/*
Why Spark一、MapReduce编程模型的局限性1、繁杂:只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码2、处理效率低:2.1、Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据2.2、任务调度与启动开销大3、不适合迭代处理、交互式处理和流式处理二、Spark是类Hadoop MapReduce的通用【并行】框架1、Job中间输出结果可以保存在内存,不再需要读写HDFS2、比MapReduce平均快10倍以上三、版本2014 1.02016 2.x2020 3.x四、优势1、速度快基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)基于硬盘数据处理,比MR快10个数量级以上2、易用性支持Java、【Scala】、【Python:pyspark】、R语言交互式shell方便开发测试3、通用性一栈式解决方案:批处理交互式查询实时流处理(微批处理)图计算机器学习4、多种运行模式YARN ✔、Mesos、EC2、Kubernetes、Standalone、Local[*]五、技术栈1、Spark Core:核心组件,分布式计算引擎 RDD2、Spark SQL:高性能的基于Hadoop的SQL解决方案3、Spark Streaming:可以实现高吞吐量、具备容错机制的准实时流处理系统4、Spark GraphX:分布式图处理框架5、Spark MLlib:构建在Spark上的分布式机器学习库六、spark-shell:Spark自带的交互式工具local:spark-shell --master local[*]alone:spark-shell --master spark://MASTERHOST:7077yarn :spark-shell --master yarn
*/cd /opt/software/spark-3.1.2/sbin
./start-all.sh
spark-shell --master local
-------------------------------------------------
sc.textFile("file:///root/spark/wordcount.log").flatMap(line=>line.split("\\s+")).map(word=>(word,1)).reduceByKey(_+_).collect
-------------------------------------------------
res1: Array[(String, Int)] = Array((hello,2), (welcome,2), (world,1))
-------------------------------------------------/*七、运行架构1、在驱动程序中,通过SparkContext主导应用的执行2、SparkContext可以连接不同类型的 CM(Standalone、YARN),连接后,获得节点上的 Executor3、一个节点默认一个Executor,可通过 SPARK_WORKER_INSTANCES 调整4、每个应用获取自己的Executor5、每个Task处理一个RDD分区Spark服务Master : Cluster ManagerWorker : Worker Node
*//*八、Spark架构核心组件Application 建立在Spark上的用户程序,包括Driver代码和运行在集群各节点Executor中的代码Driver program 驱动程序。Application中的main函数并创建SparkContextCluster Manager 在集群(Standalone、Mesos、YARN)上获取资源的外部服务Worker Node 集群中任何可以运行Application代码的节点Executor 某个Application运行在worker节点上的一个进程Task 被送到某个Executor上的工作单元Job 多个Task组成的并行计算,由Action触发生成,一个Application中含多个JobStage 每个Job会被拆分成多组Task,作为一个TaskSet,其名称为Stage
*/SparkContext
/*连接Driver与Spark Cluster(Workers)Spark的主入口每个JVM仅能有一个活跃的SparkContext
*//*
【配置】master:local[*] : CPU核数为当前环境的最大值local[2] : CPU核数为2local : CPU核数为1yarn
*/
val conf:SparkConf = new SparkConf().setAppName(name:String).set(key:String,value:String) // 多项设置.setMaster(master:String)
val sc: SparkContext = SparkContext.getOrCreate(conf)/**封装:工具类
*/
class SparkCom(appName:String,master:String,logLevel:String="INFO") {private val conf:SparkConf = new SparkConf().setAppName(appName).setMaster(master)private var _sc:SparkContext = _private var _spark:SparkSession = _def sc() = {if (Objects.isNull(_sc)) {_sc = new SparkContext(conf)_sc.setLogLevel(logLevel)}_sc}def spark() = {if (Objects.isNull(_spark)) {_spark = SparkSession.builder().config(conf).getOrCreate()}_spark}def stop() = {if (Objects.nonNull(_sc)) {_sc.stop()}if (Objects.nonNull(_spark)) {_spark.stop()}}
}
object SparkCom{def apply(appName:String): SparkCom = new SparkCom(appName,"local[*]")def apply(appName:String, master:String): SparkCom = new SparkCom(appName,master)def apply(appName:String, master:String, logLevel:String): SparkCom = new SparkCom(appName,master,logLevel)
}/*
RDD[?]
