[pdf | proj | code]

- 提出GPAvatar,实现可驱动的单图虚拟头像重建(Head avatar reconstruction)。
- 重建:给定图像得到对应Tri-plane。在此基础上,本文提出了MTA,可以融合多张图片输入信息,缓解单张图片中存在遮挡的问题。
- 驱动:受Point-Avatar启发,给每个FLAME绑定一个特征,对于任意点,检索其K个最近邻FLAME三角面片,根据K个三角面片绑定特征的加权和计算该点的表情特征。
- 从实验效果上看,对跨域人像效果不错
近期工作
- 基于2D变形(2D-based warping):通过稀疏关键点计算变形场,将原图片变形至新表情,通过编解码器生成外观。但是由于缺乏3D约束,这类方法的多视角一致性较差,尤其是当头部姿态变化较大时。
- 基于网格(mesh-based):例如3DMM,但是3DMM对几何纹理的建模能力较较差,无法建模非面部信息(头发),表情也不是很自然。
- 基于神经渲染(neural rendering):相较于前两类方法,在3D一致性和非面部信息建模上表现出色,但是部分方法需要大量人像数据用于重建,并且存在很耗时的推理阶段。
本文提出了GPAvatar,实现给定一张或多张图片,在单次推理中重建可驱动人像。主要挑战包括:保ID重建和准确表情控制。
- 针对第一个挑战,GPAvatar提出Multi Tri-planes Attention (MTA) 模块,在规范场中融合多张输入图片的信息;
- 针对第二个挑战,GPAvatar提出dynamic Point-based Expression Field(PEF):通过点云驱动,准确有效地捕捉表情;
方法
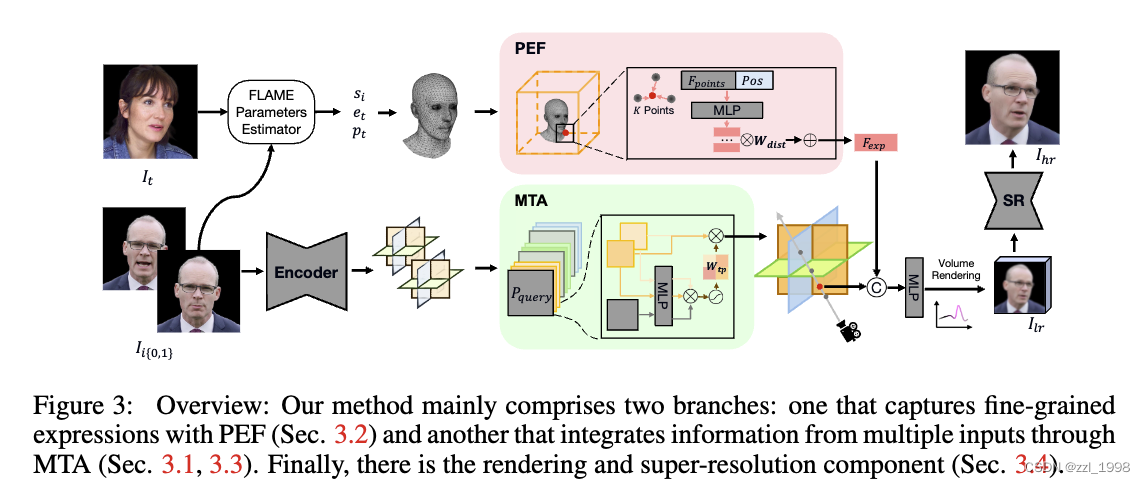
GPAvatar的整体过程可以概括如下:
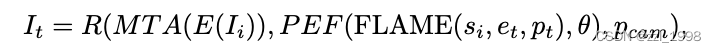
- 输入变量包括:输入图片I_i,对应的形状系数s_i,驱动表情e_t和位姿p_t,生成的驱动图片I_t;
- 映射函数包括:E(输入图片 -> 规范特征空间),PEF(FLAME模型和绑定特征theta -> 几何特征)R(体渲染),MTA(多张输入图片 -> 规范特征空间)。
规范特征编码器(Canonical Feature Encoder)
- 使用GDPGAN,将对齐人脸输入图像映射为Tri-planes;
基于点的表情场(Point-based Expression Field)
