第二章 线性数据结构.线性表.单链表
[5] 单链表的定义
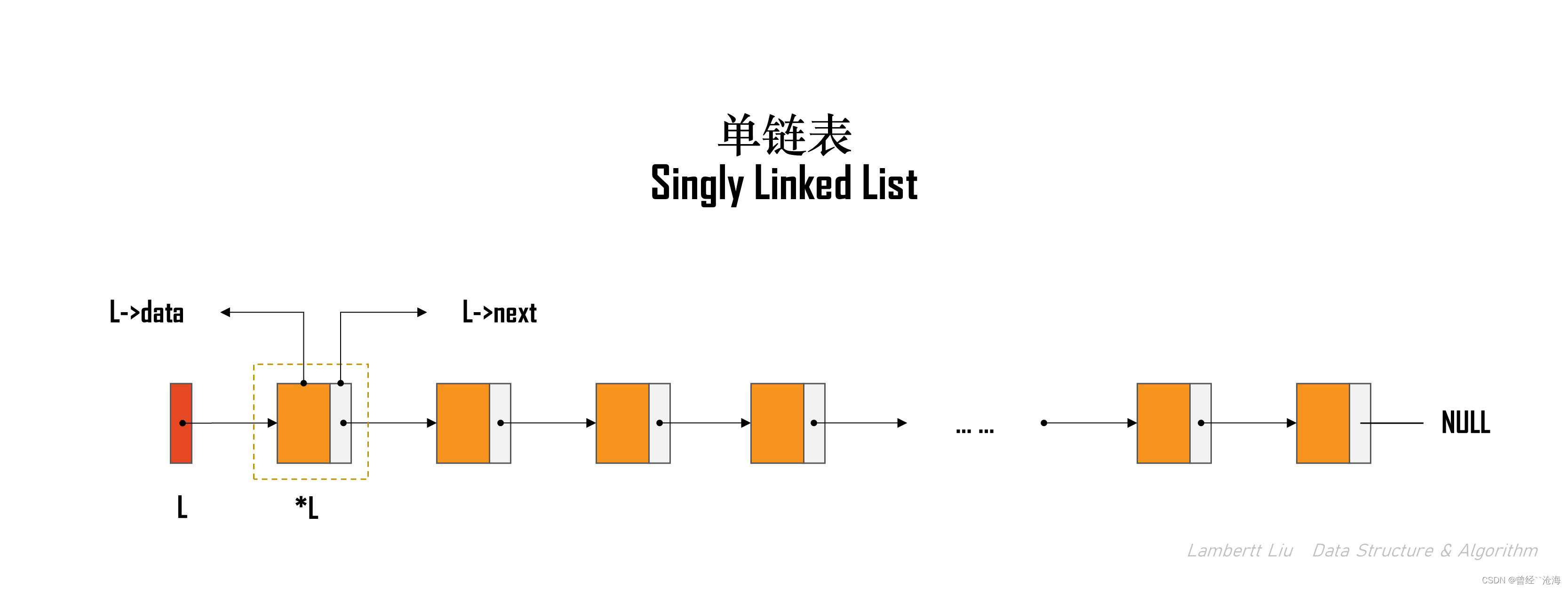
1.单链表
逻辑结构:是一种线性表。
顺序表(顺序存储):
- 优点:可随机存取,存储密度高
- 缺点:要求大片连续空间,改变容量不方便
- 特点:每个结点中只存放数据元素
单链表(链式存储):
- 优点:不要求大片连续空间,改变容量方便
- 缺点:不可随机存取,要耗费一定空间存放指针
- 特点:每个结点除了存放数据元素外,还要存储指向下一个结点的指针

2.用代码定义单链表
struct LNode {ElemType data;struct LNode *next;
}
struct LNode* p = (struct LNode*) malloc(sizeof(struct LNode));
上面的写法比较繁琐,因此用typedef进行重定义:
typedef struct LNode { // 定义单链表结点类型ElemType data; // 每个结点存放一个数据元素struct LNode *next; // 指针指向下一个结点
} LNode, *LinkList;
以下有两种定义:其中
LNode * L;
声明一个指向单链表第一个结点的指针,结构体指针,主要强调这是一个结点。
LinkList L;
声明一个指向单链表第一个结点的指针,结构体指针,主要强调这是一个单链表。

二者的表示是等价的,但是后者代码可读性更强。
3.初始化单链表
- 不带头结点的单链表
typedef struct LNode { // 定义单链表结点类型ElemType data; // 每个结点存放一个数据元素struct LNode *next; // 指针指向下一个结点
} LNode, *LinkList;bool InitList(LinkList &L) {// 防止出现脏数据L = NULL; // 空表,暂时还没有任何结点return true;
}void test()
{// 声明一个指向单链表的指针,这里的L是结构体指针// 注意此处并没有创建一个结点LinkList L;//初始化一个空表InitList(L);//......后续代码....
}
- 带头结点的单链表
typedef struct LNode { // 定义单链表结点类型ElemType data; // 每个结点存放一个数据元素struct LNode *next; // 指针指向下一个结点
} LNode, *LinkList;// 初始化一个单链表(带头结点)
bool InitList(LinkList &L){// 分配头结点L = (LNode*) malloc(sizeof(LNode));// 判断是否分配成功if (NULL == L) {return false;}// 头结点后暂时没有存放数据L->next = NULL;return true;
}void test(){// 声明一个指向单链表的指针,这里的L是结构体指针// 注意此处并没有创建一个结点LinkList L;// 初始化一个空表InitList(L);//......后续代码....