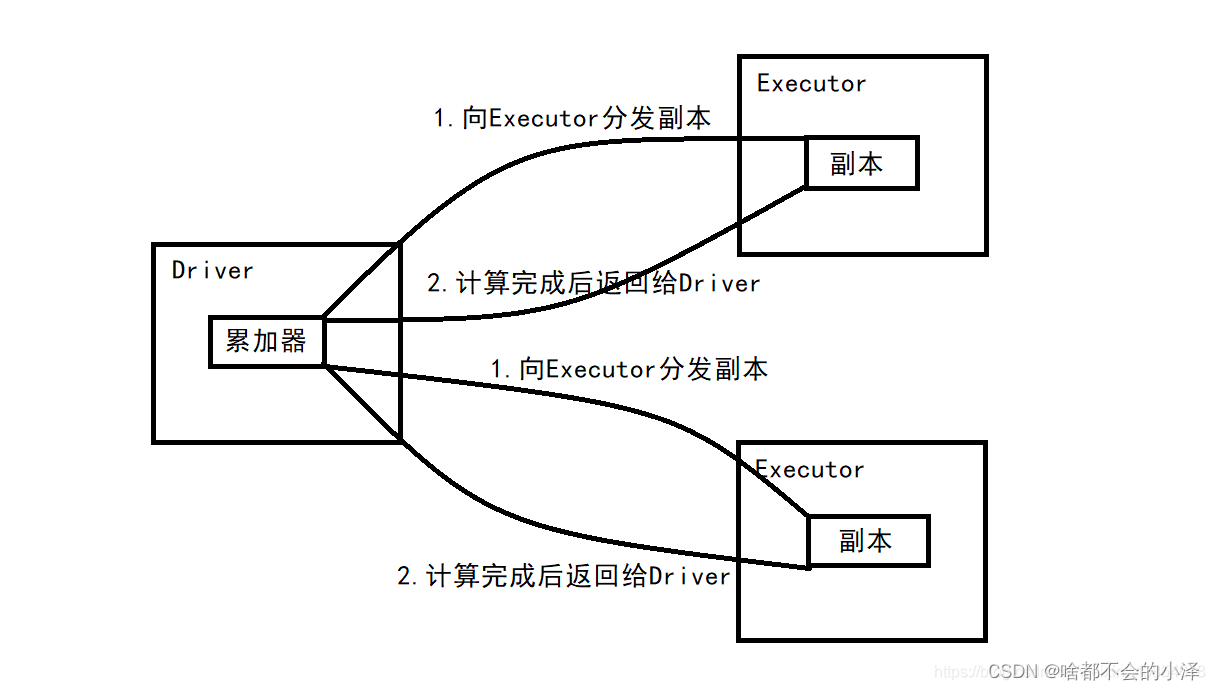
【数据集创建】RDD:Spark核心,主要数据抽象将数据项拆分为多个分区的集合,存储在集群的工作节点上的内存和磁盘RDD是用于数据转换的接口RDD指向了或存储在(HIVE)HDFS、Cassandra、HBase等或缓存(内存、内存+磁盘、仅磁盘等)或在故障或缓存收回时重新计算其他RDD分区中的数据RDD:是弹性分布式数据集(Resilient Distributed Datasets)分布式数据集RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上RDD并不存储真正的数据,只是【对数据和操作】的描述弹性RDD默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘容错性根据数据血统,可以自动从节点失败中恢复分区RDD与DAG:Stage两者是Spark提供的核心抽象DAG【有向无环图:如下图】反映了RDD之间的依赖关系 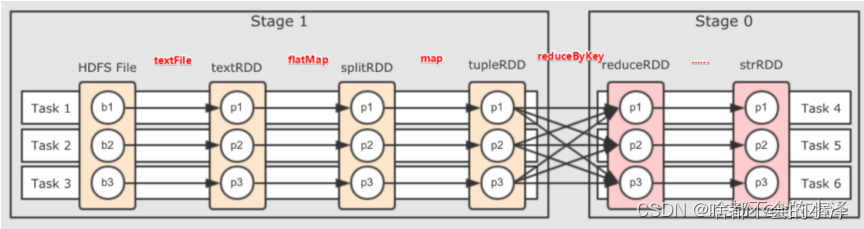
/*RDD的特性一系列的分区(分片)信息,每个任务处理一个分区每个分区上都有compute函数,计算该分区中的数据RDD之间有一系列的依赖分区器决定数据(key-value)分配至哪个分区优先位置列表,将计算任务分派到其所在处理数据块的存储位置RDD分区:Partition -> Partitioner -> Hash | Range ... 分区是RDD被拆分并发送到节点的不同块之一我们拥有的分区越多,得到的并行性就越强每个分区都是被分发到不同Worker Node的候选者每个分区对应一个TaskRDD操作类型:分为lazy与non-lazy两种Transformation(lazy):也称转换操作、转换算子Actions(non-lazy):立即执行,也称动作操作、动作算子
*/
// 集合创建:小数据集,可通过 numSlices 指定并行度(分区数)
val rdd: RDD[T] = sc.parallelize(seq:Seq[T], numSlices:Int) // ✔
val rdd: RDD[T] = sc.makeRDD(seq:Seq[T], numSlices:Int) // 调用了 parallelize// 外部数据源创建: 可通过 minPartitions 指定分区数,CPU核占用数
// 文件系统:local(file:///...)或hadoop(hdfs://)
val rdd: RDD[String] = sc.textFile(path:String, minPartitions:Int)
val rdd: RDD[String] = sc.wholeTextFiles(dir:String, minPartitions:Int)// 其他 RDD 创建
val rdd2: RDD[Map[String, Int]] = rdd.mapPartitions(_.map(_.split("[^a-zA-Z]+").map((_, 1)).groupBy(_._1).map(t2 => (t2._1, t2._2.length))))转换算子:RDD transform
/*简单类型 RDD[T]
*/// 【逐条处理】
val rdd2: RDD[U] = rdd.map(f:T=>U)
// 【扁平化处理】:TraversableOnce : Trait用于遍历和处理集合类型元素,类似于java:Iterable
val rdd2: RDD[U] = rdd.flatMap(f:T=>TraversableOnce[U])
/* 【分区内逐行处理】:以分区为单位(分区不变)逐行处理数据 ✔map VS mapPartitions1、数量:前者一进一出IO数量一致,后者多进多出IO数量不一定一致2、性能:前者多分区逐条处理,后者各分区并行逐条处理更佳,常时间占用内存易导致OOM,内存小不推荐
*/
val rdd2: RDD[U] = rdd.mapPartitions(f:Iterator[T]=>Iterator[U][,preservePar:Boolean])
// 【分区内逐行处理】:以分区为单位(分区不变)逐行处理数据,并追加分区编号
val rdd2: RDD[U] = rdd.mapPartitionsWithIndex(f:(Int,Iterator[T])=>Iterator[U][,preservePar:Boolean])
// 【转内存数组】:同分区的数据转为同类型的内存数组,分区不变
val rdd2: RDD[Array[T]] = rdd.glom();
// 【数据分组】:同键同组同区,同区可多组;打乱shuffle,按f:T=>K规则,分区不变,【数据可能倾斜skew】
val rdd2: RDD[(K,Iterable[T])] = rdd.groupBy(f:T=>K)
// 【数据过滤】:过滤规则 f:T=>Boolean,保留满足条件数据,分区不变,【数据可能倾斜skew】
