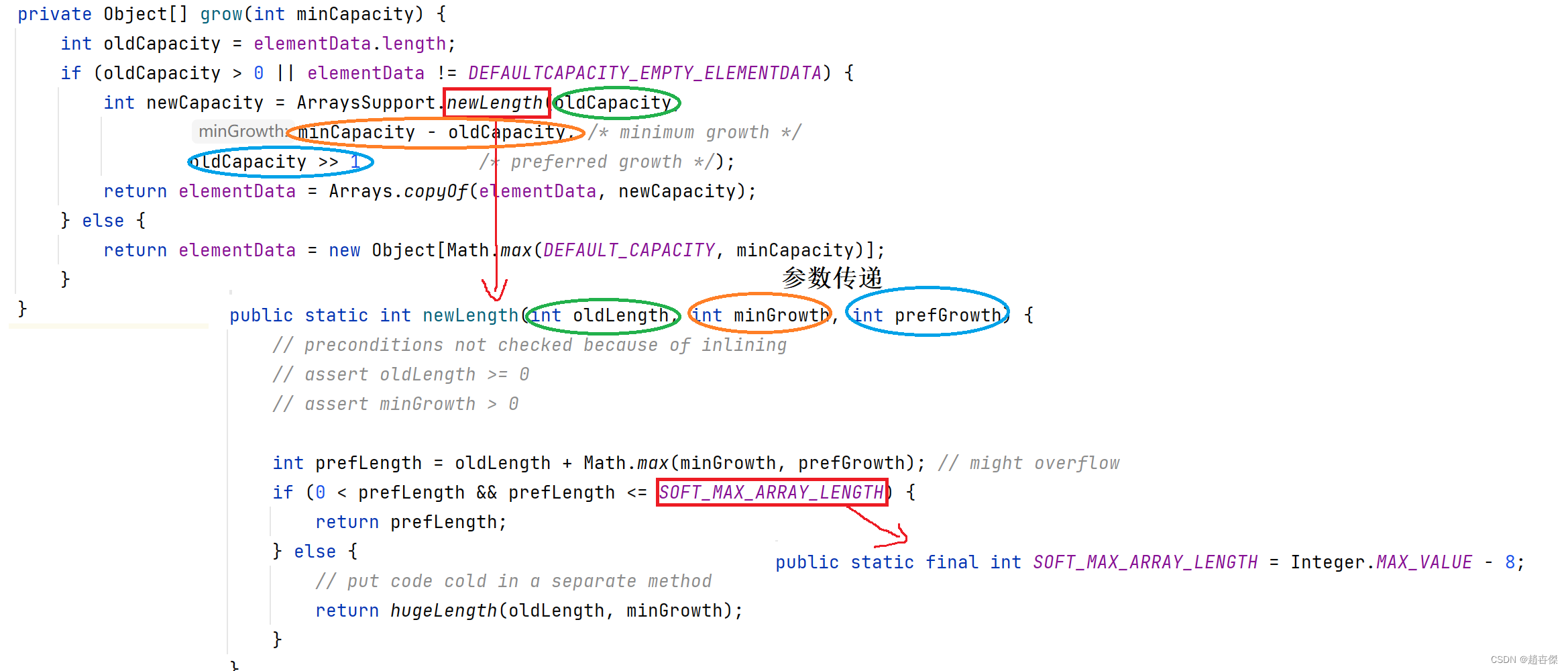
归并排序(英语:Merge sort,或mergesort),是建立在归并操作上的一种有效的算法>排序算法,效率为𝑂(𝑛log𝑛)(大O符号)。1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。
定义是这样的,怎么理解呢?采用分治递归,意思就是先平均分成2份,然后比较排序;递归这种操作,就是将2份中任何一份继续采用分治法(分治法这里不细聊,以后会写文章的),分成2份,直到不能再分为止;
性能
代码Python
dfrom typing import Listdef merge_sort(a: List[int]):merge_sort_between(a, 0, len(a) - 1)def merge_sort_between(a: List[int], low: int, high: int):# The indices are inclusive for both low and high.if low < high:mid = low + (high - low) // 2merge_sort_between(a, low, mid)merge_sort_between(a, mid + 1, high)merge(a, low, mid, high)def merge(a: List[int], low: int, mid: int, high: int):# a[low:mid], a[mid+1, high] are sorted.i, j = low, mid + 1tmp = []while i <= mid and j <= high:if a[i] <= a[j]:tmp.append(a[i])i += 1else:tmp.append(a[j])j += 1start = i if i <= mid else jend = mid if i <= mid else hightmp.extend(a[start:end + 1])a[low:high + 1] = tmp
快速排序
归并说完了,来看看快排。定义如下:
定义
快速排序(英语:Quicksort),又称分区交换排序(partition-exchange sort),是一种算法>排序算法,最早由东尼·霍尔提出。在平均状况下,排序𝑛个项目要𝑂(𝑛log𝑛)(大O符号)次比较。在最坏状况下则需要𝑂( n 2 n^2 n2)次比较,但这种状况并不常见。事实上,快速排序Θ(𝑛log𝑛)通常明显比其他算法更快,因为它的内部循环可以在大部分的架构上很有效率地达成。
按照定义,对一定长度的数据,选一个基准值,然后所有数据一个一个跟基准值比较,然后交互i,j的位置。还是分治和递归的思想,一直这么分,partion。
接下来看看代码,如下:
代码
from typing import List
import randomdef quick_sort(a: List[int]):quick_sort_between(a, 0, len(a) - 1)def quick_sort_between(a: List[int], low: int, high: int):if low < high:# get a random position as the pivotk = random.randint(low, high)a[low], a[k] = a[k], a[low]m = partition(a, low, high) # a[m] is in final positionquick_sort_between(a, low, m - 1)quick_sort_between(a, m + 1, high)def partition(a: List[int], low: int, high: int):pivot, j = a[low], lowfor i in range(low + 1, high + 1):if a[i] <= pivot:j += 1a[j], a[i] = a[i], a[j] # swapa[low], a[j] = a[j], a[low]return j
小结
学习总结
归并,排序都采用了分治的思想。时间复杂度归并O(nlogn),空间复杂度归并的比较大,达到O(n);快排时间复杂度O(nlogn),快排极端情况达到O( n 2 n^2 n2),但是概率很小,而且可以通过合理的选用基准值来避免,适用范围较广。