}
不带头结点,写代码更麻烦,需要对第一个数据结点和后续数据结点的处理,需要用不同的代码逻辑,对空表和非空表的处理需要用不同的代码逻辑。带头结点,一套代码完成,实现更方便。
以下代码如果不做特殊说明,则都指包含头结点。

[6] 单链表的插入删除
1.按照位序插入
带头结点
首先以带头结点为例子,实现插入:
// 在表 L 中的第 i 个位置上插入了指定元素e,
// 注意:这里的i表示的是位序,即前i - 1的元素均保持不动,新的元素的新位序是i,原位序 i 后的结点依次推移。
ListInsert(&L, i, e);
插入过程分以下几步:
- 遍历找到第 i - 1 个结点;
- 分配新结点,填充数据域;
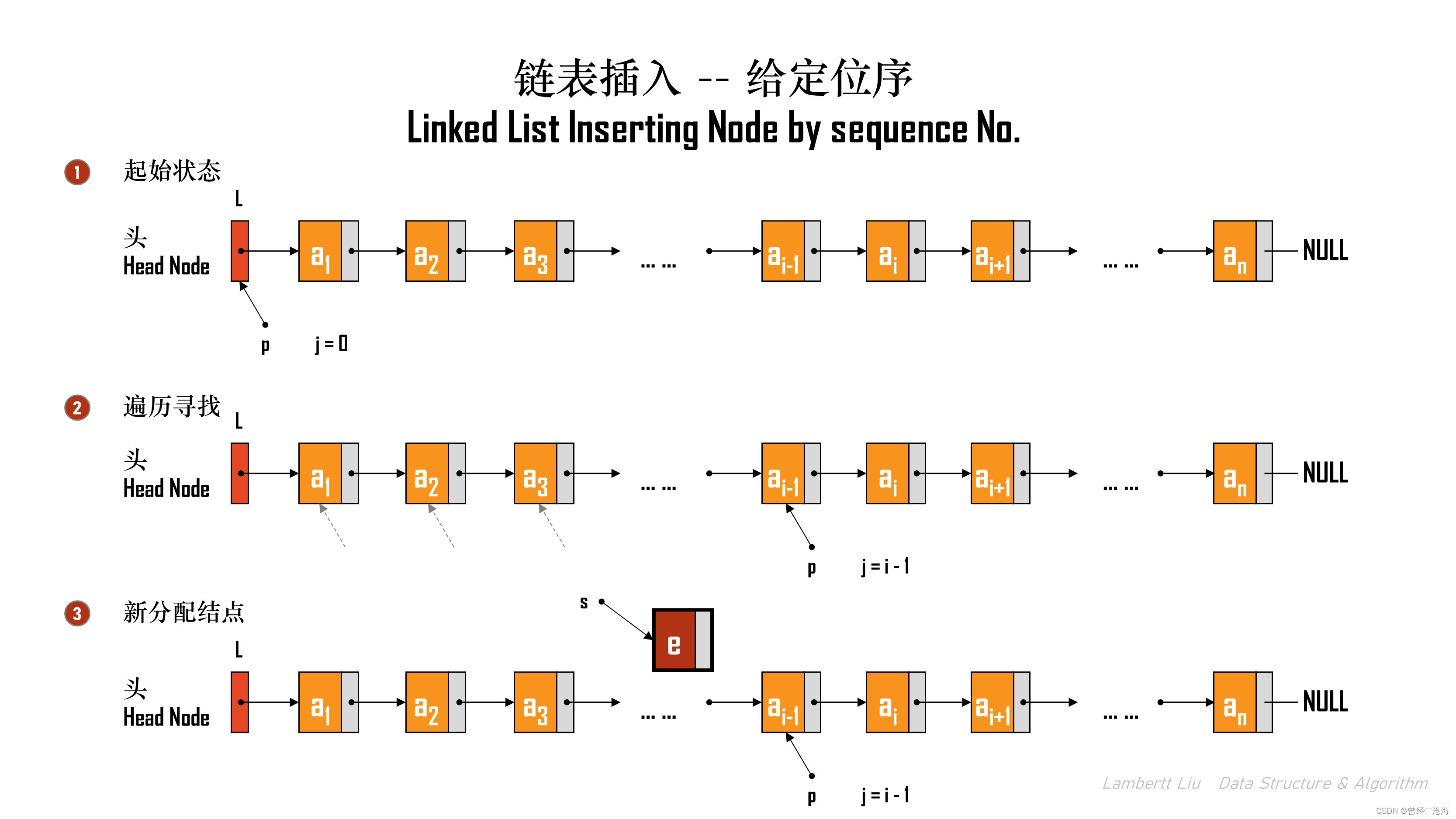
- 新结点后继为所寻结点的后继,新结点成为所寻结点的后继。
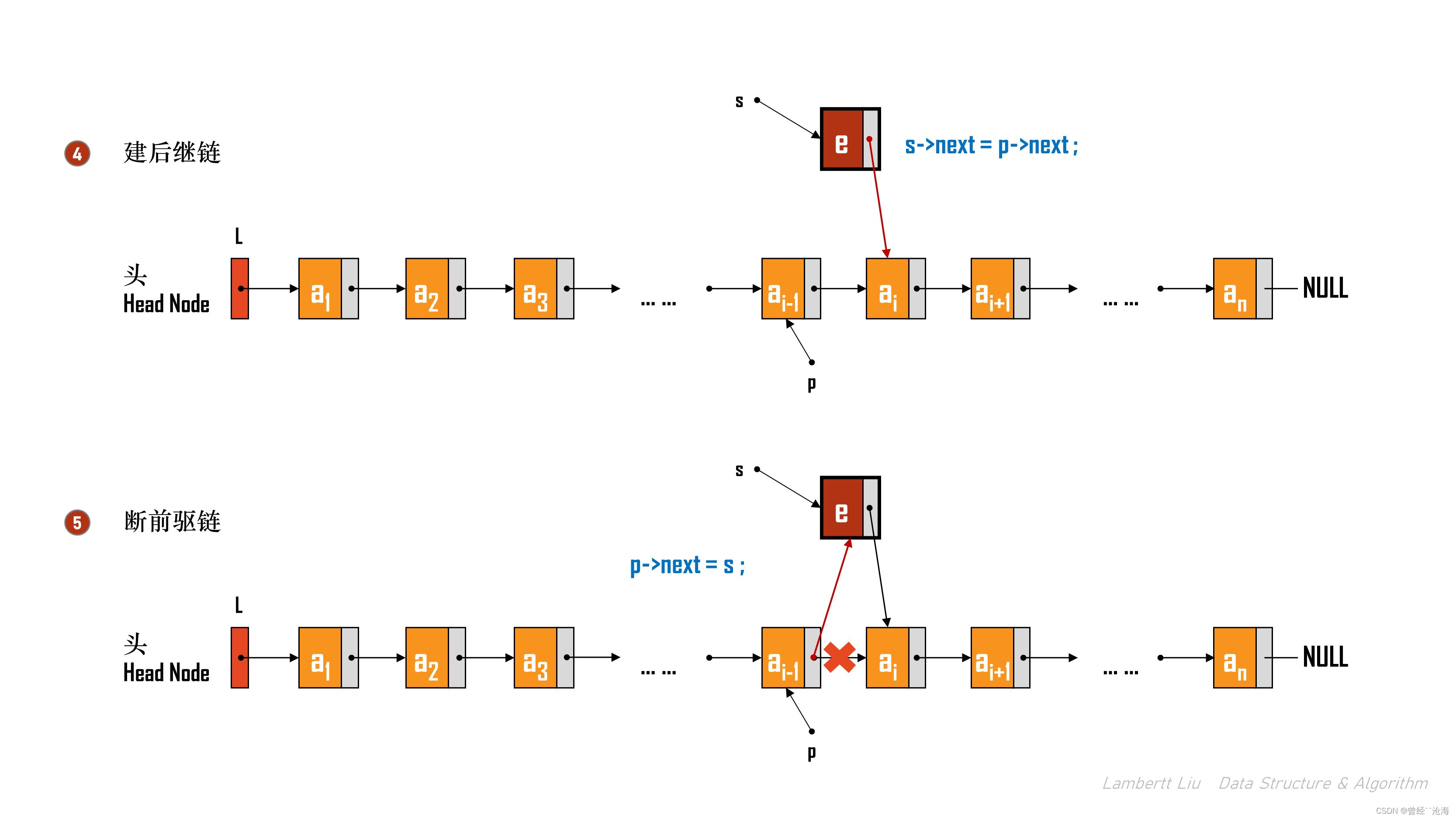
- 插入完成。
程序实现:
typedef struct LNode {ElemType data;struct LNode *next;
} LNode, *LinkList;// 在第 i 个位置插插入元素e ,链表带头结点
bool ListInsert(LinkList &L, int i, ElemType e)
{if (i < 1) {return false;}LNode *p; // 结构体指针p, 指向当前扫描到的结点int j = 0; // 当前p指向的是第j个结点p = L; // L 指向头结点,头结点是第0个结点(不存数据)// 循环找到第 i - 1 个结点// 非空表示不能到链表尽头了,j < i - 1,表示要找到第 i - 1 个结点就停下来了while (p != NULL && j < i - 1) { p = p->next;j++;}// 到这里 p 指向了第 i - 1 个结点// 校验发现第 i - 1个结点是空的,这就表示原链表只有 i - 2 个结点,第 i - 2 个结点的后继是空指针。if (p == NULL) { return false;}LNode *s = (LNode *)malloc(sizeof(LNode));// malloc 返回值必须校验if (s == NULL) {return false;}s->data = e;s->next = p->next; p->next = s; // 将结点s连到p之后return true; // 插入成功