val rdd2: RDD[T] = rdd.filter(f:T=>Boolean)
/* 【数据抽样】withReplacement:Boolean 是否有放回抽样fraction:Double 抽样率seed:Long 随机种子,默认为当前时间戳(一般缺省)若数据总理为100条false, 0.4 => 抽样40%的数据,40条左右true, 0.4 => 每条数据被抽取的概率为40%
*/
val rdd2: RDD[T] = rdd.sample(withReplacement:Boolean,fraction:Double,seed:Long)
// 【数据去重】:numPartitions:Int 设定去重后的分区数
val rdd2: RDD[T] = rdd.distinct([numPartitions:Int])(implicit order:Ording[T] = null)
/* 【数据排序】处理数据f:T=>K,升降序asc:Boolean,分区数numPartitions:Int默认排序前后分区一致,【有shuffle】,除非重新设定 numPartitions
*/
val rdd2: RDD[T] = rdd.sortBy(f:T=>K,asc:Boolean,numPartitions:Int)/*多个类型 RDD[T]:纵向交并差操作:数据类型一致,根据元素 equals 认定是否相同拉链操作:要求分区数和分区内的数据量一致
*/
// 【求交集】:重载可重设分区数numPartitions:Int,或定义分区规则par:Partitioner[T]
val rdd2: RDD[T] = rdd.intersection(rdd3:RDD[T])
val rdd2: RDD[T] = rdd.intersection(rdd3:RDD[T], numPartitions:Int)
val rdd2: RDD[T] = rdd.intersection(rdd3:RDD[T], par:Partitioner[T])
// 【求并集】
val rdd2: RDD[T] = rdd.union(rdd3:RDD[T])
// 【求差集】:重载可重设分区数numPartitions:Int,或定义分区规则par:Partitioner[T]
val rdd2: RDD[T] = rdd.subtract(rdd3:RDD[T])
val rdd2: RDD[T] = rdd.subtract(rdd3:RDD[T], numPartitions:Int)
val rdd2: RDD[T] = rdd.subtract(rdd3:RDD[T], par:Partitioner[T])
// 【拉链操作】
val rdd2: RDD[(T,U)] = rdd.zip(rdd3:RDD[U])
val rdd2: RDD[(T,Long)] = rdd.zipWithIndex()
val rdd2: RDD[(T,Long)] = rdd.zipWithUniqueId()
// 有三个重载:1+1,1+2,1+3
val rdd2: RDD[V]rdd.zipPartitions(rddA:RDD[A])(f:(Iterator[T],Iterator[A])=>Iterator[V])
val rdd2: RDD[V]rdd.zipPartitions(rddA:RDD[A],preserveParitioning:Boolean)(f:(Iterator[T],Iterator[A])=>Iterator[V])键值算子:PairRDD(K,V)
/*【再分区操作】abstract class Partitioner(){// 分区总数def numPartitions : scala.Int// 针对键的值进行相关的计算等到分区号def getPartition(key : scala.Any) : scala.Int}// 自定义分区器class KVPartitioner(np:Int) extends Partitioner{override def numPartitions: Int = npoverride def getPartition(key: Any): Int = key.toString.length%numPartitions}// 若在分区器和现有分区器相同,则不执行分区操作org.apache.spark.PartitionerHashPartitioner*/
val pairRdd2: RDD[(K,V)] = pairRdd.partitionBy(p:Partitioner)
// 【按键排序】:K 必须实现 Ordered 特质
val pairRdd2: RDD[(K,V)] = pairRdd.sortByKey(ascending:Boolean=true, numPartitions:Int)// reduceByKey + foldByKey + aggregateByKey 都调用 combineByKeyClassTag
