数据表设计原则:
自动编号的ID应该设计为`bigint`,因为`int`可能不够用,并且,为了便于统一管理,写的舒心不出错,建议所有表的自增ID全部使用`bigint` 。(缺点是占空间,如果有20亿条数据,浪费80亿个字节,折算下来在7.45个g左右,但数据库的数据是存在硬盘上的,硬盘空间大,而且拥有20亿条数据的项目是不在意这7个g的,权衡下来也就不用考虑这个缺点了)
数值类型的字段使用
unsigned表示“无符号位的”,以tinyint(对应Java中的byte类型)为例,如果是有符号位的,取值区间是[-128, 127],因为8位二进制有一位表示符号位,7位1最高上限是127,如果是无符号位的,取值区间是[0, 255],即8个1。需要注意,在许多设计中,添加unsigned更多的是为了表现“语义”,并不是为了扩容正数的取值上限,比如给id添加只是表示id永远不为负数。
强烈推荐为每个字段配置
COMMENT,以表示各字段的含义
id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '数据id'
使用
varchar时,应该设计一个绝对够用的值,例如“用户名”可以设计为varchar(50),这样设计的好处是可以应对未来可能出现的变化,同时varchar是变长的,只会占用实际存入的数据的应占用空间,即使设计得比较大,也不会浪费空间,但是,也不要大到离谱,会影响语义(varchar可以写的最大值是65532,理论上是65535,是否为null的标记会扣去一个字节,还会扣去1-2个字节来记录实际往里面存了几个字)
username varchar(50) DEFAULT NULL COMMENT '用户名'
如果你可能需要根据某个字段进行排序,而这个字段可能存在“非ASCII字符”(例如中文),应该添加新的字段,记录对应的数据的拼音,实际排序是,应该根据拼音字段排序,以解决中文的多音字问题
pinyin varchar(255) DEFAULT NULL COMMENT '品牌名称的拼音'
如果你认为这个数据会被参与到搜索查询里面,就需要去为它设计一个字段,指定关键词列表
keywords varchar(255) DEFAULT NULL COMMENT '关键词列表,各关键词使用英文的逗号分隔'
许多数据都可能需要注意列表中的数据的顺序,则极可能需要添加“排序序号”字段,以干预排序结果(比如谁充值就把谁放在前面)
在编写查询的SQL语句时,只要查询结果可能超过1条,必须显式的指定
ORDER BY,如果第1排序规则不足以使得所有结果都有明确顺序,还应该继续指定第2排序规则、第3排序规则等
sort tinyint(3) unsigned DEFAULT NULL COMMENT '排序序号'注意:如果不指定ORDER BY,并不是按照id升序排列的,是按照数据库自己决定的,即使是同一款数据库的不同版本也会不同,所以必须要指定ORDER BY 排序。

当设计有“层级”特征的数据表时,例如设计“类别表”、“省市区数据表”时,可以在表中设计
parent_id(或类似名称)的字段,使得1张表可以存储若干层级的数据
parent_id bigint(20) unsigned DEFAULT NULL COMMENT '父级类别id,如果无父级,则为0'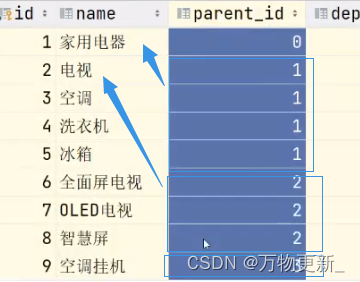
表中设计深度depth字段,可以更快的知道它是几级,它的好处:
- 层级查询:
depth字段可以表示数据的层级关系,使得在查询时可以方便地进行层级的过滤和排序。例如,可以根据depth字段进行树形结构的查询,查找某个节点的所有子节点或者所有父节点。- 数据完整性约束:通过
depth字段,可以对数据的层级关系进行约束,避免数据结构的错误或异常。例如,可以定义depth字段的取值范围或者参照外键关系,确保每个节点都符合预期的层级结构。
- 快速导航和过滤:通过
depth字段,可以快速筛选出特定层级的数据,从而实现导航和过滤的功能。例如,可以根据depth字段查询所有一级节点或者所有叶子节点,以满足特定的业务需求。- 提升查询性能:通过在表中添加
depth字段,可以减少复杂的递归查询或者多次查询的需求,从而提升查询性能。可以通过depth字段进行条件查询,避免对整个数据集进行扫描,从而加快查询速度。
depth tinyint(3) unsigned DEFAULT NULL COMMENT '深度,最顶级类别的深度为1,次级为2,以此类推'
设计is_parent字段,可以更方便的查询到它是不是父级,如果是父级就可以接着查看它的子集
is_parent tinyint(3) unsigned DEFAULT NULL COMMENT '是否为父级(是否包含子级),1=是父级,0=不是父级'
设计is_display字段是否显示在导航栏中,同上is_parent字段,都是属于依据数据,虽然没有实际意义,但是都非常的方便
is_display tinyint(3) unsigned DEFAULT NULL COMMENT '是否显示在导航栏中,1=启用,0=未启用'
当某些数据的量比较大时,可能需要与别的数据关联起来,在实际应用时,可以起到“筛选”的作用,例如:当发布“笔记本电脑”这种类别的商品时,不需要将“老干妈”这种名牌显示在列表中
brand_id bigint(20) unsigned DEFAULT NULL COMMENT '品牌id',
category_id bigint(20) unsigned DEFAULT NULL COMMENT '类别id'
smallint是MySQL中的一种整数类型,通常占据2个字节(16位)的存储空间。在有符号的情况下,smallint可以表示的范围为 -32,768 到 32,767。其中,最高位用于表示符号位,0 表示正数,1 表示负数,剩余的位用于表示数值的大小。因此,在有符号位的情况下,
smallint可以表示的整数范围为 -32,768 到 32,767。如果不需要负数,可以使用无符号的smallint类型(unsigned smallint),此时可以表示的范围为 0 到 65,535。对于图片的宽高等字段数据如果是像素为单位就可以用smallint类型。
width smallint(5) unsigned DEFAULT NULL COMMENT '图片宽度,单位:px',height smallint(5) unsigned DEFAULT NULL COMMENT '图片高度,单位:px'如果某张表中某个字段的值可能比较大,应该将这个字段设计到另一张表中去,并且,这2张表将形成“1对1”的关系,例如“新闻”数据中的“正文”就是可能比较大的数据,则应该拆分为“新闻信息表”和“新闻正文表”,将新闻的正文数据保存在“新闻正文表”中,而新闻的其它基本信息都保存在“新闻信息表”中即可,这种拆分的目的是为了避免较大的数据影响查询效率
对于数据量可能非常大的表,可能后续将会做分库分表的处理,主键ID不要使用自动编号