- FLAME模型中每个三角面片绑定一个可学习特征。给定任意3D点x,检索其K个最近邻FLAME三角面片,根据K个三角面片绑定特征的加权和计算该3D点的表情特征f_exp,加权系数与3D点和面片距离成反比,具体计算如下:
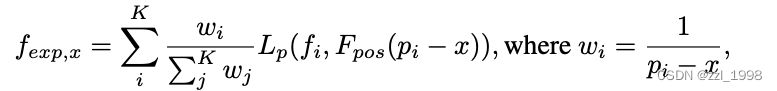
- 其中,pi是第i个三角面片位置,f_i是对应的绑定特征,L_p是可学习的线性层,F_pos是位置编码函数。
Multi Tri-planes Attention
- 输入图片可能有多张,通过规范特征编码器得到多个Tri-planes。额外增加一个可学习的query tri-planes,提供权重融合多个Tri-planes,具体计算如下:
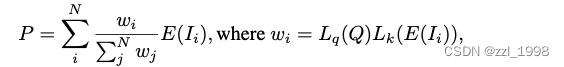
- 其中,Q是query tri-planes,L_q和L_k是可学习的线性层。
体渲染和超分
- 渲染图像为128 x 128,通过超分模块得到高质量渲染,超分模块也是端到端训练的。
训练策略和损失函数
- 包括重建损失和正则损失,其中重建损失为高低分辨率的L1损失和perceptual损失;正则损失为NeRF密度损失,希望密度尽可能小。具体如下
![]()
![]()
![]()
实验
- 数据集:VFHQ数据集,包含8013个视频切片,提取240,390帧用于训练。训练中,随机从同一ID视频中采样两帧,一帧用于驱动,另一帧用作源图像。同时,每轮训练有70%概率输入两张图片,30%概率输入一张图片。使用VFHQ和HDTF数据集测试。
- Evaluation Metrics:同ID和跨ID重演。
- 跨ID重演:用基于ArcFace的ID编码的余弦相似度(cosine similarity of identity embeddings,CSIM)来评价ID一致性,以及平均表情距离(Average Expression Distance,AED)和平均姿态距离(Average Pose Distance,APD)评估表情和姿态驱动;
- 同ID重演:PSNR、SSIM、L1、LPIPS和平均关键点距离(Average Key-point Distance,AKD)
- 基线方法:StyleHeat、ROME、OTAvatar、Next3D、HideNeRF
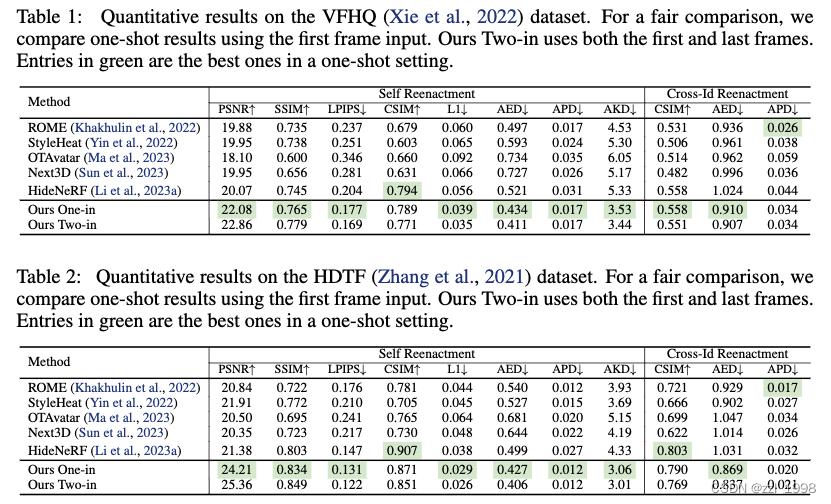
同ID重演

跨ID重演

多图片输入
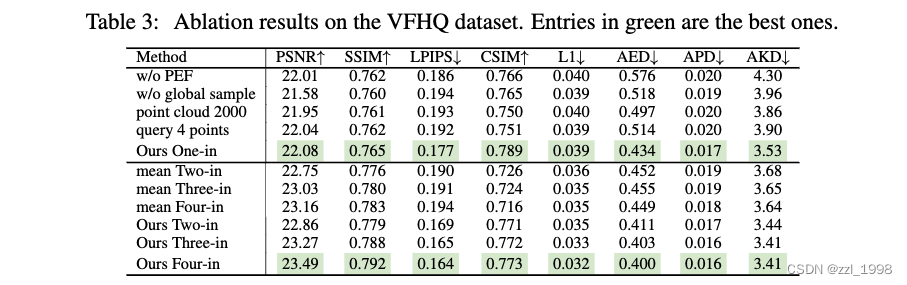
 消融实验
消融实验