目录
- 前言
- 一、字符集
- 1.1 数据库中的默认字符集
- 1.2 各级别的字符集
- 1.3 字符集与比较规则
- 1.4 字符集设置
- 1.5 已有库表字符集变更
- 1.6 请求到响应过程中字符集的变化
- 二、大小写规范
- 2.1 Windows 和 Linux 平台区别
- 2.2 Linux 下大小写规则设置
- 2.3 SQL 编写建议
- 三、sql_mode 的合理设置
- 3.1 sql_mode 的介绍
- 3.2 sql_mode 常用值
- 3.3 模式查看与设置
下篇:第二章、数据库目录结构与文件系统
前言
目前市面上使用的 Mysql 大多数都是 mysql-8.0 或者是 mysql-5.7,以下内容是对 mysql 的字符集与大小规范的一个简单介绍
可以用以下命令查看 mysql 版本:
select version();

如果您想要查看更详细的版本信息,包括版本号、发行版本、系统名称和 description,可以使用以下命令:
SHOW VARIABLES LIKE "%version%";

以下内容主要源于:bilibili-尚硅谷-MySQL高级篇
MySQL 的安装教程:Linux-安装MySQL(详细教程)
一、字符集
如果使用过 mysql-5.7 的人,大多数都会遇到这样一种情况,就是当我们向数据库中存放一个 emoji 表情 “😃” 时,数据库中的数据是乱码的,如果将该表中的字符集改成 utf8mb4,就能正常存放 emoji 表情 “😃” 了,这个问题就与 mysql 的字符集密切相关
1.1 数据库中的默认字符集
在 Mysql-8.0 版本之前,默认的字符集为 Iantin1 ,开发人员在进行数据库设置的时候往往会需要将编码修改为 UTF-8 字符集,否则就可能出现乱码的问题
从 Mysql-8.0 开始,数据库的默认编码改为 utf8mb4,从而避免了上述的问题
通常情况下会使用以下命令查看 mysql 的默认字符集:
show variables like '%character%';
在 Mysql-8.0 中,默认的字符集如下:
mysql> show variables like '%character%';
+--------------------------+--------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8mb3 |
| character_sets_dir | /usr/share/mysql-8.0/charsets/ |
+--------------------------+--------------------------------+
8 rows in set (0.00 sec)
而在 Mysql-5.7 中,默认的字符集如下:
mysql> show variables like '%character%';
+--------------------------+--------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql-5.7/charsets/ |
+--------------------------+--------------------------------+
8 rows in set (0.00 sec)
- character_set_server:服务器级别的字符集
- character_set_database:当前数据库的字符集
- character_set_client:服务器解码请求时使用的字符集
- character_set_connection:服务器处理请求时会把请求字符串从 character_set_client 转换为 character_set_connection
- character_set_results 服务器向客户端返回数据时使用的字符集
这里主要关注的是 character_set_database 和 character_set_server
1.2 各级别的字符集
mysql 有 4 个级别的字符集和比较规则,分别是:
- 服务器级别
- 定义了
MySQL服务器实例的默认字符集 - 可以在
