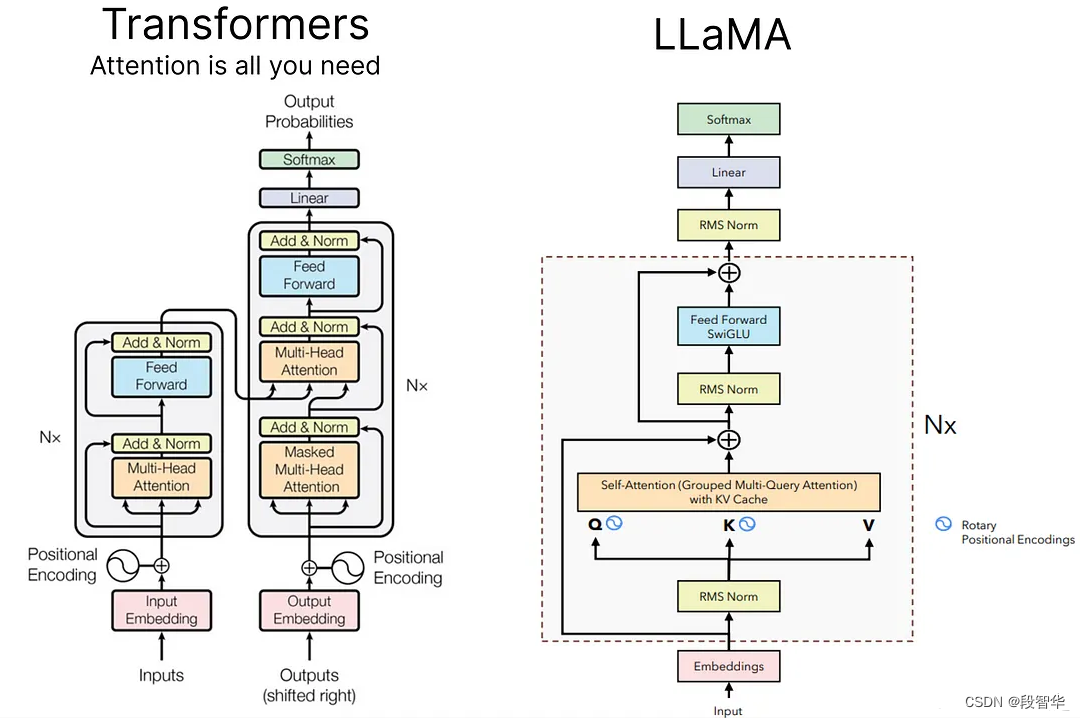
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(四)分组多查询注意力
Grouped-query Attention,简称GQA
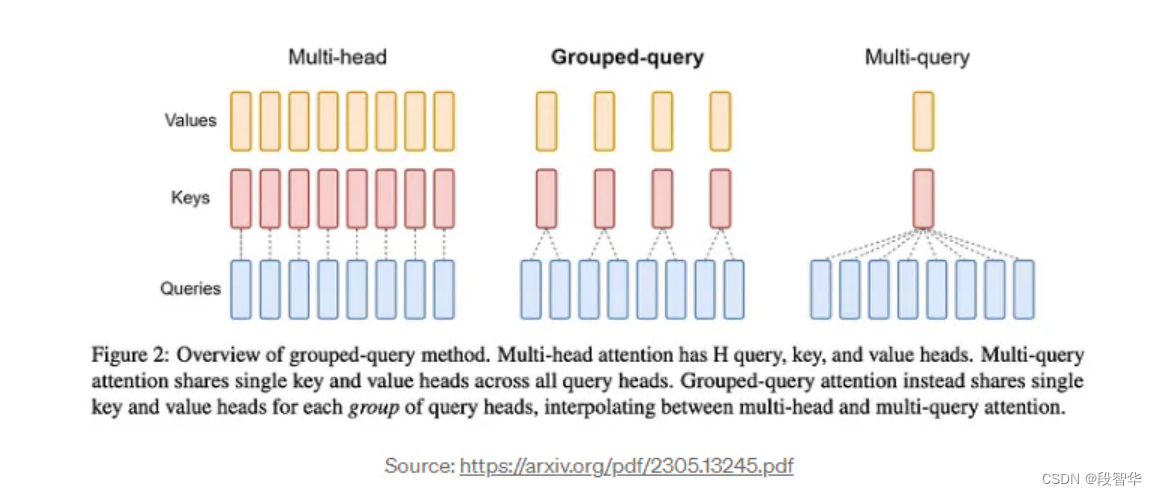
分组查询注意力(Grouped-query Attention,简称GQA)是多查询和多头注意力的插值。它在保持与多查询注意力相当的处理速度的同时,实现了与多头注意力相似的质量。
自回归解码的标准做法是缓存序列中先前标记的键和值,以加快注意力计算的速度。
-
然而,随着上下文窗口或批量大小的增加,多头注意力(Multi-Head Attention,简称MHA)模型中键值缓存(Key-Value Cache,简称KV Cache)的大小所关联的内存成本显著增加。
-
多查询注意力(Multi-Query Attention,简称MQA)是一种机制,它对多个查询仅使用单个键值头,这可以节省内存并大幅加快解码器的推理速度。
-
Llama(一种模型)整合了GQA,以解决在Transformer模型自回归解码期间的内存带宽挑战。主要问题源于GPU进行计算的速度比它们将数据移入内存的速度快。在每个阶段都需要加载解码器权重和注意力键,这消耗了大量的内存。
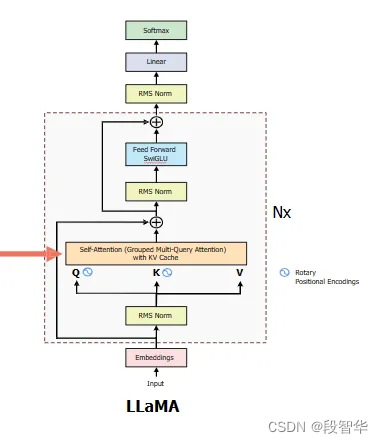
class SelfAttention(nn.Module): def __init__(self, args: ModelArgs):super().__init__()self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads# Indicates the number of heads for the queriesself.n_heads_q = args.n_heads# Indiates how many times the heads of keys and value should be repeated to match the head of the Queryself.n_rep = self.n_heads_q // self.n_kv_heads# Indicates the dimentiona of each headself.head_dim = args.dim // args.n_headsself.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False)self.wk = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wv = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False)self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim))self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim))def forward(self, x: torch.Tensor, start_pos: int, freq_complex: torch.Tensor):batch_size, seq_len, _ = x.shape #(B, 1, dim)# Apply the wq, wk, wv matrices to query, key and value# (B, 1, dim) -> (B, 1, H_q * head_dim)xq = self.wq(x)# (B, 1, dim) -> (B, 1, H_kv * head_dim)xk = self.wk(x)xv = self.wv(x)# (B, 1, H_q * head_dim) -> (B, 1, H_q, head_dim)xq = xq.view(batch_size, seq_len, self.n_heads_q, self.head_dim)xk = xk.