}
因为遍历结点是n阶,因此,时间复杂度:O(N)。
不带头结点
再以不带头结点为例子,实现插入,由于不带头结点,不存在“第0个”结点。
插入方法:
- 如果是首个添加结点,直接分配,插入作头结点。
- 如果不是首个添加结点,遍历找到第 i - 1 个结点;
- 分配新结点,填充数据域;
- 新结点后继为所寻结点的后继,新结点成为所寻结点的后继。
- 插入完成。
typedef struct LNode {ElemType data;struct LNode *next;
} LNode, *LinkList;bool ListInsert(LinkList &L,int i,ElemType e){if (i < 1) {return false;}if (i == 1) {LNode *s = (LNode*)malloc (sizeof(LNode));if (s == NULL) {return false;}s->data = e; // 给数据域赋值s->next = L; // 新指针,代替指向原来的头结点的指针L = s; // 用L指针指向现在的新头结点return true;}// 以下过程同代头结点插入过程类似LNode* p;int j = 1; // 当前p指向了第1个结点;p = L;while (p != NULL && j < i - 1){p = p->next;j++;}// 循环找到第 i - 1 个结点if (p == NULL) {return false;}LNode* s = (LNode*)malloc(sizeof(LNode));if (s == NULL) {return false;}s->data = e;s->next = p->next;p->next = s;return true;
}
结论:不带头结点的场景,对插入位序为 1 的情况做特殊处理,得考虑两种情况,写代码更不方便,推荐用带头结点,一套代码兼容所有场景。
因此,以下的代码实现均以包含头结点为例子。