my.cnf或my.ini配置文件中设置,或使用SET GLOBAL character_set_server = 'charset_name';来动态更改 - 常见的服务器级别字符集有
utf8、utf8mb4、latin1等
- 定义了
- 数据库级别
- 定义了特定数据库的默认字符集
- 当创建数据库时,可以指定字符集,例如
CREATE DATABASE mydb CHARACTER SET utf8mb4; - 如果不指定,则使用服务器级别的默认字符集
- 表级别
- 定义了表中所有列的默认字符集
- 创建表时,可以指定字符集,例如
CREATE TABLE mytable (column1 VARCHAR(50)) CHARACTER SET utf8mb4; - 如果不指定,则使用数据库级别的默认字符集
- 列级别
- 定义了特定列的字符集
- 创建列时,可以指定字符集,例如
CREATE TABLE mytable (column1 VARCHAR(50) CHARACTER SET utf8mb4); - 如果不指定,则使用表级别的默认字符集
1.3 字符集与比较规则
可以通过以下命令查看 mysql 支持的字符集和比较规则:
show charset;
或者
show character set;
示例:
mysql> show character set;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| binary | Binary pseudo charset | binary | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.00 sec)
Charset 就是所支持的字符集,Description 是描述,Default collation 为对应的比较规则,Maxlen 字段表示所最大占用字节数量
比较规则
在上表中,MySQL 版本一共支持 41 种字符集,其中 Default collation 列表示这种字符集中一种默认的比较规则,里面包含着该比较规则主要作用于哪种语言,比如:uft8_polish_ci 表示以波兰语的规则比较,uft8_spanish_ci 是以西班牙语的规则比较,utf8_general_ci 是一种通用的比较规则。
| 后缀 | 英文释义 | 描述 |
|---|---|---|
| _ai | accent insensitive | 不区分重音 |
| _as | accent sensitive | 区分重音 |
| _ci | case insensitive | 不区分大小写 |
| _cs | case sensitive | 区分大小写 |
| _bin | binary | 以二进制方式比较 |
utf8_unicode_ci和utf_general_ci对中、英文来说没有实质性的差别,utf_general_ci速度较快,但是准确度稍差,utf8_unicode_ci准确度高,但是速度稍慢,一般情况下用utf_general_ci就够了,如果应用中有德语、法语或者是俄语,就需要使用utf8_unicode_ci
查看 utf8mb4 相关的字符集:
SHOW COLLATION LIKE 'utf8mb4%';
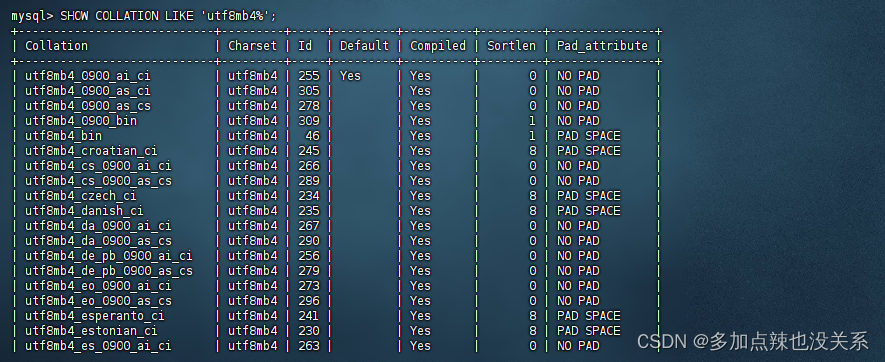
查看服务器的字符集和比较规则:
SHOW VARIABLES LIKE '%_server';

查看数据库的字符集和比较规则:
SHOW VARIABLES LIKE '%_database';

查看具体数据库的字符集和比较规则:
SHOW VARIABLES LIKE '%_database';
如果想要知道某一个数据库创建时是采用哪种字符集或比较规则,可以通过查看建库语句的 sql 查看:
show create database database_name;

如果想要知道某一个表创建时是采用哪种字符集或比较规则,可以通过查看建表语句的 sql 查看:
show create table table_name;
示例:
mysql> show create table t_access_log;