// 【按键聚合值】: combiner和reduce的值类型相同,计算规则相同
val pairRdd2:RDD[(K,V)] = pairRdd.reduceByKey(f:(V,V)=>V)
val pairRdd2:RDD[(K,V)] = pairRdd.reduceByKey(f:(V,V)=>V, numPartitions:Int)
val pairRdd2:RDD[(K,V)] = pairRdd.reduceByKey(partitioner:Partitioner, f:(V,V)=>V)
// 【按键聚合值】: combiner和reduce的值类型相同,计算规则相同,带初值
val pairRdd2:RDD[(K,V)] = pairRdd.foldByKey(initV:V)(inParOp:(V,V)=>V)
val pairRdd2:RDD[(K,V)] = pairRdd.foldByKey(initV:V,numPartitions:Int)(inParOp:(V,V)=>V)
val pairRdd2:RDD[(K,V)] = pairRdd.foldByKey(initV:V,partitioner:Partitioner)(inParOp:(V,V)=>V)
// 【按键分别执行分区内和分区间计算】: combiner和reduce的值类型可不同,计算规则可不同
val pairRdd2:RDD[(K,U)] = pairRdd.aggregateByKey(initV:U)(inParOp:(U,V)=>U,betParOp:(U,U)=>U)
val pairRdd2:RDD[(K,U)] = pairRdd.aggregateByKey(initV:U,numPartitions:Int)(inParOp:(U,V)=>U,betParOp:(U,U)=>U)
val pairRdd2:RDD[(K,U)] = pairRdd.aggregateByKey(initV:U,partitioner:Partitioner)(inParOp:(U,V)=>U,betParOp:(U,U)=>U)
// 【✔ 按键分别执行分区内和分区间计算】: combiner和reduce的值类型可不同,计算规则可不同
val pairRdd2:RDD[(K,U)] = pairRdd.combineByKey(initV:V=>U,inParOp:(U,V)=>U,betParOp:(U,U)=>U)
val pairRdd2:RDD[(K,U)] = pairRdd.combineByKey(initV:V=>U,inParOp:(U,V)=>U,betParOp:(U,U)=>U,numPartitions:Int)
val pairRdd2:RDD[(K,U)] = pairRdd.combineByKey(initV:V=>U,inParOp:(U,V)=>U,betParOp:(U,U)=>U,partitioner:Partitioner,mapSideCombine:Boolean,serializer:Serializer)
// 【按键分组】
val pairRdd2: RDD[(K, Iterable[V])] = pairRdd.groupByKey()
val pairRdd2: RDD[(K, Iterable[V])] = pairRdd.groupByKey(numPartitions:Int)
val pairRdd2: RDD[(K, Iterable[V])] = pairRdd.groupByKey(partitioner:Partitioner)// 【多数据集分组】:1VN 同键同组,不同RDD值进入TupleN的不同Iterable
-------------------------------------------------------------------------------
val pairRdd2: RDD[(K, (Iterable[V],Iterable[V1])] = pairRdd.groupWith(otherA: RDD[(K,V1)])
val pairRdd2: RDD[(K, (Iterable[V],Iterable[V1],Iterable[V2])] = pairRdd.groupWith(otherA: RDD[(K,V1)],otherB: RDD[(K,V2)])
val pairRdd2: RDD[(K, (Iterable[V],Iterable[V1],Iterable[V2],Iterable[V3])] = pairRdd.groupWith(otherA: RDD[(K,V1)],otherB: RDD[(K,V2)],otherC: RDD[(K,V3)])
-------------------------------------------------------------------------------
// 重载 1+1 1+2 1+3,追加再分区操作