2.在某个指定结点后插元素
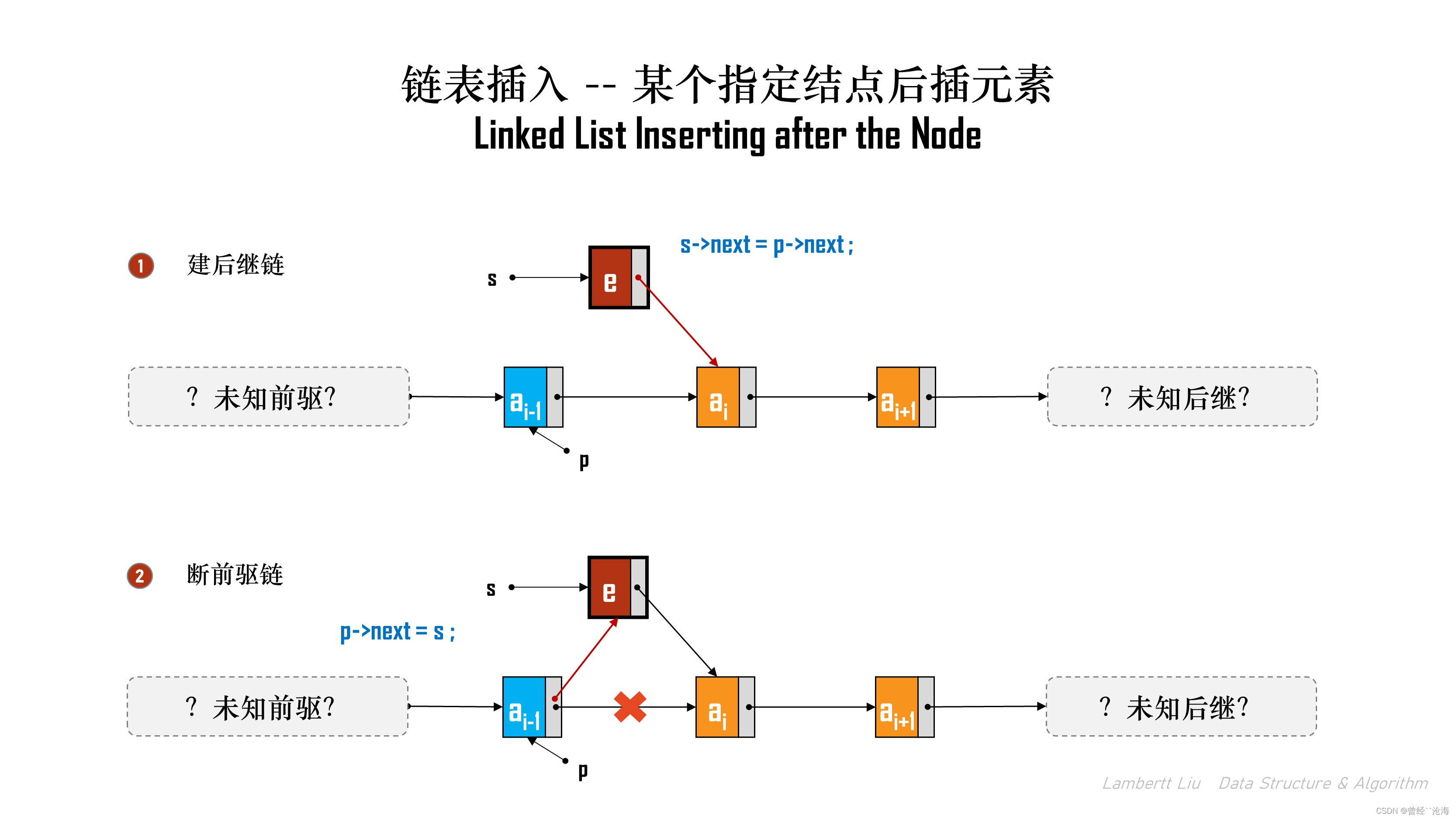
这个过程实际上就是在“按位序插入的基础上”,省略了遍历寻找结点的过程。直接对结点进行插入操作。
// 在p结点后插入元素 e
bool InsertNextNode(LNode* p, ElemType e)
{if (p == NULL) {return false;}LNode *s = (LNode*)malloc(sizeof(LNode));// 判定内存是否申请成功if (s == NULL) {return false;}// 链表插入数据分三步,填数,建后继链,断前驱链s->data = e;s->next = p->next;p->next = s;return true;
}
该算法的时间复杂度是O(1)。
3.在某个指定结点前插元素
方法1:常规算法
// 循环遍历查找p的前驱,再对q后插。
InsertPriorNode(Linklist L, LNode *p, ElemType e);
常规做法,是遍历找到那个结点的前驱结点,对前驱结点执行插入操作。
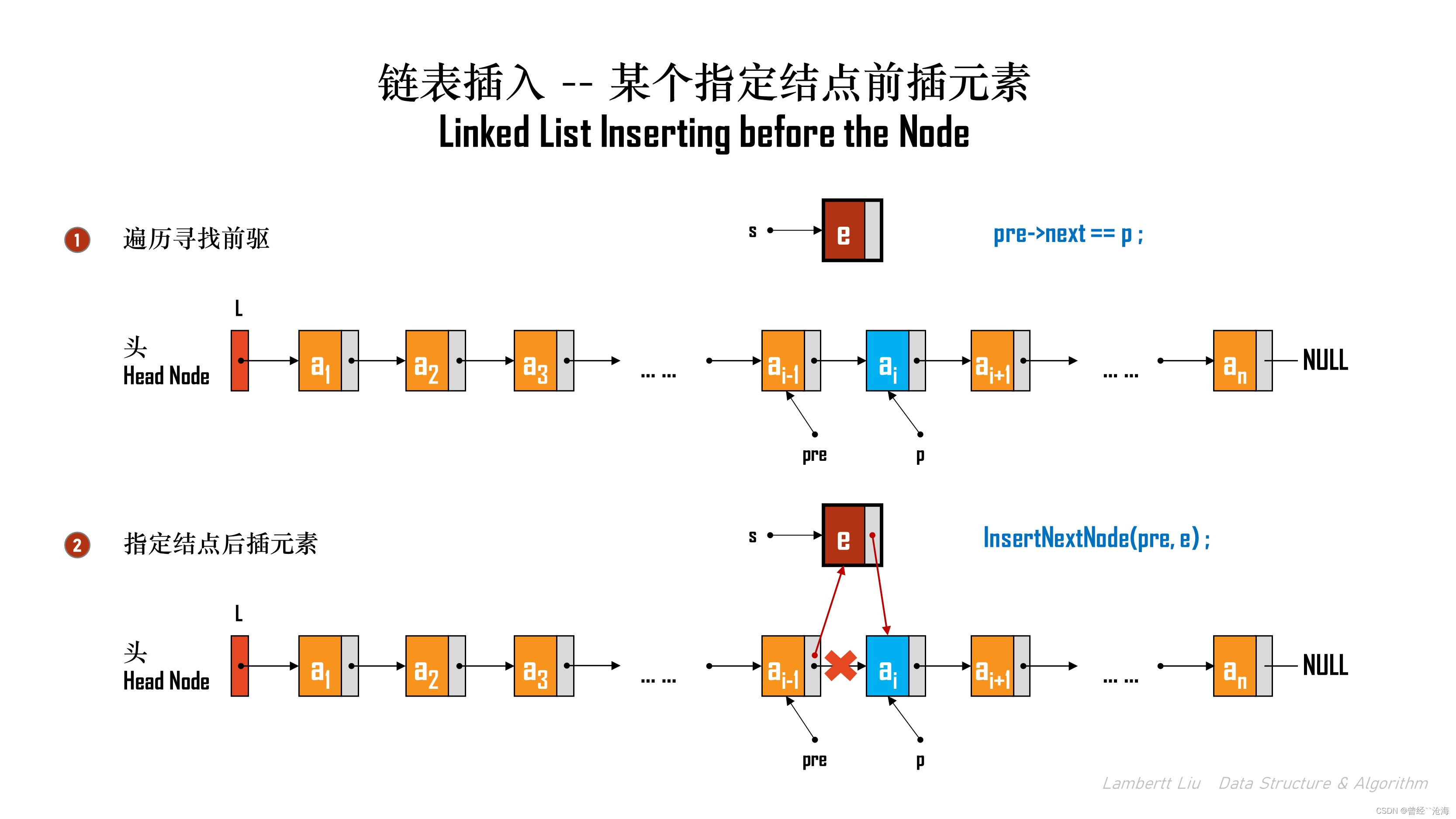
程序实现:
bool InsertPriorNode(Linklist L, LNode *p, ElemType e)
{if (p == NULL) {return false;}LNode * pre = L; // 前驱结点// 遍历循环查找while (pre != NULL) {if (pre->next == p) {break;}pre = pre->next;}// 如果找不到,那就是空值if (pre == NULL) {return false;}// 直接调用指定结点后插元素,在p的前一个结点插入,即是在p的前驱结点的后一个插入return InsertNextNode(pre, e);
}
这种算法,必须依赖有链表头。
该算法的时间复杂度是O(N) 。
方法2:交换结点算法
还有另一种算法,本质是Swap替换。
插入方法:
- 直接对指定结点进行后插操作。
- 交换新结点与指定结点的数据域;
- 插入成功;
