1.安装启动
1.1.下载解压
1.2. 启动环境
需安装Jdk8,Kafka可以使用ZooKeeper或KRaft启动。
- ZooKeeper启动
运行如下命令,以正确的顺序启动所有服务:
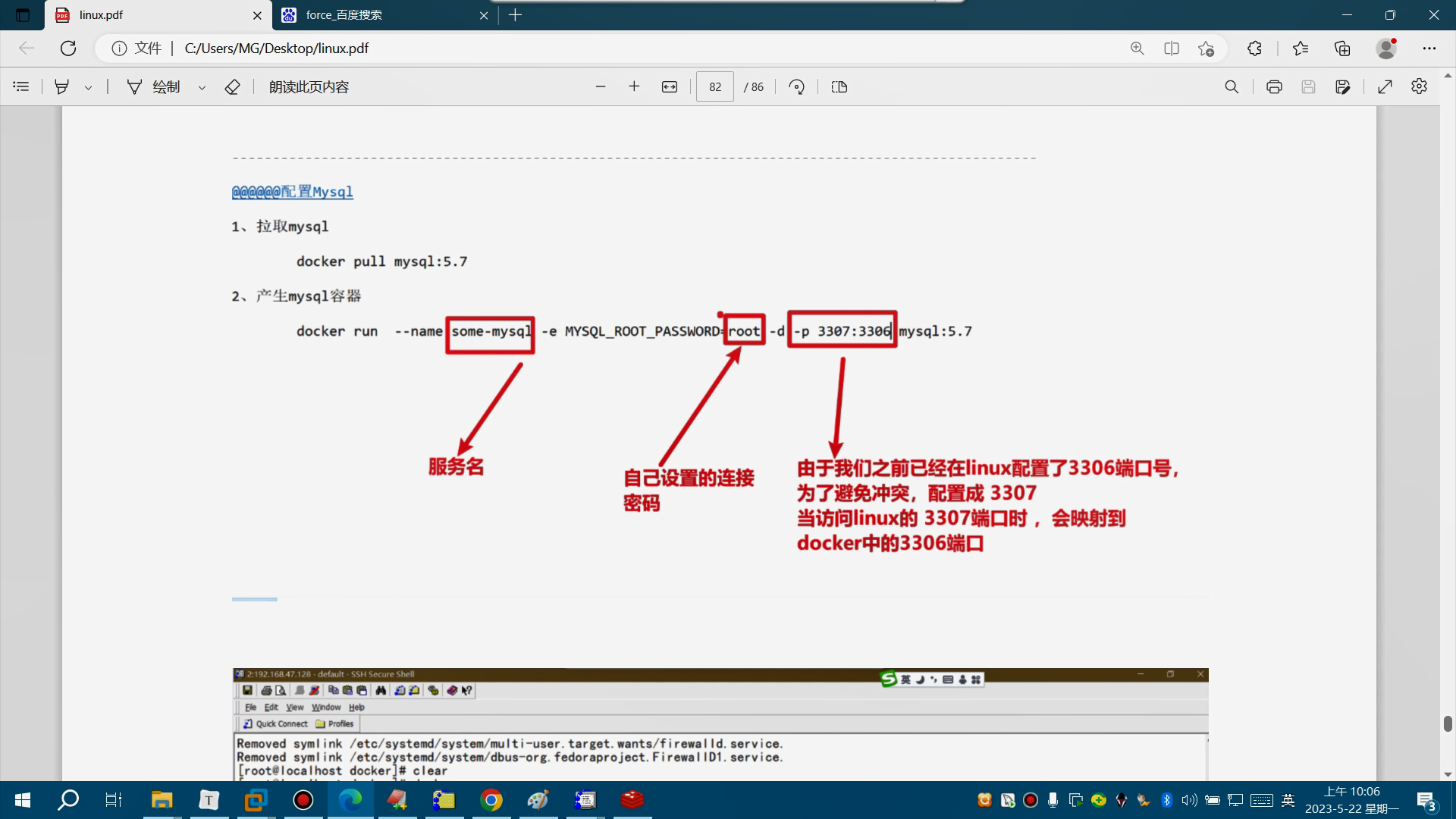
打开另一个终端会话并运行:# 启动zooKeeper服务 $ bin/zookeeper-server-start.sh config/zookeeper.properties# 启动Kafka broker服务 $ bin/kafka-server-start.sh config/server.properties - KRaft启动
Kafka可以使用KRaft模式运行,使用本地脚本和下载的文件或docker镜像。按照下面的一个部分来启动kafka服务器,但不要同时执行两个部分。
-
使用下载的文件
生成集群UUID$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"格式化日志目录
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties启动kafka服务
$ bin/kafka-server-start.sh config/kraft/server.properties -
使用docker镜像
获取docker镜像
docker pull apache/kafka:3.7.0启动kafka docker容器
$ docker run -p 9092:9092 apache/kafka:3.7.0
kafka_48">1.3.停止kafka
- 使用
Ctrl-C停止生产者和消费者客户端(如果还开启的话)。 - 用
Ctrl-C停止Kafka broker。 - 最后,如果使用ZooKeeper启动的kafka,用
Ctrl-C停止ZooKeeper服务器。
如果你还想删除本地Kafka环境的任何数据,包括你在此过程中创建的任何事件,运行命令:
$ rm -rf /tmp/kafka-logs /tmp/zookeeper /tmp/kraft-combined-logs
2.简单使用
2.1.创建主题
打开一个终端会话并运行:
$ bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
所有Kafka的命令行都有额外的选项:执行不带参数的kafka-topics.sh命令显示使用信息。例如,它还可以显示新主题的分区计数等详细信息:
$ bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
Topic: quickstart-events TopicId: NPmZHyhbR9y00wMglMH2sg PartitionCount: 1 ReplicationFactor: 1
Configs:
Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0
2.2.send数据到主题
kafka客户端读写事件通过网络与kafka brokers通信,运行控制台生产者客户端,将一些事件写入主题。默认情况下,您输入的每一行都将导致将一个单独的事件写入主题。
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
This is my first event
This is my second event
可以随时使用Ctrl-C停止生产者客户端
2.3.poll数据从主题
打开另一个终端会话并运行console消费者客户端来读取你刚刚创建的事件:
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
This is my first event
This is my second event
可以随时使用Ctrl-C停止生产者客户端
kafka_85">2.4.导入/导出你的数据作为事件流与kafka连接
可能在现有系统(如关系数据库或传统消息传递系统)中有大量数据,以及许多已经使用这些系统的应用程序。Kafka Connect允许你不断地从外部系统摄取数据到Kafka,反之亦然。它是一个可扩展的运行连接器工具,实现用于与外部系统交互的自定义逻辑。因此,将现有系统与Kafka集成非常容易。为了使这个过程更容易,有数百个这样的连接器随时可用。