val pairRdd2: RDD[(K, (Iterable[V],Iterable[V1])] = pairRdd.cogroup(otherA: RDD[(K,V1)])
val pairRdd2: RDD[(K, (Iterable[V],Iterable[V1])] = pairRdd.cogroup(otherA: RDD[(K,V1)],numPartitions:Int)
val pairRdd2: RDD[(K, (Iterable[V],Iterable[V1])] = pairRdd.cogroup(otherA: RDD[(K,V1)],partitioner:Partitioner)
/*【关联操作】:1V1 Shuffle ?横向,根据键做关联重载:numPartitions:Int 或 partitioner:Partitioner
*/
val pairRdd: RDD[(K, (V, V1))] = pairRdd1.join(pairRdd3:RDD[(K,V1)])
val pairRdd: RDD[(K, (V, Option[V1]))] = pairRdd1.leftOuterJoin(pairRdd3:RDD[(K,V1)])
val pairRdd: RDD[(K, (Option[V]), V1)] = pairRdd1.rightOuterJoin(pairRdd3:RDD[(K,V1)])
val pairRdd: RDD[(K, (Option[V]), Option[V1])] = pairRdd1.fullOuterJoin(pairRdd3:RDD[(K,V1)])行动算子:action
/* 【返回】所有元素分别在分区间和分区内执行【聚集】操作的结果reduce & fold 分区内和分区间执行相同操作,且类型与元素类型一致aggregate 分区内和分区间执行不同操作,且类型与元素类型不一致
*/
val rst:T = rdd.reduce(f:(T,T)=>T)
val rst:T = rdd.fold(init:T)(f:(T,T)=>T)
val rst:U = rdd.aggregate(init:U)(f:(U,T)=>U,f:(U,T)=>U)
// 返回包含数据集中所有元素的数组
val array:Array[T] = rdd.collect()
// 返回数据集中元素数量
val rst:Long = rdd.count()
val rst:Map[K,Long] = pairRdd.countByKey()
// 返回数据集中最大值
val rst:T = rdd.max()
// 返回数据集中最小值
val rst:T = rdd.min()
// 返回数据集中的第一个元素
val rst:T = rdd.first()
// 返回数据集中的前 num 个元素
val array:Array[T] = rdd.take(num:Int)
// 返回排序后数据集中的前 num 个元素
val array:Array[T] = rdd.takeOrdered(num:Int)(implicit ord:Ordering[T])
/* 持久化至文本文件,重载追加压缩功能import org.apache.hadoop.io.compress.{BZip2Codec, SnappyCodec}import io.airlift.compress.lzo.LzopCodecrdd.saveAsTextFile("out_path",classOf[BZip2Codec])
*/
rdd.saveAsTextFile(path:String)
rdd.saveAsTextFile(path:String,codec: Class[_ <: CompressionCodec])
rdd.saveAsObjectFile(path:String)
// 遍历迭代
rdd.foreach(f:T=>Unit)练习
/*现有客户信息文件 customers.csv,请找出:客户中的前5个最大家族客户中的前10个最流行的名字
*//*现有客户信息文件 scores.txt,请找出:班级 ID 姓名 年龄 性别 科目 成绩需求如下:1. 一共有多少人参加考试?1.1 一共有多少个小于 20 岁的人参加考试?1.2 一共有多少个等于 20 岁的人参加考试?1.3 一共有多少个大于 20 岁的人参加考试?2. 一共有多个男生参加考试?2.1 一共有多少个女生参加考试?3. 12 班有多少人参加考试?3.1 13 班有多少人参加考试?4. 语文科目的平均成绩是多少?4.1 数学科目的平均成绩是多少?4.2 英语科目的平均成绩是多少?5. 单个人平均成绩是多少?6. 12 班平均成绩是多少?6.1 12 班男生平均总成绩是多少?6.2 12 班女生平均总成绩是多少?6.3 同理求 13 班相关成绩7. 全校语文成绩最高分是多少?7.1 12 班语文成绩最低分是多少?7.2 13 班数学最高成绩是多少?8. 总成绩大于 150 分的 12 班的女生有几个?