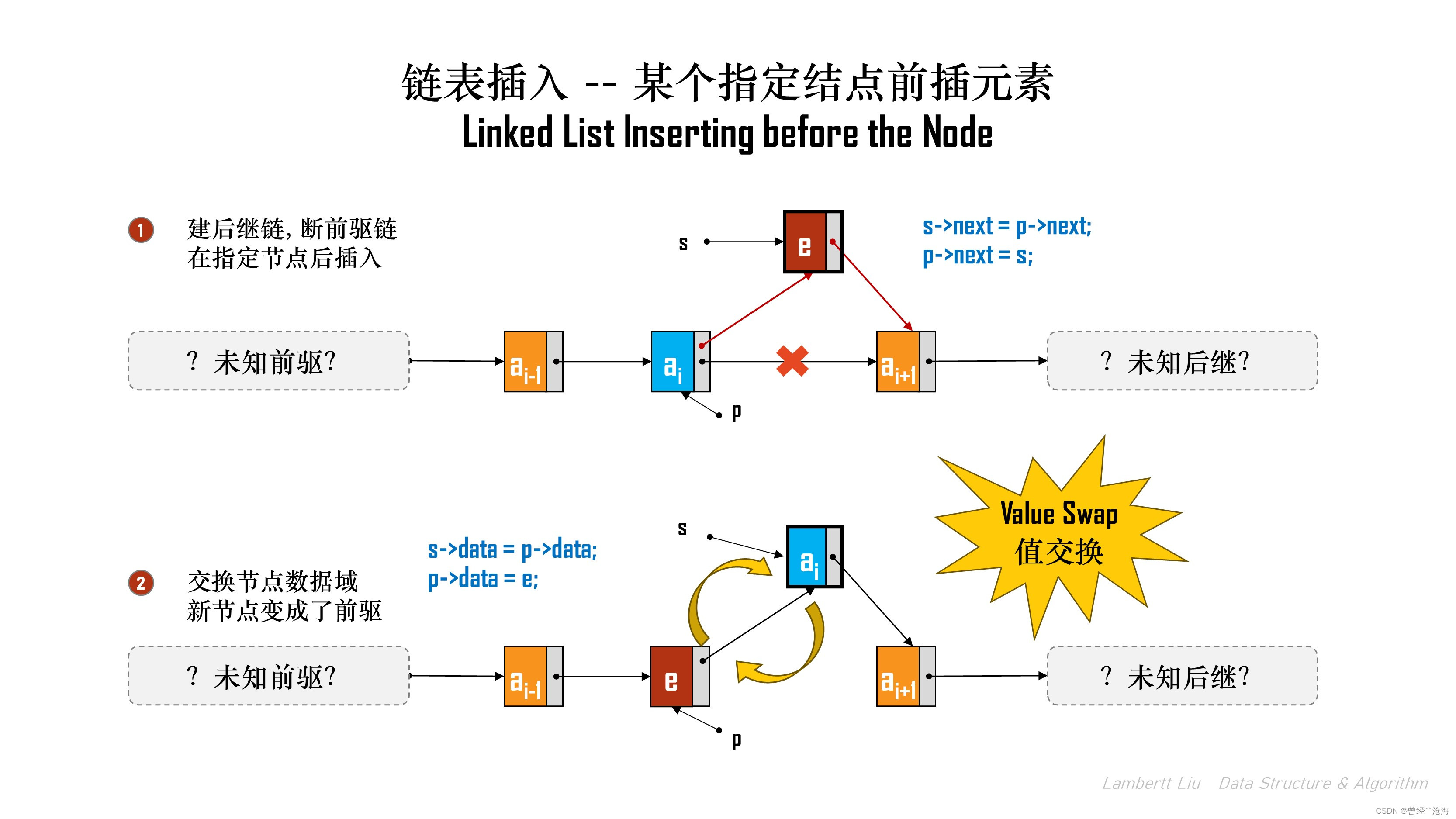
bool InsertPriorNode(LNode *p, ElemType e)
{if (p == NULL) {return false;}LNode *s = (LNode*)malloc(sizeof(LNode));// 判定内存是否申请成功if (s == NULL) {return false;}// 解链,重新成链s->next = p->next;p->next = s;// 数据交换swaps->data = p->data;p->data = e;return true;
}
看上去是一种在指定结点的后向插入,但是交换完数据后,后继变成了前驱。
该算法的时间复杂度是O(1).
[7] 单链表的删除
1.按位序删除
// 删除操作。删除表L中第i个位置的元素,并用e返回删除元素的值。
ListDelete(&L, i, &e);
方法:
以带头结点的链表为例,头结点可以看作“第0个”结点,遍历找到第 i-1 个结点,将其指针指向第 i+1 个结点,并释放第 i 个结点。
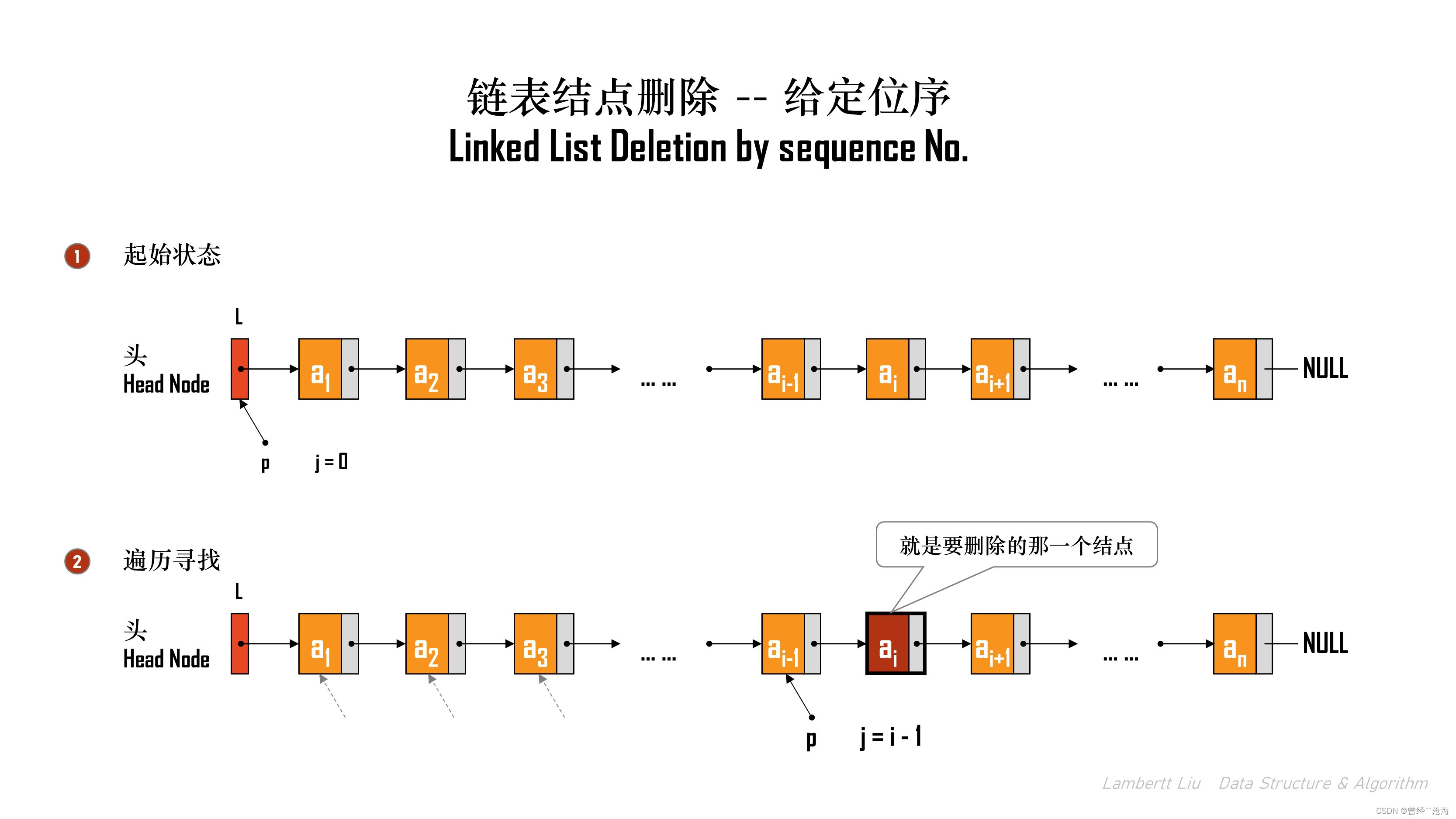
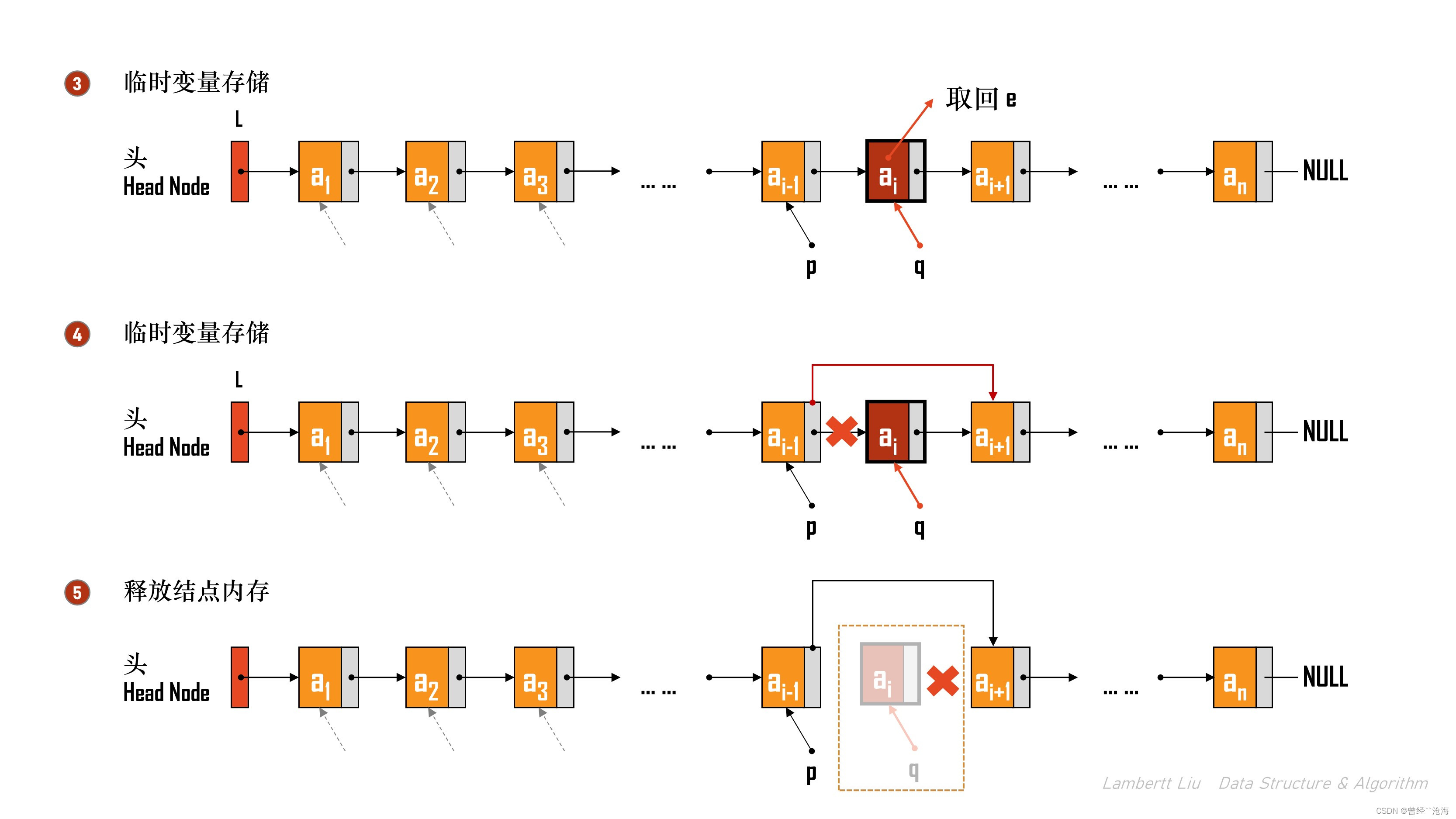
bool ListDelete(Linklist &L, int i, ElemType &e)
{if (i < 1) {return false;}LNode *p; // 结构体指针p, 指向当前扫描到的结点int j = 0; // 当前 p 指向的是第 j 个结点p = L; // L 指向头结点,头结点是第0个结点(不存数据)// 循环找到第 i-1 个结点while (p != NULL && j < i - 1) { p = p->next;j++;}if (p == NULL) {return false; // i值不合法} // 第i-1个结点后没有其他结点,不存在第i个结点if (p -> next == NULL) {return false; }// 到这里的代码都和指定位序插入结点相同LNode *q = p->next; // 令q指向被删除结点,即临时变量e = q->data; // 用e把返回值带回来p->next = q->next; // 将*q结点从链中断开free(q); // 释放结点的存储空间return true; // 删除成功
