如何自己训练一个图片分类模型,如果一切从头开始,对于一般公司或个人基本是难以实现的。其实,我们可以利用一个现有的图片分类模型,加上新的分类,这种方式叫做迁移学习,就是把现有的模式知识,转移到新的模型。Pytorch 官网提供已经训练好的模型,可以在此基础上训练自己的模型。我们用的模型是 VGG 分类模型,首先,先运行一个已经训练好的模型可做 1000 个分类。
安装依赖
# 去官网根据系统进行下载
pip3 install torch torchvision torchaudio
pip3 install tqdm
现有模型进行图片识别
可以去百度上下载一个狗或者鸟的图片,运行下面的程序进行识别。
# 导入软件包
import numpy as np
import json
from PIL import Imageimport torch
import torchvision
from torchvision import models, transforms#生成VGG-16模型的实例
use_pretrained = True # 使用已经训练好的参数
net = models.vgg16(pretrained=use_pretrained)
net.eval() # 设置为推测模式# 对输入图片进行预处理的类
class BaseTransform():"""调整图片的尺寸,并对颜色进行规范化。Attributes----------resize : int指定调整尺寸后图片的大小mean : (R, G, B)各个颜色通道的平均值std : (R, G, B)各个颜色通道的标准偏差"""def __init__(self, resize, mean, std):self.base_transform = transforms.Compose([transforms.Resize(resize), #将较短边的长度作为resize的大小transforms.CenterCrop(resize), #从图片中央截取resize × resize大小的区域transforms.ToTensor(), #转换为Torch张量transforms.Normalize(mean, std) #颜色信息的正规化])def __call__(self, img):return self.base_transform(img)# 根据输出结果对标签进行预测的后处理类
class ILSVRCPredictor():"""根据ILSVRC数据,从模型的输出结果计算出分类标签Attributes----------class_index : dictionary将类的index与标签名关联起来的字典型变量"""def __init__(self, class_index):self.class_index = class_indexdef predict_max(self, out):"""获得概率最大的ILSVRC分类标签名Parameters----------out : torch.Size([1, 1000])从Net中输出结果Returns-------predicted_label_name : str预测概率最高的分类标签的名称"""maxid = np.argmax(out.detach().numpy())predicted_label_name = self.class_index[str(maxid)][1]return predicted_label_name
# 载入ILSVRC的标签信息,并生成字典型变量
ILSVRC_class_index = json.load(open('./data/imagenet_class_index.json', 'r'))# 生成ILSVRCPredictor的实例
predictor = ILSVRCPredictor(ILSVRC_class_index)# 读取输入的图像
image_file_path = './data/jww2.webp'
img = Image.open(image_file_path) # [ 高度 ][ 宽度 ][ 颜色RGB]# 完成预处理后,添加批次尺寸的维度
resize = 224
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
transform = BaseTransform(resize, mean, std) #创建预处理类
img_transformed = transform(img) # torch.Size([3, 224, 224])
inputs = img_transformed.unsqueeze_(0) # torch.Size([1, 3, 224, 224])# 输入数据到模型中,并将模型的输出转换为标签
out = net(inputs) # torch.Size([1, 1000])
result = predictor.predict_max(out)# 输出预测结果
print("输入图像的预测结果:", result)我识别的是一只吉娃娃的图片,结果正确,Chihuahua。
现有的模型已经可以正常工作了,下面就是添加新的分类了,这里使用了蚂蚁和蜜蜂。把 1000 个分类改为了 2个分类。
net.classifier[6] = nn.Linear(in_features=4096, out_features=2)
import glob
import os.path as osp
import random
import numpy as np
import json
from PIL import Image
from tqdm import tqdmimport torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import torchvision
from torchvision import models, transformstorch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)class ImageTransform():"""图像的预处理类。训练时和推测时采用不同的处理方式对图像的大小进行调整,并将颜色信息标准化训练时采用 RandomResizedCrop 和 RandomHorizontalFlip 进行数据增强处理Attributes----------resize : int指定调整后图像的尺寸mean : (R, G, B)各个颜色通道的平均值std : (R, G, B)各个颜色通道的标准偏差"""def __init__(self, resize, mean, std):self.data_transform = {'train': transforms.Compose([transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)), #数据增强处理transforms.RandomHorizontalFlip(), #数据增强处理transforms.ToTensor(), # 转换为张量transforms.Normalize(mean, std) # 归一化]),'val': transforms.Compose([transforms.Resize(resize), #调整大小transforms.CenterCrop(resize), #从图像中央截取resize×resize大小的区域transforms.ToTensor(), #转换为张量transforms.Normalize(mean, std) #归一化])}def __call__(self, img, phase='train'):"""Parameters----------phase : 'train' or 'val'指定预处理所使用的模式"""return self.data_transform[phase](img)# 创建用于保存蚂蚁和蜜蜂的图片的文件路径的列表变量def make_datapath_list(phase="train"):"""创建用于保存数据路径的列表Parameters----------phase : 'train' or 