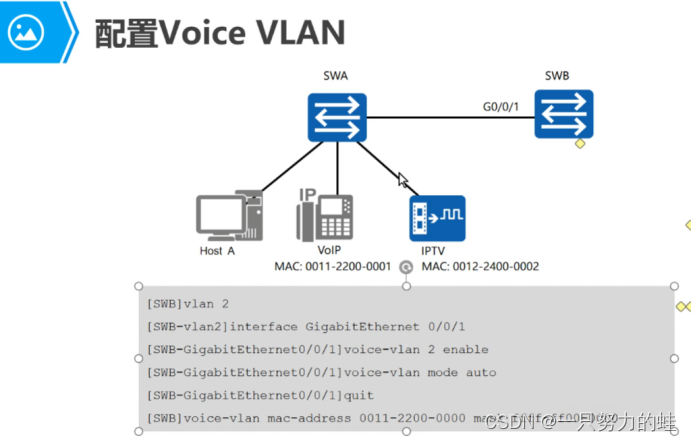
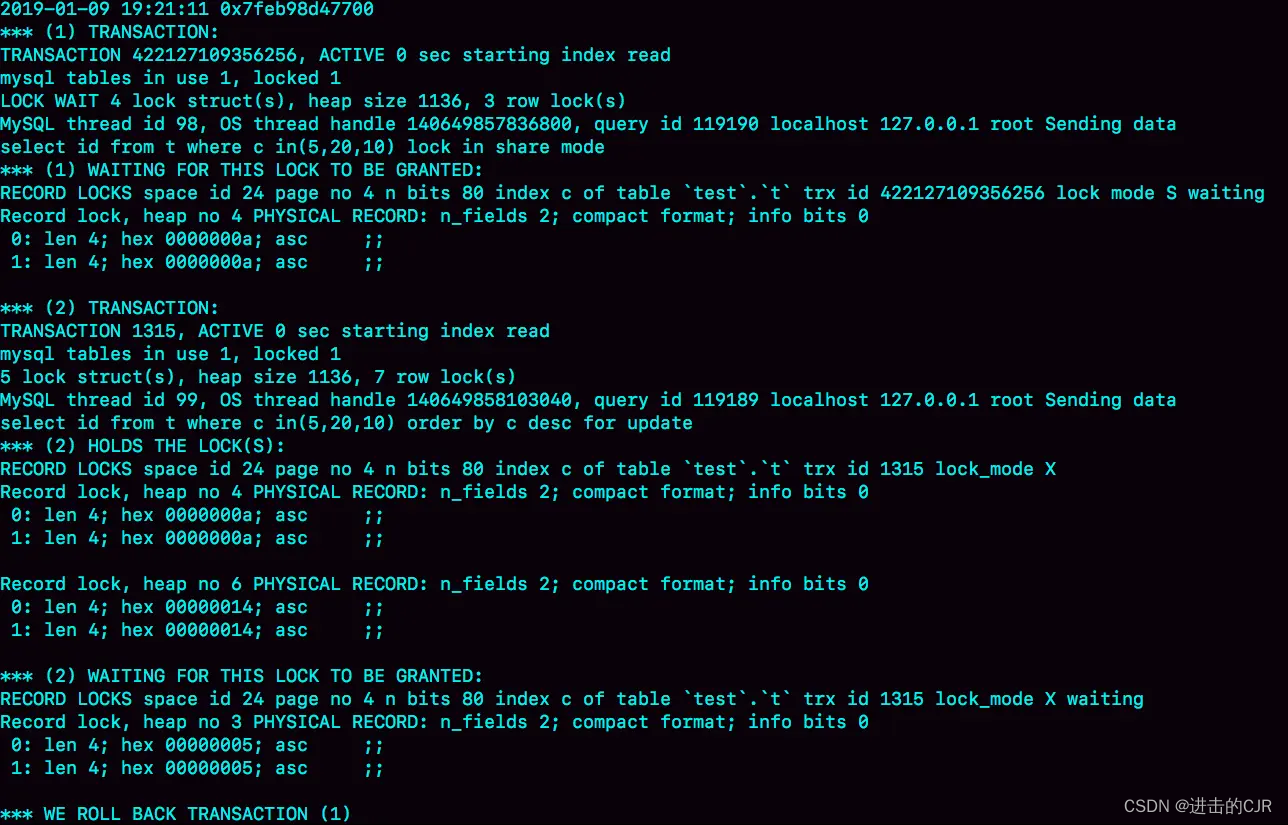
--懂王

在大数据高速发展的时代,AI的发展日新月异,充满挑战的迎接未来。
自然语言处理 (NLP) 中的迁移学习: 迁移学习在 NLP 中越来越受欢迎,特别是在数据稀缺的情况下。如何有效地利用预训练的语言模型,并将其迁移到新的任务和领域是当前的研究热点。
自然语言处理 (NLP) 中的迁移学习 是什么??