下面我们介绍如何使用简单的连接器来运行Kafka Connect,将数据从文件导入到Kafka主题,并将数据从Kafka主题导出到文件。
首先,确保将connect-file-3.7.0.jar添加到插件中。在Connect worker的配置中设置path属性。为了简单起见,我们将使用一个相对路径,并将连接器的包视为一个uber jar,当快速入门命令从安装目录运行时,它就会工作。然而,值得注意的是,对于生产部署,使用绝对路径总是可取的。plugin.path用于获取如何设置此配置的详细说明。
- 编辑
config/connect-standalone. properties文件,添加或更改plugin.path配置属性匹配如下,并保存文件:> echo "plugin.path=libs/connect-file-3.7.0.jar" - 然后,首先创建一些send数据进行测试:
> echo -e "foo\nbar" > test.txt - 或者在Windows上:
> echo foo> test.txt > echo bar>> test.txt
接下来,我们将启动以独立模式运行的两个连接器,这意味着它们在单个本地专用进程中运行。我们提供了三个配置文件作为参数。第一个总是Kafka Connect进程的配置,包含常见的配置,比如Kafka要连接的代理和数据的序列化格式。其余的配置文件分别指定要创建的连接器。这些文件包括唯一的连接器名称、要实例化的连接器类以及连接器所需的任何其他配置。
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
这些示例配置文件,包含在Kafka中,使用您之前启动的默认本地集群配置并创建两个连接器:第一个是源连接器,它从输入文件中读取行并将每个行生成到Kafka主题,第二个是接收器连接器,它从Kafka主题中读取消息并将每个消息作为输出文件中的一行生成。
在启动期间,您将看到许多日志消息,包括一些指示连接器正在实例化的消息。一旦Kafka Connect进程启动,源连接器应该开始从test.txt中读取行并将其生成到主题Connect -test,接收器连接器应该开始从主题Connect -test中读取消息并将其写入文件test.sink.txt。我们可以通过检查输出文件的内容来验证数据已经通过整个管道传递:
> more test.sink.txt
foo
bar
请注意,数据被存储在Kafka主题connect-test中,所以我们也可以运行一个控制台消费者来查看主题中的数据(或者使用自定义消费者代码来处理它):
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
连接器继续处理数据,因此我们可以将数据添加到文件中,并看到它在管道中移动:
> echo Another line>> test.txt
kafka_127">2.5.用kafka流处理事件
一旦你的数据作为事件存储在Kafka中,你就可以使用Kafka Streams客户端库处理数据。它允许你实现关键任务的实时应用和微服务,其中输入和/或输出数据存储在Kafka主题中。Kafka Streams结合了在客户端编写和部署标准Java和Scala应用程序的简单性,以及Kafka服务器端集群技术的优势,使这些应用程序具有高度可扩展性、弹性、容错性和分布式。该库支持一次处理、有状态操作和聚合、窗口、连接、基于事件时间的处理等等。
下面是如何实现流行的WordCount算法:
KStream<String, String> textLines = builder.stream("quickstart-events");KTable<String, Long> wordCounts = textLines.flatMapValues(line -> Arrays.asList(line.toLowerCase().split(" "))).groupBy((keyIgnored, word) -> word).count();wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));


![【SpringBoot整合系列】SpringBoot整合Redis[附redis工具类源码]](https://img-blog.csdnimg.cn/direct/a9d9f0edb2a14dd0ab4f7509c89993b6.png)