}
该算法的时间复杂度是O(N)
2.指定结点的删除
对于指定结点删除与"在某个指定结点前插元素"类似,有两种方法。
方法1:常规遍历
传入头指针 L ,循环寻找 p 的前驱结点,与某个指定结点前插元素方法1类似,暂时作省略。
方法2:交换结点数据域
第二种方式,类似于结点前插的实现,“偷天换日”。
- 临时结点,存储指定结点的下一个结点;
- 指定结点与下一个结点交换数据域;
- 删除指定结点的下一个结点(临时结点),此时临时结点内的数据已经保存替换,而指向了继续的结点;
- 释放临时结点。
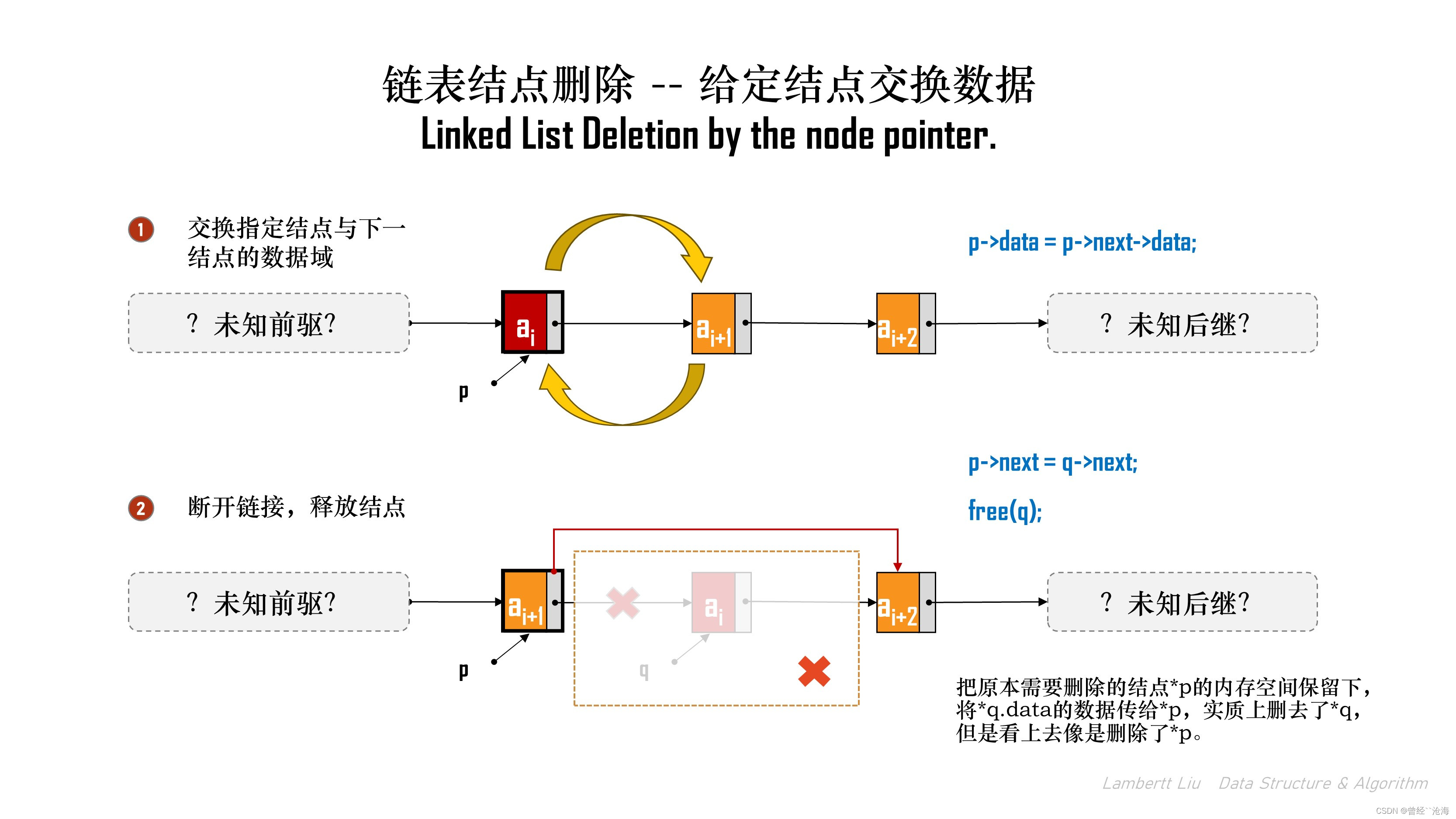
以下以方法2为例,用代码实现:
bool DeleteNodeBySwap(LNode *p, ElemType &e)
{// 校验是否符合条件if (p == NULL || p->next == NULL) {return false;}e = p->data;LNode *q = p->next; // 令q指向*p的后继结点p->data = p->next->data; // 和后继结点交换数据域p->next = q->next; // 将*q结点从链中断开free(q);return true;
}
以上的时间复杂度是O(1)。
注意,以上删除方式依赖p的下一个结点一定不是空,必须要有数据域,这样才有交换的前提。
从语法上,对空指针解引用 p->next->data也是非合法操作。如果p是最后一个结点,即下一个结点并不存在,那么只能从表头开始依次寻找p的前驱,时间复杂度 O(N)。
[8] 单链表的查找
链表的查找与顺序表类似,分为按位和按值查找,一个是已知序号求值,一个是已知值求序号(结点)。
1.按位查找
// 按位查找,获取L中的第i个为主的元素的值。
GetElem(L, i);
代码实现:
LNode* GetElem(Linklist L,int i)
{if (i < 0) {return NULL;}LNode *p;int j = 0;p = L;while (p != NULL && j < i) {p = p->next;j++;}
