目录
- 一. 难点总结
- 1. 数据类型
- 2. 函数与方法的区别
- 3. object、class、case class、case object、package object
- 4. 伴生对象和 apply() 到底有什么用
- 5. 模式匹配 unapply(),case class 和 偏函数
- 6. 隐式转换
- 7. 泛型
- 二.参考文章
一. 难点总结
1. 数据类型
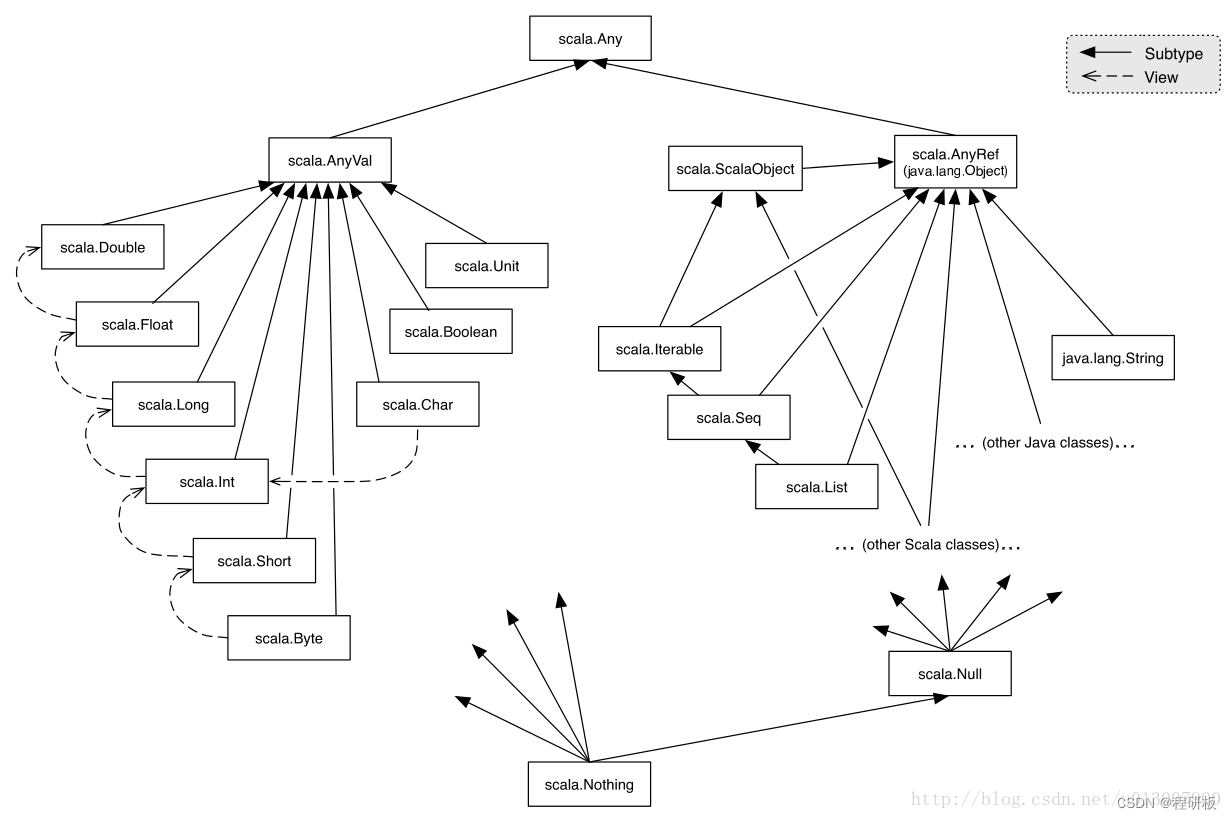
scala">def test1():Any = {List}// 类似于 Java 的 Object
def test2():AnyRef = {List}def test3():AnyVal = {1}
Unit、Null、Nothing、Nil、None 的区别:
scala">// AnyVal 类型的子类
def test4():Unit = {}// AnyRef 类型的子类
def test5():Null= {null}// Nothing 表示抛出异常 或者 集合为空,是最底层的子类
def test6():Int = {if(1 < 0) 1 else throw new Exception } // 实际会返回 Nothingdef test7():List[Nothing] = {List()}def test8():List[Nothing] = {Nil}// None 是对象 不是类,它的类型是 Option[Nothing]
def test9():Option[String] = { Map("France"->"Paris").get("a") } //返回 Some(Paris) 或者 None 对象
2. 函数与方法的区别
首先了解下函数与方法的区别:Scala 方法是类的一部分,而 函数 是一个对象可以赋值给一个变量。方法本质上是一个特殊的函数。
scala> val a = 1 //数据类型赋值给变量
a: Int = 1scala> val f1 = (x:Int,y:Int) => x + y //函数赋值给变量
f1: (Int, Int) => Int = <function> //<function>就是 x + y 这个函数体,是一个 lambda 表达式scala> def m(x: Int) = x + 3 //定义方法
m: (x: Int)Intscala> val f2 = m _ //方法转换为函数
f2: Int => Int = <function2>
Scala 中的函数则是一个完整的对象。方法中可以传函数,对象构造器也可以传函数。map 函数也称为高阶函数。
scala">def map[U: ClassTag](f: T => U): RDD[U] = withScope { //方法的形参为一个函数val cleanF = sc.clean(f)new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF)) //主构造器
}
scala">class Test{def m(x: Int) = x + 3 //方法val f = (x: Int) => x + 3 //变量val f2 = (x: Int, y: Int) => x + y //变量def m1(f:(Int,Int) => Int) : Int = { //方法的形参为一个函数f(2,6)}print(m1(f2)) // 输出 8
}
3. object、class、case class、case object、package object
- object:相当于单例对象,可以直接使用。
- class:类定义
- case class:
- 是用于创建不可变(immutable)且具有模式匹配能力的类。
- 重写了 toString、equals、hashCode 方法。
- 伴生对象中提供了apply方法,所以可以不使用new关键字就可构建对象。
- 提供 unapply 方法使模式匹配可以工作。
- case object:既是一个单例对象,又具有模式匹配的能力。
- package object:包下的单例对象,对象名与包名相同。
4. 伴生对象和 apply() 到底有什么用
伴生对象 => 单例对象,当做工具类使用,尽量来操作这个对象。
延申知识点:java 中有 static 和 单例。
scala">val a = Array(1,2,3)
// 使用的是 Array 的这个伴生对象,伴生对象() => 就是调用对象中的 apply() 方法。
apply() => 语法糖,val a = Array(1,2,3) 底层 new 的细节被屏蔽了。
scala">object ApplyApp {def main(args: Array[String]): Unit = {for(i<- 1 to 10){ApplyTest.incr}println(ApplyTest.count) //结果为10,说明object本身就是一个单例对象val b=ApplyTest() //因为在object的apply已经new了,所以此处就不用了new了//此时调用Object ApplyTest里面的apply方法val c=new ApplyTest()println(c) //此处c默认使用toString方法c() //此处调用class 里面的apply方法/* 即类名()=->object里面的apply方法:val b=ApplyTest()* 对象()==>class里面的apply方法:val c=new ApplyTest()*/}
}
scala">//class ApplyTest是object ApplyTest的伴生类
class ApplyTest{def apply() ={println("class ApplyTest里面的apply方法被调用")}
}//object ApplyTest是class ApplyTest的伴生对象
object ApplyTest{println("伴生对象进入")var count=0def incr={count=count+1}
//一般情况下,我们在object里面的apply方法中去new classdef apply() ={println("object ApplyTest里面的apply方法被调用")new ApplyTest}println("伴生对象离开")
}
5. 模式匹配 unapply(),case class 和 偏函数
unapply 是接受一个对象,从对象中提取出相应的值,主要用于模式匹配中。
scala">class Money(val value: Double, val country: String) {}
object Money {def apply(value: Double, country: String) : Money = new Money(value, country)def unapply(money: Money): Option[(Double, String)] = {if(money == null) {None} else {Some(money.value, money.country)}}
}val money = Money(10.1, "RMB")
money match {case Money(num, "RMB") => println("RMB: " + num)case _ => println("Not RMB!")
