实验1:求TOP值
已知存在两个文本文件,file1.txt和file2.txt,内容分别如下:
file1.txt
1,1768,50,155
2,1218, 600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
file2.txt
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116
以上两个文件所存储的数据字段的意义为:orderid, userid, payment, productid
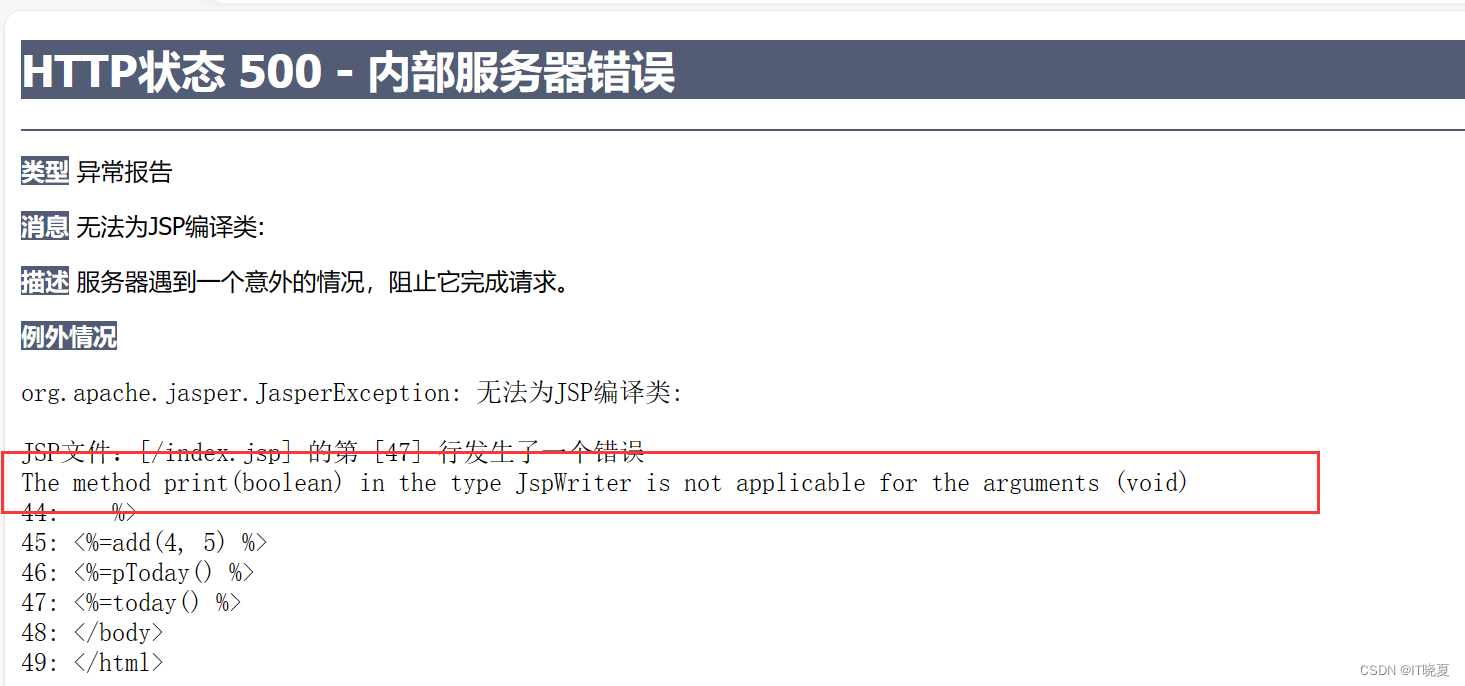
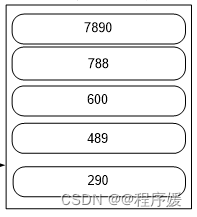
请使用Spark编程计算求Top N个payment值,N值取5,结果如下:
实验步骤
将文件上传HDFS
创建example文件夹
hadoop fs -mkdir hdfs://ly1:9000/example注:在file1.txt file2.txt 所在的文件夹下上传,或者输入绝对路径
hadoop fs -put file* hdfs://ly1:9000/example安装sbt
在/bigdata目录下新建sbt目录
mkdir /bigdata/sbtDownload | sbt (scala-sbt.org)
下载sbt-1.9.9.tgz
xftp上传到虚拟机
解压
tar -zxvf sbt-1.9.9.tgz -C /bigdata/sbt接着在安装目录中使用下面命令创建一个Shell脚本文件,用于启动sbt:
vim /usr/local/sbt/sbt#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"保存后,为该Shell脚本文件增加可执行权限:
chmod u+x /usr/local/sbt/sbt使用如下命令查看sbt版本信息
sbtVersion 出现以下信息则表示安装成功

创建项目文件夹
在bigdata目录下创建sparkapp文件夹,这是应用程序根目录
mkdir /bigdata/sparkapp创建所需的文件夹结构
mkdir -p ./sparkapp/src/main/scalaScala文件
建立一个名为TopN.scala的文件,写入以下内容
//TopN.scala
import org.apache.spark.{SparkConf, SparkContext}
object TopN {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("TopN").setMaster("local")val sc = new SparkContext(conf)sc.setLogLevel("ERROR")val lines = sc.textFile("hdfs:/xxx/:9000/examples",2)//修改为自己的节点HDFS地址var num = 0;val result = lines.filter(line => (line.trim().length > 0) && (line.split(",").length == 4)).map(_.split(",")(2)).map(x => (x.toInt,"")).sortByKey(false).map(x => x._1).take(5).foreach(x => {num = num + 1println(num + "\t" + x)})}
}TopN.sbt
在程序根目录下新建TopN.sbt文件并添加以下信息
name ="TopN"
version :"1.0"
scalaVersion :="2.12.12"
libraryDependencies +"org.apache.spark"%%"spark-core"%"3.0.0"
spark为3.0版本,所以scala的版本要2.12及以上 ,spark-core的版本是spark的版本
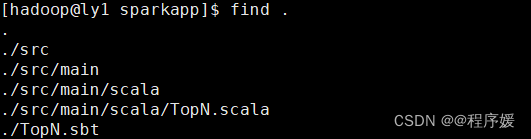
find .检查项目结构
打包
/bigdata/sbt/sbt package
运行
/bigdata/spark/bin/spark-submit --class "TopN" /bigdata/sparkapp/target/scala-2.12/topn_2.12-1.0.jar