在自然语言处理(NLP)中,迁移学习是指将从一个任务或领域学到的知识应用到另一个相关任务或领域的过程。这种方法可以解决在新任务或领域数据较少或不足以支持单独训练有效模型的情况。
迁移学习在 NLP 中的应用非常广泛,有哪些比较特别的情况??
预训练语言模型的应用:通过大规模文本数据预训练的语言模型(如BERT、GPT等)可以捕获丰富的语言表示,这些表示可以迁移到各种下游任务中,例如文本分类、命名实体识别、情感分析等。在迁移学习中,通常会冻结预训练模型的参数,只微调部分参数以适应特定任务。
跨领域情感分析:在情感分析任务中,情感词汇和表达方式在不同领域之间可能有所不同。迁移学习可以通过在一个领域上进行训练,然后将模型应用于另一个领域,从而提高在目标领域的性能。
跨语言文本分类:迁移学习可以帮助将已在一个语言上训练的模型应用于另一个语言的文本分类任务。通过在源语言上进行训练,模型可以学习到一些通用的语言特征和表示,然后迁移到目标语言上。
小样本学习:在一些数据稀缺的场景下,迁移学习可以帮助提高模型的泛化能力。通过利用大规模数据进行预训练,然后将模型迁移到小样本任务上,可以避免在小样本任务上过拟合的问题。
迁移学习的核心思想是利用源领域的知识来辅助目标任务的学习,从而提高模型的性能和泛化能力。这种方法可以节省训练时间和数据收集成本,并且通常可以在新任务上取得更好的表现。
当涉及到自然语言处理(NLP)中的迁移学习时,有那几个关键方面值得更详细地讨论呢??
预训练语言模型的迁移应用:
- 近年来,预训练语言模型如BERT、GPT等在NLP领域取得了巨大成功。这些模型通过在大规模文本数据上进行自监督学习来学习通用的语言表示。在迁移学习中,这些预训练模型的参数可以被微调,以适应特定的下游任务。
- 在微调时,一种常见的策略是在目标任务的训练数据上添加一个相对较小的任务特定的层,然后通过反向传播来调整整个模型的参数,同时保持预训练模型的大部分参数不变。
- 预训练语言模型通常在大规模通用文本数据上进行训练,因此它们学到的语言表示是相对通用的,可以应用于各种下游任务,如文本分类、文本生成、命名实体识别等。
领域自适应和迁移学习:
- 在某些情况下,源领域和目标领域之间可能存在差异,如词汇、句法结构、文化背景等。在这种情况下,迁移学习可以通过领域自适应的方式来减少这种差异。
- 领域自适应的方法包括特征选择、特征映射、对抗训练等。例如,可以使用对抗训练来使得预训练模型在源领域和目标领域之间学习通用的表示,从而减少领域差异对性能的影响。
迁移学习的监督与无监督方法:
- 在迁移学习中,可以使用监督和无监督的方法来利用源领域的知识。监督方法通常涉及源领域和目标领域都有标记数据的情况下,通过监督学习来迁移知识。而无监督方法则尝试从源领域的未标记数据中学习知识,并将其迁移到目标领域上。
- 无监督方法通常更具有泛化能力,因为它们不依赖于标记数据的可用性,但监督方法在标记数据充足时可能会获得更好的性能。
迁移学习的度量和评估:
综上所述,迁移学习在NLP领域是一个非常重要且具有挑战性的问题。它不仅能够帮助解决数据稀缺的问题,还可以帮助模型更好地适应新的任务和领域。
我们关于自然语言处理(NLP)中的迁移学习,举出几个经典例子??
以下是我总结的自然语言处理(NLP)中迁移学习的几个经典例子:
情感分析:
- 在一个领域(如餐饮评论)上训练的情感分析模型可以迁移到另一个领域(如电影评论)上,以便在新领域中分析文本的情感极性。通过迁移学习,模型可以利用源领域的情感表示来更好地理解目标领域的情感。
命名实体识别:
- 一个领域(如医学文献)上训练的命名实体识别模型可以迁移到另一个领域(如金融报告)上,以识别文本中的实体名称,如人名、地名、组织机构等。通过迁移学习,模型可以共享源领域的实体表示,提高目标领域的命名实体识别性能。
文本分类:
- 在一个领域(如新闻报道)上训练的文本分类模型可以迁移到另一个领域(如社交媒体)上,以对文本进行分类,如新闻类别、情感分类等。通过迁移学习,模型可以利用源领域的语言表示来更好地理解目标领域的文本特征。
机器翻译:
- 在一个语种(如英语到法语)上训练的机器翻译模型可以迁移到另一个语种(如英语到中文)上,以进行跨语种的翻译。通过迁移学习,模型可以共享源语种的语言表示和翻译知识,从而提高目标语种的翻译性能。
这些例子展示了迁移学习在自然语言处理中的广泛应用。通过在一个领域或语种上学习到的知识,模型可以迁移到其他领域或语种上,以提高模型的泛化能力和性能。