*/// 样例类参与 RDD 运算不能写在 main 中,否则报错:序列化异常
case class Score(classId:Int, name:String, age:Int, gender:String, subject:String, score:Int ) extends Serializable {def claSub = s"$classId,$subject"
}val regex:Regex = "(\\d+)\\s+(.*?)\\s+(.*?)\\s+(.*?)\\s+(.*?)\\s+(.*?)".r
implicit def strToScore(line:String)={line match {case regex(classId,name,age,gender,subject,score)=>Score(classId.toInt,name,age.toInt,gender,subject,score.toInt)}
}val scores: RDD[Score] = sc.textFile("hdfs://single:9000/spark/cha01/scores.txt", 4)
.mapPartitionsWithIndex((ix,it) => {if(ix==0){it.drop(1)}it.map(line=>{val score:Score = linescore})}
).cache()val num20s: RDD[(String, Int)] = scores.mapPartitions(_.map(score => (if (score.age < 20) "SCORE_LT_20" else if (score.age == 20) "SCORE_EQ_20" else "SCORE_GT_20", 1))).reduceByKey(_ + _)val numClass: RDD[(Int, Int)] = scores.mapPartitions(_.map(score => (score.classId, 1))).reduceByKey(_ + _)val numGender: RDD[(String, Int)] = scores.mapPartitions(_.map(score => (score.gender, 1))).reduceByKey(_ + _)val avgScoreBySubject: RDD[(String, Float)] = scores.mapPartitions(_.map(score => (score.subject, score.score))).groupByKey().mapPartitions(_.map(t => (t._1, t._2.sum * 1.0f / t._2.size)))val avgScoreByName: RDD[(String, Float)] = scores.mapPartitions(_.map(score => (score.name, score.score))).groupByKey().mapPartitions(_.map(t => (t._1, t._2.sum * 1.0f / t._2.size)))val avgScoreByClassGender: RDD[((Int, String), Float)] = scores.mapPartitions(_.map(score => ((score.classId, score.gender), score.score))).groupByKey().mapPartitions(_.map(t => (t._1, t._2.sum * 1.0f / t._2.size)))val maxChinese: Int = scores.filter(_.subject.equals("chinese")).map(_.score).max()
val min12Chinese: Int= scores.filter(_.claSub.equals("12,chinese")).map(_.score).min()
val max13Math: Int = scores.filter(_.claSub.equals("13,math")).map(_.score).max()val numSumScore12Gt150: Long = scores.filter(score => score.classId == 12 && score.gender.equals("女")).mapPartitions(_.map(score => (score.name, score.score))).reduceByKey(_+_).filter(_._2 > 150).count()优化:optimize
org.apache.spark.util.Utils/*shuffle性能较差:因为shuffle必须落盘,内存中等数据会OOMgroupByKey只分组(存在Shuffle) + reduce只聚合<=结果同,性能不同=>reduceByKey先分组、预聚合、再聚合(存在Shuffle) ✔
*//*
【设置日志管理】日志级别:INFO|DEGUG|WARN|ERROR|FATAL
*/
sc.setLogLevel(logLevel:String)/*
【设置检查点:容错,恢复】
*/
sc.setCheckpointDir(path:String)/*
【RDD重用:检查点、缓存与持久化】cache 临时存储于【内存】重用,job结束后自动删除 ✔<=> persist(StorageLevel.MEMORY_ONLY)persisit 临时存储于【磁盘】重用,job结束后自动删除,涉及IO性能较差StorageLevel.MEMORY_ONLYStorageLevel.DISK_ONLYStorageLevel.OFF_HEAPStorageLevel.MEMORY_AND_DISKStorageLevel.MEMORY_AND_DISK_SERStorageLevel.MEMORY_AND_DISK_SER_2checkpoint 长久存储于【磁盘】重用,job结束后不会删除,涉及IO性能较差,安全且一般和cache组合使用
*/
val rddCache: RDD[T] = rdd.cache()
val rddCache: RDD[T] = rdd.persist(level:StorageLevel)
rdd.checkpoint()/*广播变量:broadcast:【如下图】将数据集或配置广播到每个Executor以readonly方式存在,不会在Task之间传输若不使用广播变量,则将会为每个Task发送一份数据
*/
val bc:BroadCast[T] = sc.broadcast(value:T)
rdd.mapPartitions(itPar=>{val v:T = bc.value...