+--------------+----------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------------+----------------------------------------------------------------------------------------------------------+
| t_access_log | CREATE TABLE `t_access_log` (`id` int NOT NULL AUTO_INCREMENT COMMENT '自增主键',`login_name` varchar(64) DEFAULT NULL COMMENT '登录名',`access_path` varchar(255) DEFAULT NULL COMMENT '访问路径',`access_ip` varchar(16) DEFAULT NULL COMMENT '访问IP',`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`state` tinyint DEFAULT NULL COMMENT '访问状态',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='访问记录表' |
+--------------+----------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
utf8 与 utf8mb4 的区别
UTF-8 字符集表示一个字符需要使用 1~4 个字节,通常情况下一些字符只需要 1~3 个字节就可以表示了,而字符集表示一个字符所用的最大字节长度,在某些方面会影响系统的存储和性能,MySQL 的设计者定了两个概念:
utf8mb3:阉割的UTF-8字符集,只使用1~3个字节表示字符uft8mb4:正宗的UTF-8字符集,只使用1~4个字节表示字符
在 MySQL 中 utf8 是 utf8mb3 的别名,所以在 MySQL 中使用字符集尽量采用 uft8mb4,比如说前面举例的存入 emoji 表情 “😃” ,就需要使用 uft8mb4。
1.4 字符集设置
如果安装的是 mysql-5.7,通常情况下,会在安装好数据库之后修改其配置文件来设置字符集
修改 my.cnf (或者 my.ini)文件,以 linux 上为例:
编辑 my.cnf 文件
vi /etc/my.cnf

在 [mysqld] 标签下修改配置,例如:
character_set_server=utf8mb4

修改完配置文件后需要重启下 mysql 服务才会生效
# 启动 mysql
systemctl restart mysqld
在这之后创建的库或者是表就会默认使用 uft8mb4 字符集,但之前创建的库或者表并不会自动修改其字符集
1.5 已有库表字符集变更
修改已创建数据库的字符集:
alter database database_name character set 'utf8mb4';
修改已创建数据库的字符集和比较规则:
alter database database_name character set 'utf8mb4' collate 'utf8_general_ci';
修改已创建数据表的字符集:
alter table table_name convert to character set 'utf8mb4';
修改已创建数据表的字符集和比较规则:
alter table table_name convert to character set 'utf8mb4' collate 'utf8_general_ci';
1.6 请求到响应过程中字符集的变化
从客户端发往服务器的请求本质上就是一个字符串,服务器向客户端返回的结果本质上也是一个字符串,而字符串其实是使用某种字符集编码的二进制数据,从发送请求到返回结果的过程中可能会伴随着多次字符串的转换,其中主要涉及的三个变量如下:
| 系统变量 | 描述 |
|---|---|
| character_set_client | 服务器解码请求时使用的字符集 |
| character_set_connection | 服务器处理请求时会把请求字符串从character_set_client 转为character_set_connection |
