💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。

- 推荐:「stormsha的主页」👈,持续学习,不断总结,共同进步,为了踏实,做好当下事儿~
- 专栏导航
- Python面试合集系列:Python面试题合集,剑指大厂
- GO基础学习笔记系列:记录博主学习GO语言的笔记,该笔记专栏尽量写的试用所有入门GO语言的初学者
- 数据库系列:详细总结了常用数据库 mysql 技术点,以及工作中遇到的 mysql 问题等
- 运维系列:总结好用的命令,高效开发
- 算法与数据结构系列:总结数据结构和算法,不同类型针对性训练,提升编程思维
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨
| 💖The Start💖点点关注,收藏不迷路💖 |
📒文章目录
- 1. 生成对抗网络(GANs)
- 1.1 生成器(Generator)
- 1.2 判别器(Discriminator)
- 1.3 对抗训练
- 1.4 代码讲解
- 2. 变分自编码器(VAEs)
- 2.1 编码器(Encoder)
- 2.2 解码器(Decoder)
- 2.3 损失函数
- 2.4 代码讲解
当涉及到AI作画算法时,主要的方法包括生成对抗网络(GANs)、变分自编码器(VAEs)、神经风格迁移(Neural Style Transfer)等。下面我将详细介绍每个组成部分的原理,并给出数学公式和代码讲解。

1. 生成对抗网络(GANs)
生成对抗网络由两个主要组件组成:生成器(Generator)和判别器(Discriminator)
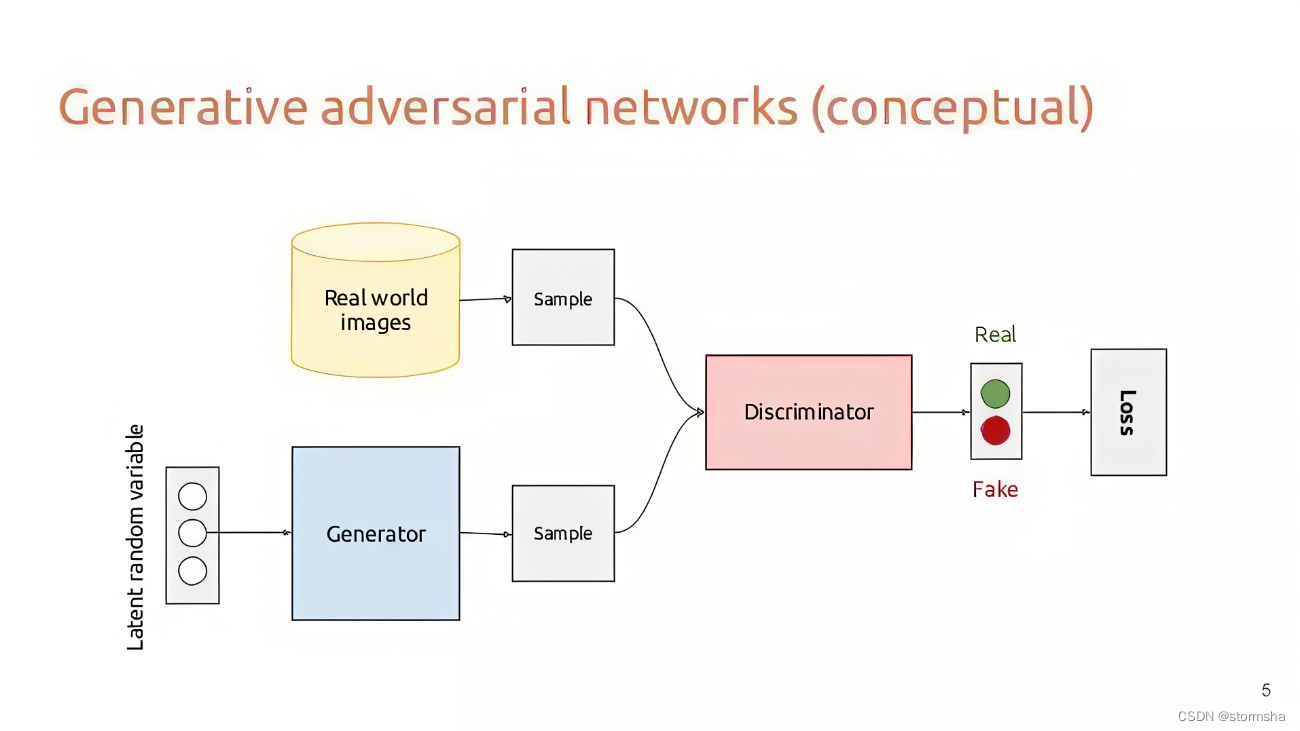
1.1 生成器(Generator)
生成器旨在从随机噪声中生成逼真的图像。它通常是一个深度卷积神经网络,其目标是最小化生成的图像与真实图像之间的差距。
在数学上,生成器可以表示为:
G : z → x G:z\to x G:z→x
其中,( z ) 是输入的随机噪声向量,( x ) 是生成的图像。
1.2 判别器(Discriminator)
判别器旨在区分生成器生成的假图像和真实图像。它也是一个深度卷积神经网络,其目标是最大化正确分类真实图像和生成的图像的概率。
在数学上,判别器可以表示为:
D : x → [ 0 , 1 ] D:x\to[0,1] D:x→[0,1]
其中, D ( x ) D(x) D(x) 表示输入图像 x x x 是真实图像的概率。
1.3 对抗训练
生成器和判别器通过对抗训练相互竞争。生成器试图最小化判别器的损失,而判别器试图最大化将真实图像与生成的图像正确分类的概率。他们的损失函数可以定义如下:
生成器的损失函数:
L G A N = − log ( D ( G ( z ) ) ) \mathcal{L}_\mathrm{GAN}=-\log(D(G(z))) LGAN=−log(D(G(z)))
判别器的损失函数:
L G A N = − log ( D ( x ) ) − log ( 1 − D ( G ( z ) ) ) \mathcal{L}_{\mathrm{GAN}}=-\log(D(x))-\log(1-D(G(z))) LGAN=−log(D(x))−log(1−D(G(z)))
