Pre-TrainedImageProcessingTransformer
- 论文地址
- 摘要
- 1. 简介
- 2.相关作品
- 2.1。图像处理
- 2.2。 Transformer
- 3. 图像处理
- 3.1. IPT 架构
- 3.2 在 ImageNet 上进行预训练
- 4. 实验
- 4.1. 超分辨率
- 4.2. Denoising
- 5. 结论与讨论
论文地址
1、论文地址
2、源码
摘要
随着现代硬件的计算能力在强烈增加,预训练的深度学习模型(如33.42928 216. BERT、GPT-3)在大规模数据集上的学习表现出 33.32933.226.7 与传统方法相比的有效性。 big28.933.126.6IPTHANIPT的进步主要归功于transformer及其变体架构的表示能力-HANHAN IPT(ECCV 2020)(ECCV 2020)(ECCV 2020)。在这篇 Deraining Denoising (50)Denoising (30) 论文中,我们研究了低级计算机视觉任务(例如,32.129.85 42denoising、超分辨率和去雨)并开发了一个 3229.7 41.531.9 0.3dB↑29.55 0.4dB↑新的预训练模型,即图像处理trans-41 1.6dB↑29.431.840.5former (IPT)。为了最大限度地挖掘 trans-31.729.254029.131.639.5former 的能力,我们提出利用著名的 ImageNet28.9531.539 基准生成大量损坏的 RDN IPTRDN IPTRCDNet IPT(CVPR 2018)(CVPR 2018)(CVPR 2020)图像对。 IPT 模型在这些具有多头和多尾的图像上进行训练。此外,con-Figure 1. 介绍了所提出的 IPT 和 trasive 学习的性能比较,以很好地适应不同任务的不同最新图像处理模型。 ent图像处理任务。因此,预训练模型可以在微调后有效地用于所需的任务。 IPT 仅使用一个预训练模型,在各种低级基准测试中优于当前最先进的方法。代码可在 https:/github. com/huawei-noah/Pretrained-IPT 和 https:/gitee.com/mindspore/mindspore/tree/master/model_zoo/research/cv/IPT
1. 简介
图像处理是更全局的图像分析或计算机视觉系统的低级部分的一个组成部分。图像处理的结果可以在很大程度上影响后续的高级部分,以执行图像数据的识别和取消提取。近年来,深度学习已被广泛用于解决图像超分辨率、修复、去雨和着色等低级视觉任务。由于许多图像处理任务是相关的,因此它是自然的期望在一个数据集上预训练的模型对另一个数据集有帮助。但很少有研究将预训练推广到图像处理任务中。这个问题在涉及付费数据或数据隐私的图像处理任务中加剧,例如医学图像 [8] 和卫星图像 [83]。各种不一致的因素(例如相机参数、光照和天气)会进一步扰乱用于训练的捕获数据的分布。其次,在呈现测试图像之前,不知道将请求哪种类型的图像处理作业。因此,我们必须手头准备一系列图像处理模块。他们有不同的目标,但一些底层操作可以共享。现在在自然语言处理和计算机视觉方面进行预训练是很常见的[12]。例如,目标检测模型 [98、97] 的主干通常在 ImageNet 分类 [18] 上进行预训练。一个数字-现在可以很容易地从互联网上获得大量训练有素的网络,包括 AlexNet [43]、VGGNet [63] 和 ResNet [34]。