山东大学软件学院创新项目实训开发日志——第9周
项目名称:ModuFusion Visionary:实现跨模态文本与视觉的相关推荐
-------项目目标:
- 本项目旨在开发一款跨模态交互式应用,用户可以上传图片或视频,并使用文本、点、框等提示,精确分割出图片或视频中指定的物体,或者无提示地分割出所有物体。
- 基于分割出的物体,用户可以选择生成感兴趣的其他图片或视频。
- 内置推荐算法可以自动根据分割结果,推荐与之相关的信息。
本周完成的任务
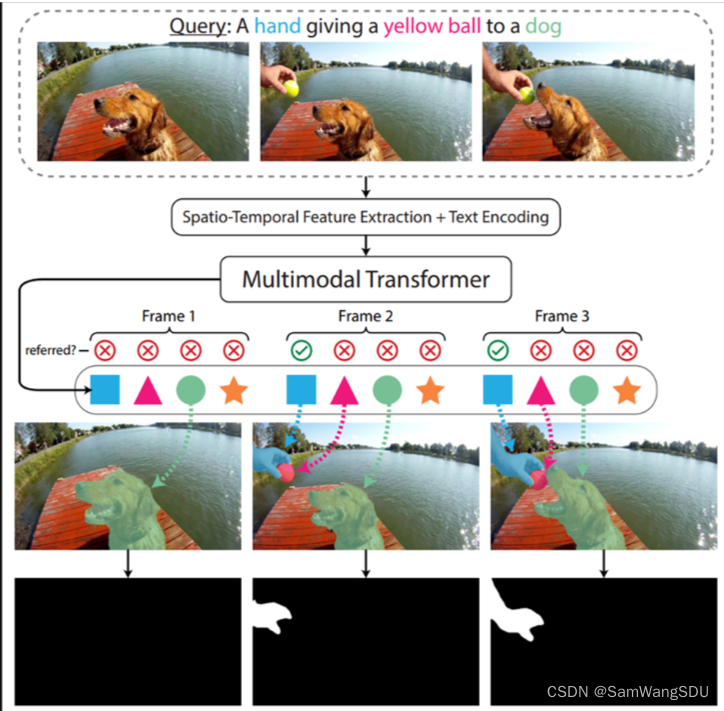
1、在服务器上部署了指代性视频物体分割模型MTTR:
该模型可以接受指定的视频和视频中某个物体的文本描述,分割出指定的物体,在输出的处理后的视频中,指定的物体被打上了掩码,在整个视频中达到了追踪的效果。
2、为MTTR模型实现了可调用接口
因为MTTR模型官方给出的代码中,只有训练代码和测试代码,并没有可直接调用模型预测的接口,因此我们首先为其实现了一个可直接调用的预测接口,方便部署到我们团队的项目中去,下面时接口的部分代码展示:
python">def save_masks_to_video(pred_masks, video_file_path, intermediate_output_path):# 打开原始视频文件cap = cv2.VideoCapture(video_file_path)if not cap.isOpened():print("Error opening video file")return# 获取视频的帧率和帧大小fps = cap.get(cv2.CAP_PROP_FPS)width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))size = (width, height)# 使用更兼容的编解码器fourcc = cv2.VideoWriter_fourcc(*'XVID')out = cv2.VideoWriter(intermediate_output_path, fourcc, fps, size)# 预处理掩码数据和读取帧sigmoid = torch.nn.Sigmoid()time, batch_size, num_queries, H_mask, W_mask = pred_masks.shapeframe_idx = 0while frame_idx < time:ret, original_frame = cap.read()if not ret:break# 处理掩码应用于视频帧mask = pred_masks[frame_idx, 0, 0]mask = sigmoid(mask)mask = mask > 0.5mask = mask.detach().cpu().numpy().astype(np.uint8)mask = cv2.resize(mask, size, interpolation=cv2.INTER_NEAREST)color_mask = np.zeros_like(original_frame)color_mask[mask == 1] = [0, 255, 0]masked_frame = cv2.addWeighted(color_mask, 0.2, original_frame, 0.8, 0)out.write(masked_frame)frame_idx += 1cap.release()out.release()print("Intermediate video saved at:", intermediate_output_path)# 使用 FFmpeg 转换视频格式到 H.264convert_video_to_h264(intermediate_output_path, f"H264_{intermediate_output_path}")
3、项目新功能:视频物体追踪
我们将MTTR模型部署到了我们的项目中去,以此实现了我们项目视频处理模块的第一个功能——视频物体追踪。用户可以上传一段视频,并给出一段文本描述,我们的系统可以对视频中的指定物体进行追踪,以下面的视频为例:
- 原视频
seagull
- 文本描述:“the flying seagull”,分割后的视频
result_seagull
4、在服务器上部署了“图生文”模型——CATR
“图生文”指的是可以根据输入的图片,返回一段对该图片的简单文本描述,CATR模型在“图生文”领域中有着较为不错的性能:

5、在服务器上部署了“文生图”模型——Stable-Diffusion
“文生图”指的是给模型一段文本描述,模型可以生成该文本描述的图片,也就是图像领域的AIGC。这里不难看出,在团队没有合适的“图生图”模型的情况下,可以结合“文生图”和“图生文”模型来达到“图生图”的效果。
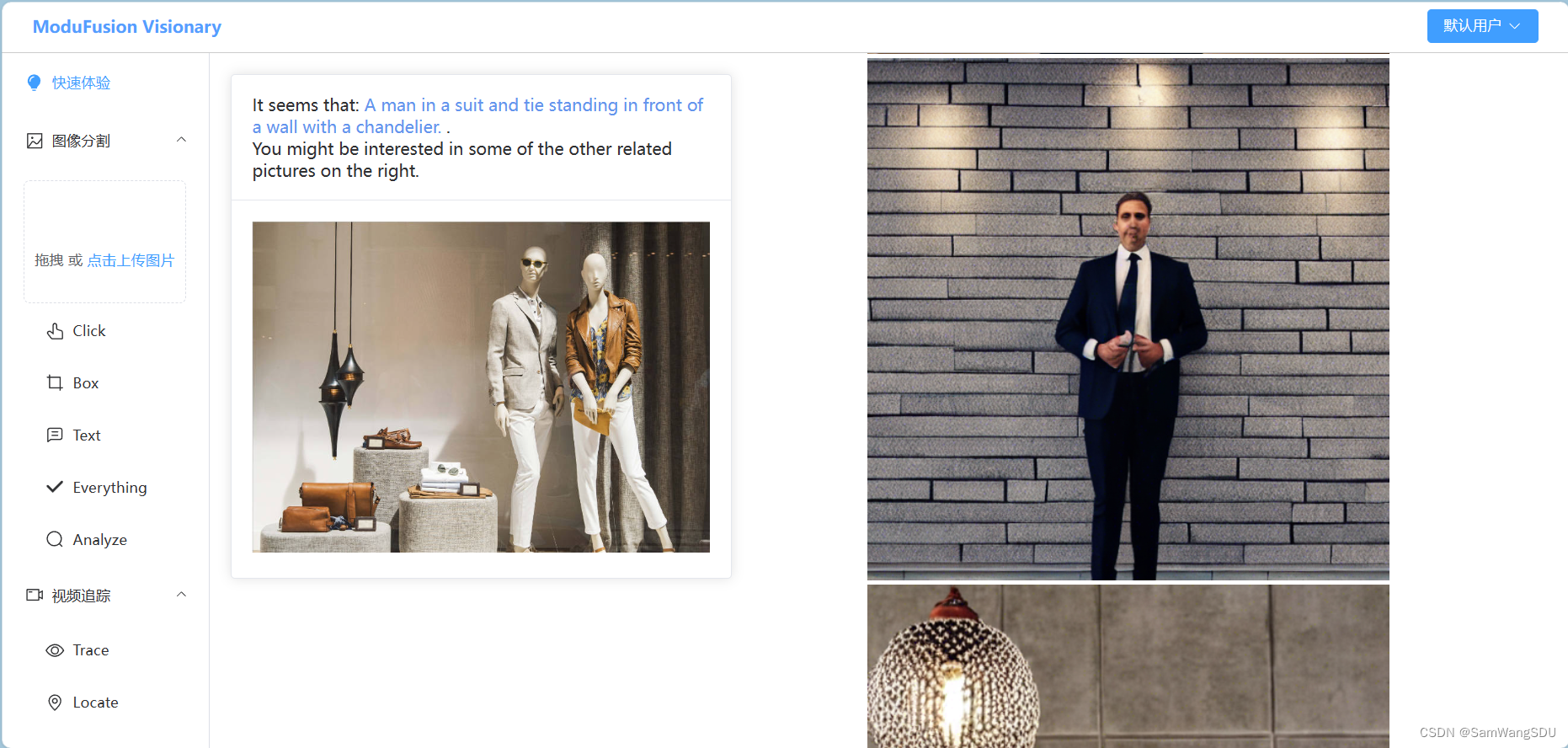
6、项目新功能——图片分析与生成
在结合了“图生文”模型CATR和“文生图”模型stable-diffusion的基础上,我们在项目的图片处理模块中增加了新功能——图片分析与生成。对于用户上传的图片,点击“Analyze”后,会调用服务器端的模型CATR对图片内容进行分析,并将分析的结果传递给stable-diffusion,stable-diffusion将据此生成多张新图片,两个模型预测和生成的结果都会返回给本地前端进行展示。
下一阶段工作计划
- 为视频模块的第二项功能——视频帧定位,寻找好的模型。
- 对现有功能进行修缮。



![[Rust开发]在Rust中使用geos的空间索引编码实例](https://img-blog.csdnimg.cn/img_convert/dd69614c137cedd7ebf831ae232263e8.png)