| character_set_results | 服务器向客户端返回数据时使用的字符集 |
具体流程如下图所示:
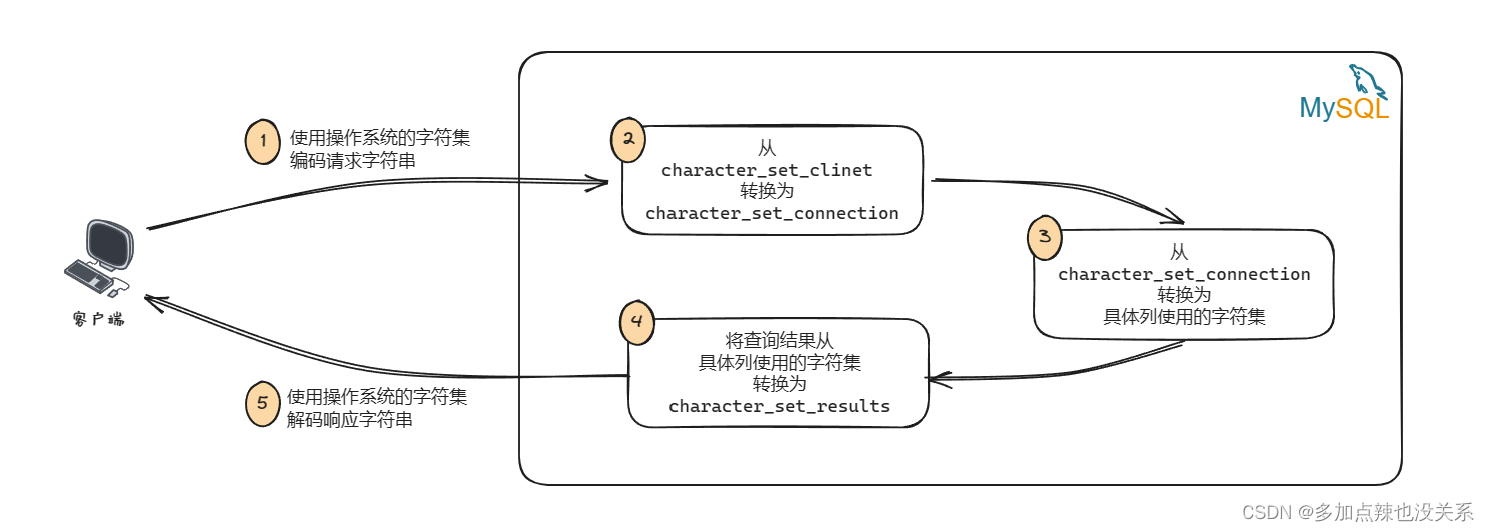
通常情况下,为了避免多次的字符串转换,通常情况下会将 character_set_client、character_set_connection、character_set_results 这三个系统变量设置成和客户端使用的字符集相一致
例如:
SET character_set_client = 字符集名;
SET character_set_connection = 字符集名;
SET character_set_results = 字符集名;
为了方便我们设置,MySQL 提供了一条非常简便的语句:
SET NAMES 字符集名;
例如:
SET NAMES utf8;
二、大小写规范
2.1 Windows 和 Linux 平台区别
在 SQL 中,关键字和函数名是不用区分字母大小写的,比如:SELECT、WHERE、ORDER、GROUP BY 等关键字,以及 ABS、MOD、ROUND、MAX 等函数名。
而表名、变量因平台的关系会有所不同,在 Windows 下 SQL 是不区分大小写的,而在 Linux 下 SQL 却区分大小写
所以就可能会出现这样一种情况,比如说你的项目中使用了类似于 quartz 这种定时器,在 Windows 上创建的表都是小写,但是一旦迁移到 Linux 上就会出现以下错误:
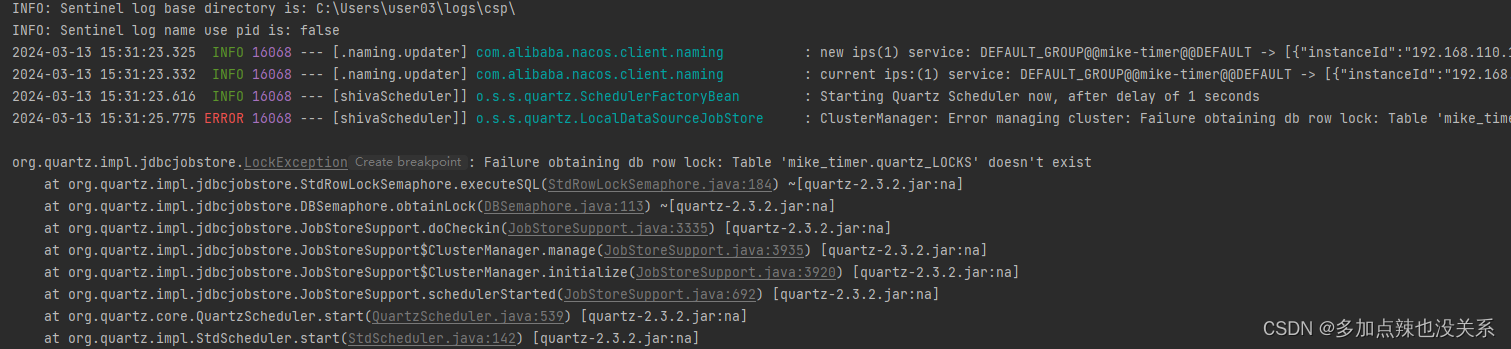
就是因为两个环境上对大小写敏感度不同所导致的
通常情况下我们可以通过以下命令查看大小写是否敏感:
SHOW VARIABLES LIKE '%lower_case_table_names';
- Windows 下
mysql> SHOW VARIABLES LIKE '%lower_case_table_names';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| lower_case_table_names | 1 |
+------------------------+-------+
1 row in set (0.00 sec)
- Linux 下
mysql> SHOW VARIABLES LIKE '%lower_case_table_names';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| lower_case_table_names | 0 |
+------------------------+-------+
1 row in set (0.00 sec)
lower_case_table_names 参数值的设置
0:大小写敏感1:大小写不敏感,创建的表、数据库都是以小写形式存放在磁盘上,对于SQL语句都是转换为小写对表和数据库进行查找2:创建的表和数据依据语句上的格式存放,凡是查找都是转换为小写进行
所以在 Linux 下会严格区分数据库、表名、表的别名、变量名的大小写,而在 Windows 下都不区分大小写
2.2 Linux 下大小写规则设置
在 Linux 下如果想要设置为大小写不敏感,mysql-5.7 只要在 my.cnf 文件中的添加或者修改 lower_case_table_names 的值为 1 ,然后再重启数据库即可
这里需要注意的是:在重启数据库之前需要将原来的数据和表名转换为小写,否则将找不到数据库和表
修改 my.cnf (或者 my.ini)文件
添加以下配置:
[mysqld]
lower_case_table_names = 1
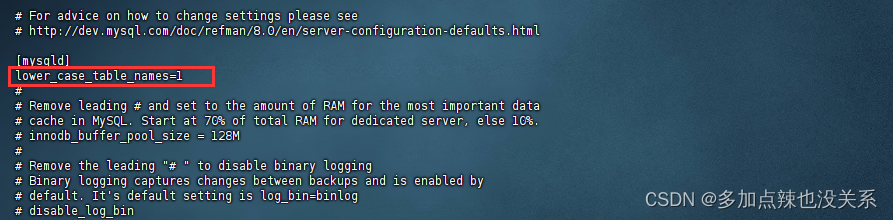
接着再重启 mysql
# 重启 mysql
systemctl restart mysqld
但是如果数据库使用的是 mysql-8.0,且数据库已经初始化过了,mysql 是不允许修改大小写敏感的
如果执意要修改可参见博客:MySQL8 设置大小写敏感
2.3 SQL 编写建议
在实际开发中,命名规范建议:
- ① 关键字和函数名名称全部用大写
- ② 数据库名、表名、表别名、字段名、字段别名等全部小写
- ③