开创性的工作 Transformers [70] 已广泛用于许多自然语言处理 (NLP) 任务,例如翻译 [73] 和问答 [66]。它成功的秘诀是在大型文本语料库上预训练基于 transformer 的模型,并在特定任务的数据集上对其进行微调。变形金刚的变体,如 BERT [19] 和 GPT-3 [5],进一步丰富了训练数据并提高了预训练技能。已经有一些有趣的尝试将 Transformers 的成功扩展到计算机视觉领域。例如,王等人。 [71] 和 Fu 等人。 [25] 应用基于自我注意的模型来捕获图像的全局信息。卡里昂等。 [7] 建议 DERT 使用变换器架构进行端到端对象检测。最近,Dosovitskiy 等人。 [22] 引入 Vision Transformer (ViT) 将输入图像视为 16×16 的单词,并在图像识别方面取得了优异的效果。上述计算机视觉和自然语言的预训练主要研究预测试分类任务,但输入和图像处理任务中的输出是图像。直接应用这些现有的预训练策略可能不可行。此外,如何在预训练阶段有效地解决不同的目标图像处理任务仍然是一个艰巨的挑战。
同样值得注意的是,图像处理模型的预训练享有基于原始真实图像的自生成训练实例的便利。合成处理后的图像被用于训练,而原始图像本身就是要重建的真值。
在本文中,我们开发了一个使用变换器架构进行图像处理的预训练模型,即图像处理变换器(IPT) .由于预训练模型需要兼容不同的图像处理任务,包括超分辨率、去噪和去雨水,因此整个网络由对应不同任务的多对头尾和一个共享体组成。由于需要使用大规模数据集来挖掘transformer的潜力,因此我们应该预先配对大量具有相当多样性的图像来训练IPT模型。为此,我们选择了 ImageNet 基准测试,其中包含具有 1,000 个类别的各种高分辨率。对于 ImageNet 中的每个图像,我们使用几个精心设计的操作来生成多个损坏的副本以服务于不同的任务。例如,超分辨率任务的训练样本是通过对原始图像进行下采样生成的。我们用于 IPT 训练的整个数据集包含大约超过 1000 万张图像。然后,transformer 架构在庞大的数据集上进行如下训练。训练图像输入到特定的头部,生成的特征被裁剪成补丁(即“单词”)并随后展平为序列。变压器主体用于处理扁平特征,其中位置和任务嵌入分别用于编码器和解码器。此外,尾部被迫根据特定任务预测具有不同输出大小的原始图像。此外,为了很好地适应不同的图像处理任务,引入了不同输入的补丁之间关系的对比损失。所提出的图像处理变压器以端到端的方式学习。在几个基准上进行的经验结果表明,经过微调后,预先训练的IPT模型可以通过显着增强来超越大多数现有的方法。
2.相关作品
2.1。图像处理
图像处理包括对图像的处理,包括超分辨率、去噪、去雾、去雨、去模糊等。提出了多种基于深度学习的方法对一种或多种图像进行处理处理任务。对于超分辨率,Dong 等人。提出 SRCNN [20, 21],这被认为是开创性的工作,引入了端到端模型,这些模型从 LR 对应物重建 HR 图像。金等人。 [41] 用更深的卷积网络进一步探索深度神经网络的容量。安等人。 [2] 和 Lim 等人。 [50] 提出将残差块引入 SR 任务。张等。 [92] 和 Anwar 和 Barnes [3] 利用注意力的力量来提高 SR 任务的性能。还为其他任务提出了各种优秀的作品,例如去噪 [68、32、37、45、24]、去雾 [6、46、85、80]、去雨 [36、78、62、29, 74、47] 和去模糊 [67、53、23、10]。与上述方法不同的是,我们挖掘了大模型和海量数据的容量。然后介绍了处理多个图像处理任务的预训练模型。