})/*累加器:accumulate:只能 add 操作,常用于计数1、定义在Driver端的一个变量,Cluster中每一个Task都会有一份Copy2、所有的Task都计算完成后,将所有Task中的Copy合并到驱动程序中的变量中非累加器:在所有Task中的都会是独立Copy,不会有合并自定义累加器:写一个类继承 AccumulatorV2[IN, OUT]abstract class AccumulatorV2[IN, OUT] extends Serializable {// Returns if this accumulator is zero value or notdef isZero: Boolean// Creates a new copy of this accumulator, which is zero valuedef copyAndReset(): AccumulatorV2[IN, OUT] = {...}// Creates a new copy of this accumulator.def copy(): AccumulatorV2[IN, OUT]// Resets this accumulator, which is zero value.def reset(): Unit// 添加:Takes the inputs and accumulates.def add(v: IN): Unit// 合并:Merges another same-type accumulator and update its state.def merge(other: AccumulatorV2[IN, OUT]): Unit// 值列表:Defines the current value of this accumulatordef value: OUT}
*/
val accLong: LongAccumulator = sc.longAccumulator("longAcc")
val accDouble: DoubleAccumulator = sc.doubleAccumulator("doubleAcc")
rdd.mapPartitions(itPar=>{...accLong.add(v:Long)accDouble.add(v:Double)...
})
accXxx.reset()
val isZero:Boolean = accXxx.isZero
val num:Long|Double = accXxx.value|sum|count|avg/*
【分区控制】【缩减分区节省资源】 或 【扩大分区提高并行度】coalesce(numPartitions:Int, shuffle:Boolean):缩小分区存在过多的小任务的时候收缩合并分区,减少分区的个数,减少任务调度成本默认情况下,不会对数据重组,比如:3个合成2个,采用 {1+2},{3},容易导致数据倾斜若需数据均衡,则将 shuffle 参数设置为 true 即可扩大分区若需要扩大分区,shuffle 参数必须设置为 true若将2个分区拆分成3个,必须打乱重新分区,否则数据还是在两个分区,{1},{2},{空}repartition(numPartitions:Int) <=> coalesce(numPartitions,true)
*/
val rdd: RDD[String] = rdd.coalesce(numPartitions:Int, shuffle:Boolean)
val rdd: RDD[String] = rdd.repartition(numPartitions:Int) // ✔

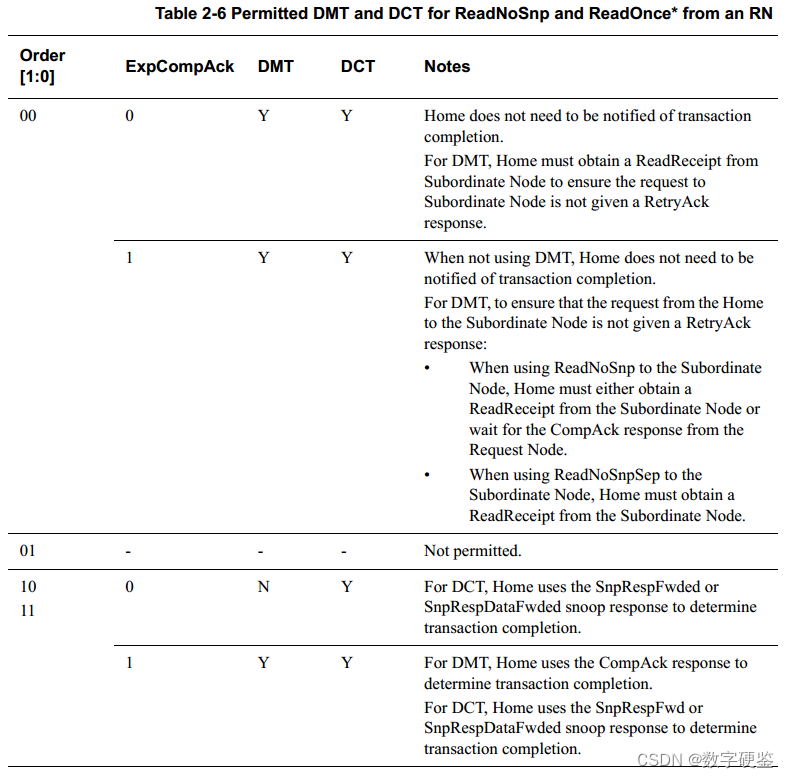
阶段划分 DAG
/*【为什么要划分阶段】1、基于数据的分区,本着传递计算的性能远高于传递数据,所以数据本地化是提升性能的重要途径之一2、一组串行的算子,无需 Shuffle,基于数据本地化可以作为一个独立的阶段连续执行3、经过一组串行算子计算,遇到 Shuffle 操作,默认情况下 Shuffle 不会改变分区数量,但会因为 numPartitions:Int, partitioner:Partitioner 等参数重新分配,过程数据会【写盘供子RDD拉取(类MapReduce)】
*//*Driver程序提交后1、Spark调度器将所有的RDD看成是一个Stage2、然后对此Stage进行逆向回溯,遇到Shuffle就断开,形成一个新的Stage3、遇到窄依赖,则归并到同一个Stage(TaskSet)4、等到所有的步骤回溯完成,便生成一个DAG图RDD依赖关系Lineage:血统、遗传RDD最重要的特性之一,保存了RDD的依赖关系RDD实现了基于Lineage的容错机制依赖关系 org.apache.spark.Dependency窄依赖 NarrowDependency1V1 OneToOneDependency1VN RangeDependency宽依赖 ShuffleDependency当RDD分区丢失时Spark会对数据进行重新计算,对于窄依赖只需重新计算一次子RDD的父RDD分区若配合持久化更佳:cache,persist,checkpoint 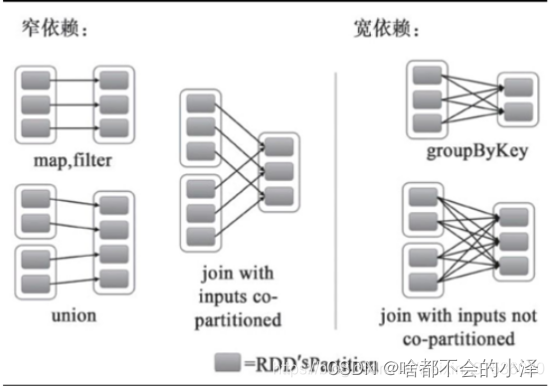