}
时间复杂度 O(N)。
2.按值查找
// 按值查找,在表L中查找具有给定关键字值的元素。
LocateElem(L, e);
代码实现:
LNode * LocateElem(LinkList L, ElemType e)
{LNode *p = L->next;// 从第一个结点开始查找数据域为e的结点while (p != NULL && p->data != e) {p = p->next;}return p; // 找到后返回该结点指针,否则返回NULL
}
时间复杂度 O(N)
3.求表的长度
遍历表从表头指表尾,每次迭代,长度自增。
代码实现:
// 包含头结点,仅有头结点,长度为0
int GetLength(LinkList L)
{int len = 0;LNode *p = L;while (p->next != NULL) {p = p->next;len++;}return len;
}
[9] 单链表的建立
单链表的建立,主要分两步:
- 初始化单链表;
- 将元素逐个插入到链表中。
1.尾插法
尾插法,顾名思义,将结点一个一个依次插入到链表尾部。
算法利用伪代码实现:
首先初始化一个链表,
设置变量length记录链表长度
while (没有取完) {每次取一个数据元素e;ListInsert(L, length+1, e),插到尾部;length++;
}
常规做法
每次取新结点,都从头结点开始遍历到尾部,然后将结点插入到尾部。
代码实现:
bool ListInsert(LinkList &L, int i, ElemType e)
{if (i < 1) {return false;} LNode *p;int j = 0;p = L;// 循环找到第 i-1 个结点while (p != NULL && j < i - 1) {p = p->next;j++;}if (p== NULL) {return false;}LNode *s = (LNode *)malloc(sizeof(LNode));if (s == NULL) {return false;}// 开始插入s->data = e;s->next = p->next;p->next = s; // 把结点s连到p之后return true;