}
直接使用 case class,不用自己实现 unapply 方法
scala">val person = new Person("Alice", 25)person match {case Person("Alice", 25) => println("Hi Alice!")case Person("Bob", 32) => println("Hi Bob!")case Person(name, age) =>println("Age: " + age + " year, name: " + name + "?")}// 样例类
case class Person(name: String, age: Int)
偏函数:就是用花括号包围一些 case 语句。
scala">object PartialFunctionExample extends App {val multiplyByTwo: PartialFunction[Int, Int] = {case x => x * 2}println(multiplyByTwo(2)) // 输出: 4
}
6. 隐式转换
主要作用一:模拟新的语法
- select中的 $ 是隐式转换
import spark.implicits._
df.select($"name", $"age" + 1).show()implicit class StringToColumn(val sc: StringContext) {def $(args: Any*): ColumnName = {new ColumnName(sc.s(args: _*))}
}
- map中的 -> 是隐式转换
val map = Map(1 -> "one")implicit final class ArrowAssoc[A](private val self: A) extends AnyVal {@inline def -> [B](y: B): Tuple2[A, B] = Tuple2(self, y)def →[B](y: B): Tuple2[A, B] = ->(y)
}
主要作用二:类型增强与扩展
- rdd 的 api 并没有 toDF() 方法,如果要使用必须的隐式转化
import spark.implicits._val peopleRDD: RDD[String] = spark.sparkContext.textFile("D:\\study\\people.txt")
val peopleDF: DataFrame = peopleRDD.map(_.split(",")) //RDD.map(x => People(x(0), x(1).trim.toInt)) //RDD.toDF()implicit def rddToDatasetHolder[T : Encoder](rdd: RDD[T]): DatasetHolder[T] = {DatasetHolder(_sqlContext.createDataset(rdd))
}
Spark 中的 RDD 以及它的子类是没有 groupByKey, reduceByKey 以及 join 这一类基于 key-value 元组的操作的,但是在你使用 RDD 时,这些操作是实实在在存在的,Spark 正是通过隐式转换将一个 RDD 转换成了 PairRDDFunctions
implicit def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null): PairRDDFunctions[K, V] = {new PairRDDFunctions(rdd)
}
7. 泛型
类泛型
- java泛型
public class People<T>{//成员变量private T t;
}
- scala 主构造器泛型
scala">class People[T](val t: T)
- 视图界定
scala">class MaxValue[T <: Comparable[T]](val first:T, val second:T){ //泛型def bigger = if(first.compareTo(second) > 0) first else second
}print(new MaxValue[Integer](1, 2).bigger)
Integer 实现了 Comparable[Integer] 接口,能正常运行。
- 泛型和隐式转换
scala">class MaxValue[T <: Comparable[T]](val first:T, val second:T){ //泛型def bigger = if(first.compareTo(second) > 0) first else second
}print(new MaxValue[Int](1, 2).bigger)
Int 没实现了 Comparable[Int] 接口,不能能正常运行。
将 T <: Comparable[T] 改为 T <% Comparable[T],会隐式转换将 Int 转为 Integer,就能正常运行。
二.参考文章
Scala 方法与函数
Scala中的下划线使用总结
为什么Scala在类中没有静态成员?
java中的静态类
秒懂设计模式之建造者模式
scala中的apply方法与unapply方法
【Scala】使用Option、Some、None,避免使用null
scala 里怎样判空,比如java中防止空指针异常而做出的Null判断,以及字符串blank判断等?
Scala之隐式转换
SparkSql学习之:toDF方法的由来(源码)