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)# (B, 1, H_kv * head_dim) -> (B, 1, H_kv, head_dim)xv = xv.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)# Apply the rotary embeddings to the keys and values# Does not chnage the shape of the tensor# (B, 1, H_kv, head_dim) -> (B, 1, H_kv, head_dim)xq = apply_rotary_embeddings(xq, freq_complex, device=x.device)xk = apply_rotary_embeddings(xk, freq_complex, device=x.device)# Replace the enty in the cache for this tokenself.cache_k[:batch_size, start_pos:start_pos + seq_len] = xkself.cache_v[:batch_size, start_pos:start_pos + seq_len] = xv# Retrive all the cached keys and values so far# (B, seq_len_kv, H_kv, head_dim)keys = self.cache_k[:batch_size, 0:start_pos + seq_len]values = self.cache_v[:batch_size, 0:start_pos+seq_len] # Repeat the heads of the K and V to reach the number of heads of the querieskeys = repeat_kv(keys, self.n_rep)values = repeat_kv(values, self.n_rep)# (B, 1, h_q, head_dim) --> (b, h_q, 1, head_dim)xq = xq.transpose(1, 2)keys = keys.transpose(1, 2)values = values.transpose(1, 2)# (B, h_q, 1, head_dim) @ (B, h_kv, seq_len-kv, head_dim) -> (B, h_q, 1, seq_len-kv)scores = torch.matmul(xq, keys.transpose(2,3)) / math.sqrt(self.head_dim)scores = F.softmax(scores.float(), dim=-1).type_as(xq)# (B, h_q, 1, seq_len) @ (B, h_q, seq_len-kv, head_dim) --> (b, h-q, q, head_dim)output = torch.matmul(scores, values)# (B, h_q, 1, head_dim) -> (B, 1, h_q, head_dim) -> ()output = (output.transpose(1,2).contiguous().view(batch_size, seq_len, -1))return self.wo(output) # (B, 1, dim) -> (B, 1, dim)
系列博客
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(一)
https://duanzhihua.blog.csdn.net/article/details/138208650
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(二)
https://duanzhihua.blog.csdn.net/article/details/138212328
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(三)KV缓存
https://duanzhihua.blog.csdn.net/article/details/138213306