Transformer_20">2.2。 Transformer
Transformer [70] 及其变体已证明其在各种自然语言处理任务中是强大的无监督或自监督预训练框架的成功。例如,GPT [59、60、5] 以自回归方式进行预训练,以预测巨大文本数据集中的下一个单词。 BERT [19] 在没有明确监督的情况下从数据中学习,并根据上下文预测掩码词。科林等人。 [61] 为几个下游任务提出了一个通用的预训练框架。银汉等。 [52] 提出了原始 BERT 的鲁棒变体。由于基于 Transformer 的模型在 NLP 领域的成功,有许多尝试探索其好处Transformer 在计算机视觉任务中的应用。这些尝试大致可以分为两种。首先是将self-attention引入到传统的卷积神经网络中。元等。 [82] 引入了图像分割的空间注意力。傅等。 [26] 通过结合空间和通道注意力,提出使用上下文信息的 DANET。王等。 [75],陈等。 [15],姜等。 [38] 和张等人。 [91] 还通过自我关注来增强特征,以增强模型在几个高级视觉任务上的性能。另一种是用self-attention block代替卷积神经网络。例如,Kolesnikov 等人。 [42] 和 Dosovitskiy [22] 用变压器块进行图像分类。卡里昂等。 [7] 和朱等人。 [100] 在检测中实施基于变压器的模型。陈等。 [11] 提出了一种用于生成和分类任务的预训练 GPT 模型。吴等。 [77] 和赵等人。 [96] 提出了基于 teasformer 的图像识别任务模型的预训练方法。姜等。 [39] 提出 TransGAN 使用 Transformer 生成图像。然而,很少有相关工作关注低级视觉任务。在本文中,我们探索了一种用于图像处理任务的通用预训练方法。
3. 图像处理
变压器为了挖掘变压器在处理任务中的潜在用途以达到更好的结果,这里我们通过在大规模数据集上进行预训练来介绍图像处理变压器。
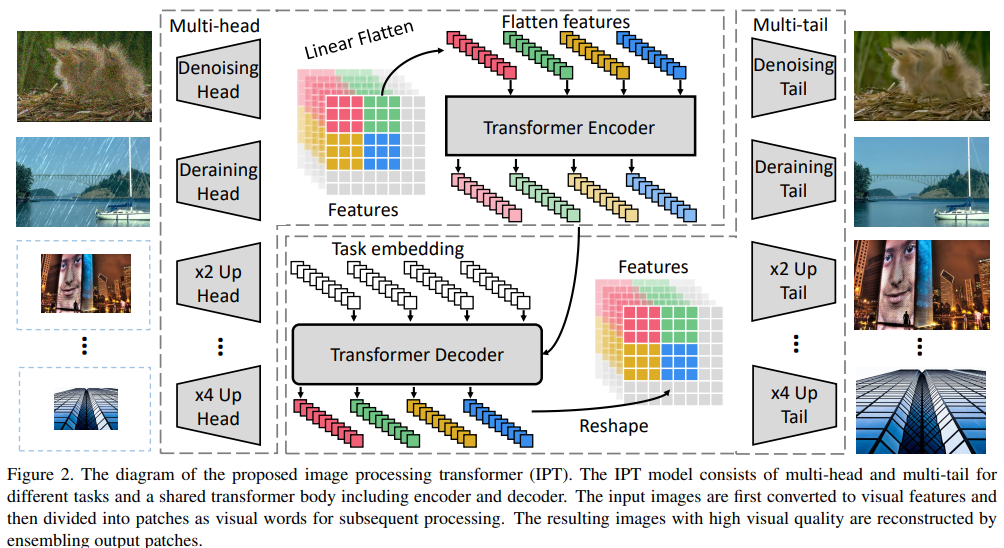
3.1. IPT 架构
我们 IPT 的整体架构由四个部分组成:
• 用于从输入损坏图像(例如,带有噪声的图像和低分辨率图像)中提取特征的头部,
• 建立用于恢复丢失信息的编码器 - 解码器transformer在输入数据中,
• 尾部用于将特征映射到恢复的图像中。
在这里我们简要介绍一下我们的架构,详细信息可以在补充材料.Heads中找到。为了调整不同的图像处理任务,我们使用多头架构分别处理每个任务,其中每个头由三个卷积层组成。将输入图像表示为 x ∈ R3×H×W(3 表示 R、G 和 B),head 生成具有 C 个通道且相同高度和宽度的特征图 fH ∈ RC ×H ×W(通常我们使用C = 64)。计算可以表示为 fH = H i (x),其中 Hi (i = {1,…,Nt}) 表示第 i 个任务的头部,Nt 表示任务的数量。Transformer 编码器。在将特征输入到 transformer body 之前,我们将给定的特征分成 patch,每个 patch 被视为一个“词”。具体来说,特征 fH ∈ RC × H × W 被重塑为一系列补丁,即 fpi ∈ RP2 × C,i = {1,…,N},其中 HWN = P 2 是补丁的数量(即,序列的长度)和 P 是补丁大小。为了维护每个补丁的位置信息,我们为 [22, 7] 之后的每个特征 fpi 补丁添加可学习的位置编码 Epi ∈ RP 2 ×C,并且 Epi + fpi 将直接输入到转换器中编码器。编码器层的架构是遵循[70]中的原始结构,它具有多头自注意力模块和前馈网络。每个补丁的编码器 fEi ∈ RP 2 ×C 的输出与输入补丁 fpi 的大小相同。计算可以表述为