'val'指定是训练数据还是验证数据Returns-------path_list : list保存了数据路径的列表"""rootpath = "./data/hymenoptera_data/"target_path = osp.join(rootpath+phase+'/**/*.jpg')print(target_path)path_list = [] # 保存到这里# 使用 glob 取得包括示例目录的文件路径for path in glob.glob(target_path):path_list.append(path)return path_listclass HymenopteraDataset(data.Dataset):"""蚂蚁和蜜蜂图片的Dataset类,继承自PyTorch的Dataset类Attributes----------file_list : 列表列表中保存了图片路径transform : object预处理类的实例phase : 'train' or 'test'指定是学习还是验证"""def __init__(self, file_list, transform=None, phase='train'):self.file_list = file_list # 文件路径列表self.transform = transform # 预处理类的实例self.phase = phase # 指定是train 还是valdef __len__(self):'''返回图片张数'''return len(self.file_list)def __getitem__(self, index):'''获取预处理完毕的图片的张量数据和标签'''#载入第index张图片img_path = self.file_list[index]img = Image.open(img_path) #[高度][宽度][颜色RGB]#对图片进行预处理img_transformed = self.transform(img, self.phase) # torch.Size([3, 224, 224])#从文件名中抽取图片的标签if self.phase == "train":label = img_path[30:34]elif self.phase == "val":label = img_path[28:32]#将标签转换为数字if label == "ants":label = 0elif label == "bees":label = 1return img_transformed, label# 执行
train_list = make_datapath_list(phase="train")
val_list = make_datapath_list(phase="val")#执行
size = 224
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
train_dataset = HymenopteraDataset(file_list=train_list, transform=ImageTransform(size, mean, std), phase='train')val_dataset = HymenopteraDataset(file_list=val_list, transform=ImageTransform(size, mean, std), phase='val')#指定小批次尺寸
batch_size = 32#创建DataLoader
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)#集中到字典变量中
dataloaders_dict = {"train": train_dataloader, "val": val_dataloader}#确认执行结果
batch_iterator = iter(dataloaders_dict["train"]) #转换成迭代器
inputs, labels = next(batch_iterator) #取出第一个元素# 载入已经学习完毕的VGG−16模型
#创建VGG−16模型的实例
use_pretrained = True #指定使用已经训练好的参数
net = models.vgg16(pretrained=use_pretrained)#指定使用已经训练好的参数
net.classifier[6] = nn.Linear(in_features=4096, out_features=2)#设定为训练模式
net.train()print('网络设置完毕 :载入已经学习完毕的权重,并设置为训练模式')# #设置损失函数
criterion = nn.CrossEntropyLoss()params_to_update = []#需要学习的参数名称
update_param_names = ["classifier.6.weight", "classifier.6.bias"]#除了需要学习的那些参数外,其他参数设置为不进行梯度计算,禁止更新
for name, param in net.named_parameters():if name in update_param_names:param.requires_grad = Trueparams_to_update.append(param)print(name)else:param.requires_grad = Falseoptimizer = optim.SGD(params=params_to_update, lr=0.001, momentum=0.9)def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs):#epoch循环for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch+1, num_epochs))print('-------------')# 每个epoch中的学习和验证循环for phase in ['train', 'val']:if phase == 'train':net.train() #将模式设置为训练模式else:net.eval() #将模式设置为验证模式epoch_loss = 0.0 #epoch的合计损失epoch_corrects = 0 #epoch的正确答案数量#为了确认训练前的验证能力,省略epoch=0时的训练if (epoch == 0) and (phase == 'train'):continue#载入数据并切取出小批次的循环for inputs, labels in tqdm(dataloaders_dict[phase]):#初始化optimizeroptimizer.zero_grad()#计算正向传播(forward)with torch.set_grad_enabled(phase == 'train'):outputs = net(inputs)loss = criterion(outputs, labels) #计算损失_, preds = torch.max(outputs, 1) #预测标签##训练时的反向传播if phase == 'train':loss.backward()optimizer.step()#计算迭代的结果# 计算迭代的结果epoch_loss += loss.item() * inputs.size(0) # 更新正确答案数量的总和epoch_corrects += torch.sum(preds == labels.data)#显示每个epoch的loss和正解率epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))num_epochs=2
train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
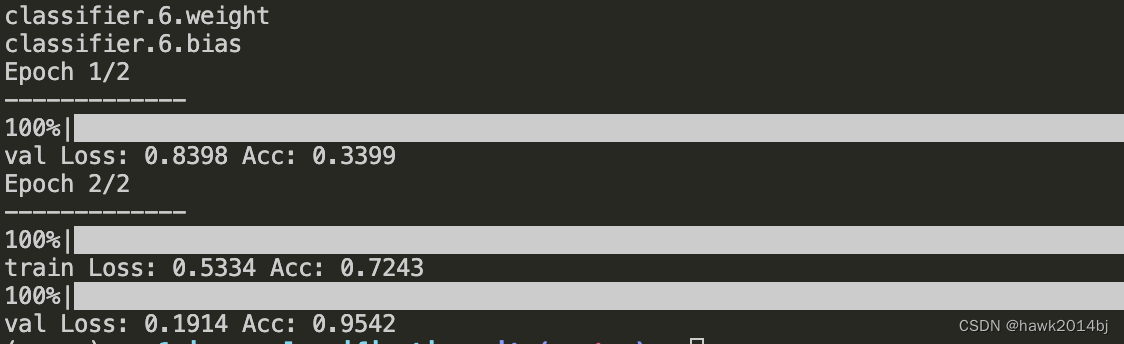
通过运行结果可以看到,首次没有训练直接在原始模型进行测试,正确率 33%,第二轮,经过 8 次迭代学习,正确率提高到 72%,这里比较奇怪的是验证集的正确率更高。原因是训练集做了数据增广,有些图片是变形的,所以识别起来更加困难。