/*【计算任务】DAGScheduler: Submitting 4 missing tasks from ShuffleMapStage 0MapPartitionsRDD[3] at 【flatMap】 at SparkTest.scala:33Adding task set 0.0 with 4 tasksStarting|Running|Finished task 0.0 1.0 2.0 3.0DAGScheduler: Submitting 4 missing tasks from ResultStage 1 MapPartitionsRDD[7] at 【sortBy】 at SparkTest.scala:36Adding task set 1.0 with 4 tasksStarting|Running|Finished task 0.0 1.0 2.0 3.0DAGScheduler: Submitting 4 missing tasks from ShuffleMapStage 3 MapPartitionsRDD[5] at 【sortBy】 at SparkTest.scala:36Adding task set 3.0 with 4 tasksStarting|Running|Finished task 0.0 1.0 2.0 3.0DAGScheduler: Submitting 4 missing tasks from ResultStage 4MapPartitionsRDD[10] at 【saveAsTextFile】 at SparkTest.scala:37Adding task set 4.0 with 4 tasks
*/val path = "data/wordcount.txt"
sc.textFile(path, 4)
.mapPartitions(_.map(_.split("[^a-zA-Z]+").map((_, 1)).groupBy(_._1).map(t2 => (t2._1, t2._2.length)))
)
.flatMap(a => a.map(t => t))
.reduceByKey(_+_)
.sortBy(_._2,false)
.saveAsTextFile("data/test_out8")算子宽窄依赖划分
// 窄依赖
rdd.dependenciesmapflatMapmapPartitionsmapPartitionsWithIndexglomfilterdistinctintersectionsampleunionsubtractzip...cogroup
// 宽依赖ShuffledRDD extends RDDsortBysortByKeypartitionByrepartition// 不一定
/*reduceByKey(【partitioner: Partitioner】, func: (V, V) => V)若使用的是带 partitioner 的重载且 Partitioner 和父RDD的 Partitioner一致则为窄依赖RDD,否则为宽依赖ShuffledRDD
*/
coalesce(nump: Int, shuffle: Boolean = false, pc:partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null)
join[W](other: RDD[(K, W)], partitioner: Partitioner)
groupBy[K](f: T => K, p: Partitioner)
reduceByKey(partitioner: Partitioner, func: (V, V) => V)
foldByKey(zeroValue: V, partitioner: Partitioner)(func: (V, V) => V)
aggregateByKey[U](z: U, p: Partitioner)(seqOp: (U, V) => U,combOp: (U, U) => U)
combineByKey[C](c: V => C,merge: (C, V) => C,mergeCombine: (C, C) => C,partitioner: Partitioner,mapsizeCombine: Boolean = true,serializer: Serializer = null)=> combineByKeyWithClassTag(createCombiner: V => C,mergeValue: (C, V) => C,mergeCombiners: (C, C) => C,partitioner: Partitioner,mapSideCombine: Boolean = true,serializer: Serializer = null) => if (self.partitioner == Some(partitioner)) {self.mapPartitions(iter => {...}, preservesPartitioning = true)} else {new ShuffledRDD[K, V, C](self, partitioner)...}任务提交
# 默认路径为 HDFS
spark-submit \
--class cha05.SparkTest \
--master local[*] \
/root/spark/scala-1.0.jar \
file:root/spark/story.txt \
file:root/spark/wc_story01