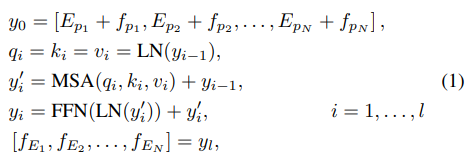
其中l表示编码器中的层数,MSA表示通用变压器模型中的多头自注意力模块[70],LN表示层均衡[4],FFN表示包含两个完全连接的层的前馈网络。
变压器解码器。
解码器也遵循相同的架构,并将解码器的输出作为转换器主体的输入,该转换器主体由两个多头自注意(MSA)层和一个前馈网络(FFN)组成。这里与原始转换器的不同之处在于,我们利用特定于任务的嵌入作为解码器的附加输入。这些特定于任务的嵌入 Eti ∈ RP2×C,i = {1,…,Nt} 被学习来解码不同任务的特征。解码器的计算可以表述为:

尾巴。尾巴的属性与头部的属性相同,我们使用多尾来处理不同的任务。计算可以表述为 fT = T i (fD),其中 T i (i = {1,…,Nt}) 表示第 i 个任务的头部,Nt 表示任务的数量。输出 fT 是 3 × H′ × W′ 的结果图像大小,由特定任务决定。例如,对于 2× 超分辨率任务,H′ = 2H,W = 2W.3.2。
3.2 在 ImageNet 上进行预训练
除了变压器本身的架构之外,成功训练优秀转换器的关键因素之一是充分利用大规模数据集。比较对于图像分类,用于图像处理任务的可用数据数量相对较少(例如,DIV2K 数据集上只有 2000 张图像用于图像超分辨率任务),我们建议利用众所周知的 ImageNet 作为基线数据集进行预测-训练我们的 IPT 模型,然后我们为几个任务(例如,超分辨率和去噪)生成整个数据集,如下所示。由于 ImageNet 基准测试中的图像具有高度多样性,其中包含来自 1,000 个不同的超过 100 万张自然图像类别。这些图像具有丰富的纹理和颜色信息。我们首先删除语义标签,并使用针对不同任务的各种退化模型,从这些未标记的图像中手动合成各种损坏的图像。请注意,合成数据集也通常用于这些图像处理任务,我们使用与 [31, 1] 中建议的相同的退化方法。例如,超分辨率任务通常采用双三次降级来生成低分辨率图像,去噪任务在具有不同噪声水平的干净图像中添加高斯噪声以生成噪声图像。这些合成图像可以显着提高学习深度网络的性能,包括 CNN 和 transformer 架构,这将在实验部分展示。基本上,损坏的图像被合成为:

其中 f 表示退化变换,这取决于特定任务:对于超分辨率任务,FSR 正好是双三次插值;对于图像去噪,fnoise(I) = I + η,其中η是加性高斯噪声;对于下雨,frain(I) = I +r,其中 r 是手工制作的雨纹。以监督方式学习我们的 IPT的损失函数可以表述为:
xxxxx此外,方程4意味着所提出的框架同时使用多个图像处理任务进行训练。具体来说,对于每个批次,我们从 Nt 监督任务中选择一个任务进行训练,每个任务将同时使用相应的头、尾和任务嵌入进行处理。在对IPT模型进行预训练后,它将捕获各种图像处理任务的内在特征和转换,因此可以使用新提供的数据集进一步微调以应用于所需的任务。此外,为了节省计算成本,将删除其他头部和尾部,其余头部、尾部和身体中的参数将根据反向传播进行更新。然而,由于退化模型的多样性,我们无法为所有图像处理任务合成图像。