}
以上的时间复杂度是 O ( N 2 ) O(N^2) O(N2) ,并不好。
算法优化
变化思路,将链表值依次输入,并使用一个临时变量记录尾部结点。
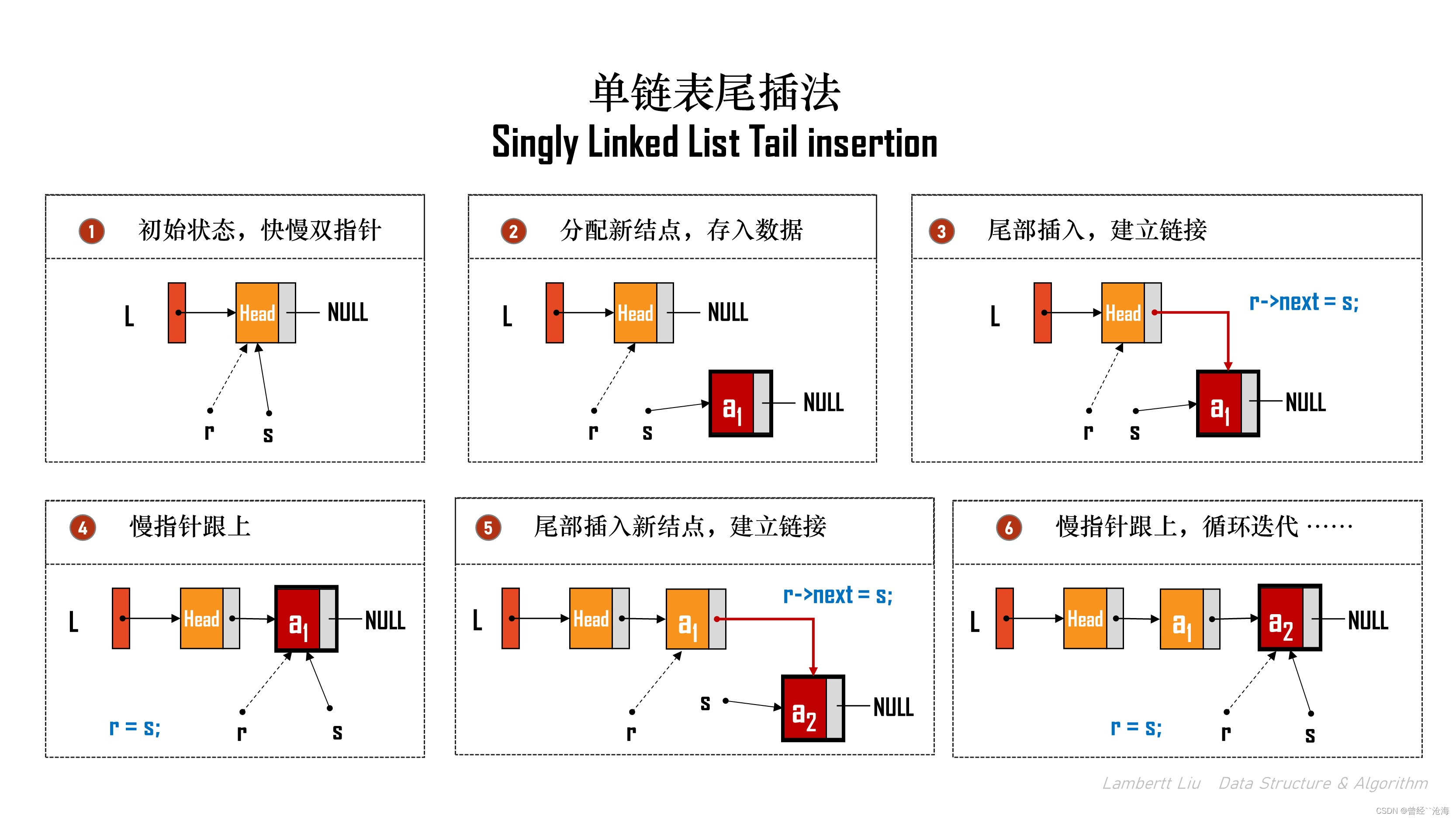
LinkList List_TailInsert(LinkList &L)
{ // 正向建立单链表int x; // ElemType -> 整型L = (LinkList)malloc(sizeof(LNode)); // 头结点if (L == NULL) {return NULL;}LNode *s, *r = L; // r为表尾指针while(scanf("%d", &x) != EOF){s = (LNode*)malloc(sizeof(LNode));if (s == NULL) {// ... 清理内存代码...return NULL;}s->data = x;r->next = s;r = s;}r->next = NULL;return L;
}
以上的时间复杂度是O(N)。
2.头插法
头插法是一个对指定结点的核心操作。
具体方法:
初始化单链表
while (没有取完) {每次取一个数据元素e;ListInsertNode(L,e);
}
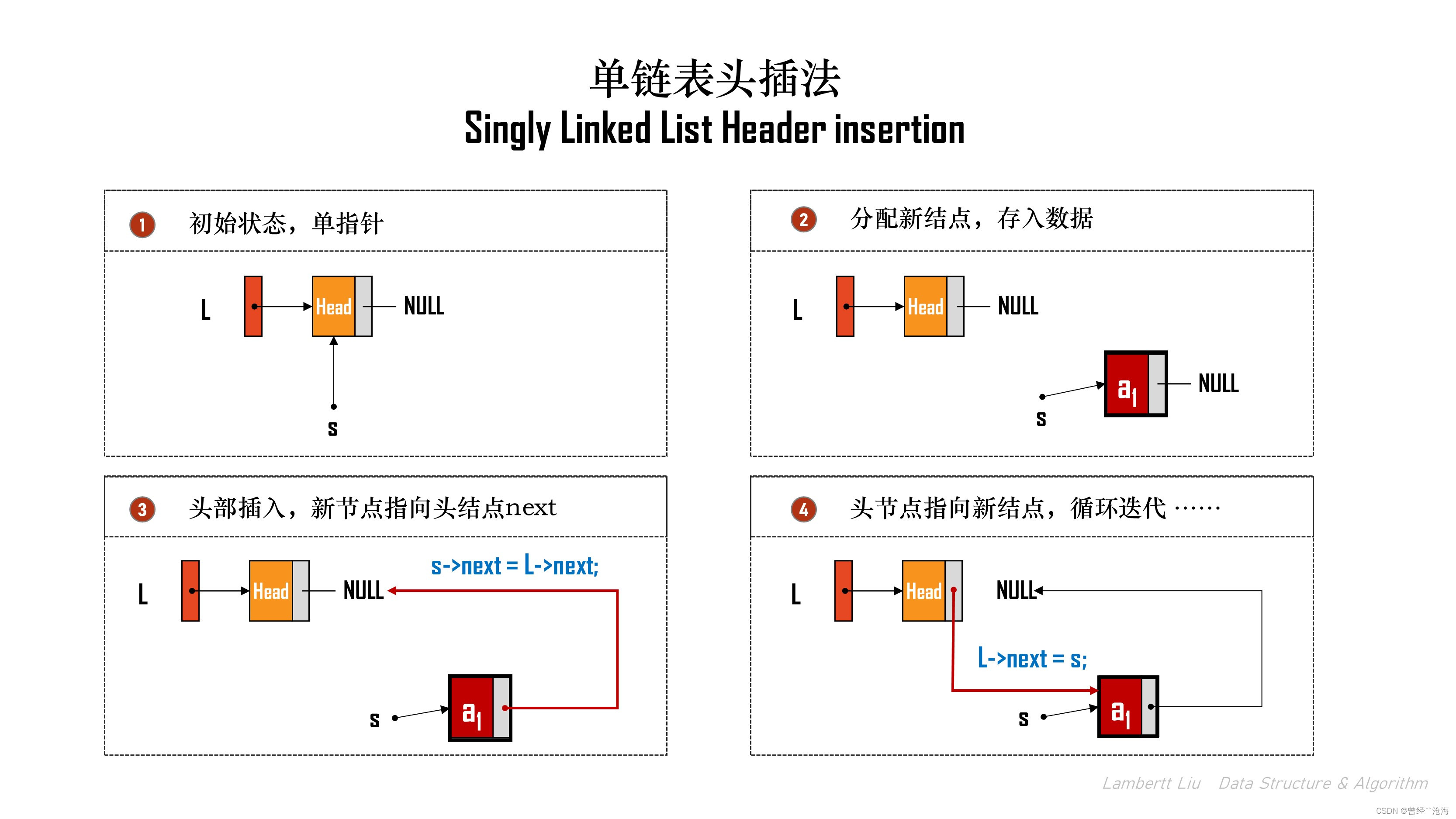
代码实现:
LinkList List_HeadInsert(LinkList &L)
{LNode *s;int x;L = (Linklist)malloc(sizeof(LNode)); // 创建头结点if (L == NULL) {return NULL;}L->next = NULL;while (scanf("%d",&x) != EOF) {s = (LNode*)malloc(sizeof(LNode));if (s == NULL) {// ... 清理内存代码...return NULL;}s->data = x;s->next = L->next;L->next = s;}return L;
}
注意:
养成好习惯,只要是初始化指针,都需要先把头指针指向NULL。
尾插法,十分适用于链表逆置。