这样的对抗训练会持续进行,直到生成器生成的图像与真实图像难以区分为止。
1.4 代码讲解
以下是一个简化的生成器和判别器的PyTorch代码示例:
import torch
import torch.nn as nn# Generator
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.model = nn.Sequential(nn.Linear(noise_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, output_dim),nn.Tanh())def forward(self, z):return self.model(z)# Discriminator
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1),nn.Sigmoid())def forward(self, x):return self.model(x)
2. 变分自编码器(VAEs)
变分自编码器是一种生成模型,通过学习数据的潜在分布来生成新的数据样本。
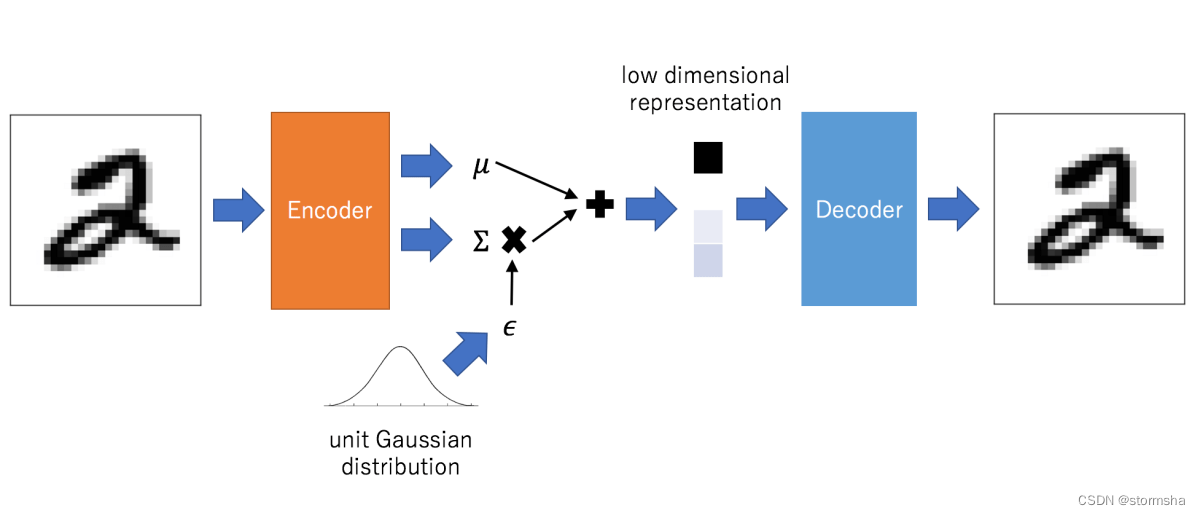
2.1 编码器(Encoder)
编码器将输入图像编码为潜在空间中的潜在表示。它学习将图像映射到潜在空间中的均值和方差。
在数学上,编码器可以表示为:
q ( z ∣ x ) = N ( μ ( x ) , σ 2 ( x ) ) q(z|x)=\mathcal{N}(\mu(x),\sigma^2(x)) q(z∣x)=N(μ(x),σ2(x))
其中, μ ( x ) \mu(x) μ(x) 和 σ 2 ( x ) \sigma^2(x) σ2(x) 是图像 x x x 的均值和方差。
2.2 解码器(Decoder)
解码器将潜在表示解码为图像。它学习将潜在空间中的点映射回图像空间。
在数学上,解码器可以表示为:
p ( x ∣ z ) = N ( f ( z ) , σ 2 I ) p(x|z)=\mathcal{N}(f(z),\sigma^2I) p(x∣z)=N(f(z),σ2I)
其中, f ( z ) f(z) f(z) 是潜在表示 z z z 的解码结果, σ 2 I \sigma^2 I σ2I 是噪声。
2.3 损失函数
VAEs使用重构损失和KL散度来训练模型。
重构损失:
L recon = − E q ( z ∣ x ) [ log p ( x ∣ z ) ] \mathcal{L}_{\text{recon}} = -\mathbb{E}_{q(z|x)}[\log p(x|z)] Lrecon=−Eq(z∣x)[logp(x∣z)]
KL散度:
L KL = KL ( q ( z ∣ x ) ∣ ∣ p ( z ) ) \mathcal{L}_{\text{KL}} = \text{KL}(q(z|x)||p(z)) LKL=KL(q(z∣x)∣∣p(z))
总损失:
L VAE = L recon + L KL \mathcal{L}_{\text{VAE}} = \mathcal{L}_{\text{recon}} + \mathcal{L}_{\text{KL}} LVAE=Lrecon+LKL
2.4 代码讲解
以下是一个简化的VAE的PyTorch代码示例:
import torch
import torch.nn as nn# Encoder
class Encoder(nn.Module):def __init__(self, input_dim, hidden_dim, latent_dim):super(Encoder, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.fc2_mean = nn.Linear(hidden_dim, latent_dim)self.fc2_logvar = nn.Linear(hidden_dim, latent_dim)def forward(self, x):h = torch.relu(self.fc1(x))return self.fc2_mean(h), self.fc2_logvar(h)# Decoder
class Decoder(nn.Module):def __init__(self, latent_dim, hidden_dim, output_dim):super(Decoder, self).__init__()self.fc1 = nn.Linear(latent_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, output_dim)def forward(self, z):h = torch.relu(self.fc1(z))return torch.sigmoid(self.fc2(h))# VAE
class VAE(nn.Module):def __init__(self, encoder, decoder):super(VAE, self).__init__()self.encoder = encoderself.decoder = decoderdef reparameterize(self, mu, logvar):std = torch.exp(0.5*logvar)eps = torch.randn_like(std)return mu + eps * stddef forward(self, x):mu, logvar = self.encoder(x)z = self.reparameterize(mu, logvar)recon_x = self.decoder(z)return recon_x, mu, logvardef reconstruct(self, x):recon_x, _, _ = self.forward(x)return recon_x
❤️❤️❤️本人水平有限,如有纰漏,欢迎各位大佬评论批评指正!😄😄😄
💘💘💘如果觉得这篇文对你有帮助的话,也请给个点赞、收藏、分享下吧,非常感谢!👍 👍 👍
🔥🔥🔥道阻且长,行则将至,让我们一起加油吧!🌙🌙🌙
| 💖The End💖点点关注,收藏不迷路💖 |