例如,在实践中可能存在各种可能的噪音水平。因此,应进一步增强由此产生的 IPT 的泛化能力。与预训练的自然语言处理模型类似,图像块之间的关系也是信息丰富的。图像场景中的补丁可以被认为是自然语言处理中的单词。例如,从同一个特征图中裁剪出的补丁更有可能一起出现,它们应该嵌入到相似的位置。因此,我们引入对比学习 [13, 33] 来学习通用特征,以便可以将预训练的 IPT 模型用于未见过的任务。在实践中,将 IPT 解码器针对给定输入 xj 生成的输出修补特征表示为 fj ∈ RP2×C,i = {1,…,N}, Di 其中 xj 是从一批训练图像 X = {x1,x2 ,…,xB}。我们的目标是最小化来自相同图像的补丁特征之间的距离,同时最大化来自不同图像的补丁之间的距离。对比学习的损失函数公式为:

xxxxx此外,为了充分利用监督和自监督信息,我们将损失函数重新表述为:LIP T = λ ·对比+监督。(6)其中,我们将λ平衡对比损失与监督损失相结合,作为IPT的最终目标函数。因此,使用方程6训练的拟议变压器网络可以有效地用于各种现有的图像处理任务。
4. 实验
在本节中,我们评估了所提出的 IPT 在各种图像处理任务(包括超分辨率和图像去噪)上的性能。我们表明,预先训练的IPT模型可以在这些任务上实现最先进的性能。此外,大量的消融研究实验表明,当使用大规模数据集来解决图像处理问题时,基于变压器的模型比卷积神经网络更好。
数据。为了获得更好的IPT模型预训练结果,我们使用著名的ImageNet数据集,该数据集由超过100万张高度多样性的彩色图像组成。将训练图像裁剪为48×48个补丁,有3个通道用于训练,即有超过10M个补丁用于训练训练 IPT 模型。然后,我们生成具有6种退化类型的损坏的Image:分别为2×,3×,4×双三次插值,30,50噪声水平高斯噪声和添加雨纹。对于雨纹生成,我们采用[79]中描述的方法。在测试过程中,我们将测试集中的图像裁剪为48×48个补丁,重叠10个像素。请注意,基于CNN的模型也采用了相同的测试策略以进行公平比较,并且CNN模型的结果PSNR值与其基线的PSNR值相同。
培训和微调xxxxxxxxxxxx
4.1. 超分辨率
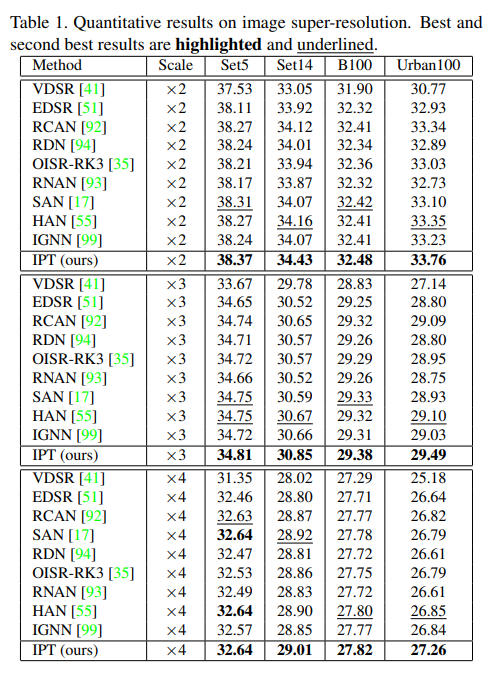
我们将我们的模型与几种最先进的基于 CNN 的 SR 方法进行了比较。如表1所示,我们的预训练IPT优于所有其他方法,并在所有数据集上实现了×2,×3×4规模的最佳性能。值得789强调的是,我们的模型在×2尺度的Urban100数据集上实现了33.76dB的PSNR,超过了其他方法的∼0.4dB以上,而以前的SOTA方法与其他方法相比只能实现<0.2dB的改进,这表明所提出的模型利用大规模预训练具有优越性。我们在 Urban100 数据集上以 4× 的比例进一步展示了模型的可视化结果。如图3所示,由于高比例因子导致大量信息丢失,因此很难恢复原始高分辨率图像。以前的方法会产生模糊的图像,而我们的模型产生的超分辨率图像可以很好地从低分辨率图像中恢复细节。
4.2. Denoising
5. 结论与讨论
本文旨在利用预训练变压器模型(IPT)解决图像处理问题。IPT型号设计有多头、多尾共享变压器体,用于处理图像超分辨率和去噪等不同的图像处理任务。为了最大限度地挖掘变压器架构在各种任务中的性能,我们探索了一个合成的ImageNet日期集。其中,每个原始图像将被降级为一系列对应物作为配对训练数据。然后使用监督和自监督方法对IPT模型进行训练,该方法显示出捕获内在特征以进行低级图像处理的强大能力。实验结果表明,经过快速微调后,我们的IPT仅使用一个预训练模型即可胜过最先进的方法。在未来的工作中,我们将把我们的 IPT 模型扩展到更多的任务,如修复、去雾等。