SQL语句必须以分号;结尾
三、sql_mode 的合理设置
3.1 sql_mode 的介绍
sql_mode 会影响 MySQL 支持的 SQL 语法以及它执行的数据验证检查,通过设置 sql_mode 可以完成不同严格程度的数据校验,有效地保障数据的准确性。
MySQL 服务器可以在不同的 SQL 模式下运行,并且可以针对不同的客户端以不同的方式应用这些模式,具体取决于 sql_mode 系统变量的值。
mysql-5.6 和 mysql-5.7 默认的 sql_mode 模式参数是不一样的:
mysql-5.6的mode默认为空,即:NO_ENGINE_SUBSTITUTION,其实表示一个空值,相当于没有什么模式设置,可以理解为宽松模式,在这种设置下可以允许一些非法操作的,比如允许插入一些非法数据的插入mysql-5.7的mode默认为STRICT_TRANS_TABLES,也就是严格模式,用于进行数据的严格校验,错误数据不能插入,会报错,并且事务回滚
sql_model 常用来解决下面几类问题:
-
通过设置
sql_model, 可以完成不同严格程度的数据校验,有效地保障数据准备性 -
通过设置
sql_model为宽松模式,来保证大多数sql符合标准的sql语法,这样应用在不同数据库之间进行迁移时,则不需要对业务sql进行较大的修改 -
在不同数据库之间进行数据迁移之前,通过设置
sql_model可以使MySQL上的数据更方便地迁移到目标数据库中
3.2 sql_mode 常用值
| 值 | 描述 |
|---|---|
| ONLY_FULL_GROUP_BY | 对于 GROUP BY 聚合操作,如果在 SELECT 中的列,没有在 GROUP BY 中出现,那么这个 SQL 是不合法的,因为列不在 GROUP BY 从句中 |
| NO_AUTO_VALUE_ON_ZERO | 该值影响自增长列的插入。默认设置下插入 0 或 NULL 代表生成下一个自增长值。如果用户希望插入的值为 0,而该列又是自增长的,那么这个选项就有用了 |
| STRICT_TRANS_TABLES | 在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制 |
| NO_ZERO_IN_DATE | 在严格模式下,不允许日期和月份为零 |
| NO_ZERO_DATE | 设置该值,mysql 数据库不允许插入零日期,插入零日期会抛出错误而不是警告 |
| ERROR_FOR_DIVISION_BY_ZERO | 在 INSERT 或 UPDATE 过程中,如果数据被零除,则产生错误而非警告。如 果未给出该模式,那么数据被零除时 MySQL 返回 NULL |
| NO_AUTO_CREATE_USER | 禁止 GRANT 创建密码为空的用户 |
| NO_ENGINE_SUBSTITUTION | 如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常 |
| PIPES_AS_CONCAT | 将 || 视为字符串的连接操作符而非或运算符,这和 Oracle 数据库是一样的,也和字符串的拼接函数 Concat 相类似 |
| ANSI_QUOTES | 启用 ANSI_QUOTES 后,不能用双引号来引用字符串,因为它被解释为识别符 |
3.3 模式查看与设置
如果想要查看当前数据库用的 sql_mode 类型,可通过以下命令进行查看:
select @@session.sql_mode;
# 或者
select @@global.sql_mode;
临时设置方式:
# 修改当前会话的 sql_mode
set session sql_mode = '';# 修改全局 sql_mode
set global sql_mode = '';
永久设置方式:
在 my.cnf 或者 my.ini 文件中新增:
[mysqld]
sql_mode=ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
设置完成需要重启 mysql
在实际生产上,一般是采用 临时+永久 结合的方式,临时设置保证当前设置其效果,永久设置保证重启 mysql 之后依然使用所配置的 sql_mode。
下篇:第二章、数据库目录结构与文件系统




