一、函數進階復習
1、行轉列
select '用水儿量(噸)' 统计项, sum(case when t_account.month='01' then USENUM end) 一月, sum(case when t_account.month='02' then USENUM end) 二月, sum(case when t_account.month='03' then USENUM end) 三月, sum(case when t_account.month='04' then USENUM end) 四月, sum(case when t_account.month='05' then USENUM end) 五月, sum(case when t_account.month='06' then USENUM end) 六月 from t_accountunion all select '金額(元)' 统计项, sum(case when t_account.month='01' then money end) 一月, sum(case when t_account.month='02' then money end) 二月, sum(case when t_account.month='03' then money end) 三月, sum(case when t_account.month='04' then money end) 四月, sum(case when t_account.month='05' then money end) 五月, sum(case when t_account.month='06' then money end) 六月 from t_account;

2、nvl函數統計0值
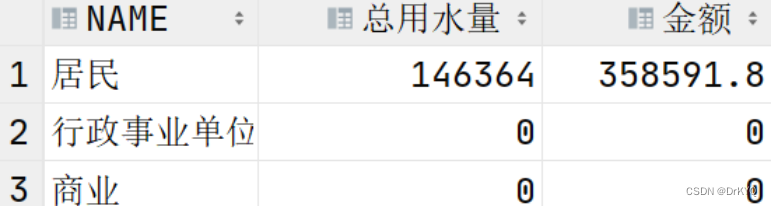
统计用水量 ,收费金额 (分类型统计)
根据业主类型分别统计每种居民的用水量 (整数 ,四舍五入) 及收费金额 ,如
果该类型在台账表中无数据也需要列出值为 0 的记录.
效果如下 :
分析 :这里所用到的知识点包括左外连接、sum()、分组 group by 、round() 和 nvl()
 select distinct t2.name 姓名,round(sum(nvl(usenum,0)) over (partition by t2.id),0 )用水量,sum(nvl(money,0)) over (partition by t2.id) 總金額 fromt_account t1 right join t_ownertype t2 on t1.ownertype=t2.id;
select distinct t2.name 姓名,round(sum(nvl(usenum,0)) over (partition by t2.id),0 )用水量,sum(nvl(money,0)) over (partition by t2.id) 總金額 fromt_account t1 right join t_ownertype t2 on t1.ownertype=t2.id;
3、簡單查詢
统计每个区域的业主户数 ,如果该区域没有业主户数也要列出 0
select distinct t3.name 區域, count(t1.id) over (partition by t3.id) 人數 from t_owners t1 join t_address t2 on t1.addressid=t2.id right join t_area t3 on t2.areaid=t3.id;

二、窗口函數進階
1、學生成績查詢
现有“成绩表”,需要我们取得每名学生不同课程的成绩排名.
已知条件 分数表
结果
student_name
course_name
score
student_name
course_name
score
rn
小明
数学
85
小明
物理
92
1
小明
英语
78
小明
数学
85
2
小明
物理
92
小明
英语
78
3
小红
数学
90
小李
数学
90
1
小红
英语
80
小李
英语
85
2
小李
数学
90
小李
物理
85
3
小李
数学
60
小李
数学
60
4
小李
英语
85
小红
数学
90
1
小李
物理
85
小红
英语
80
2
代碼:
通過row number序號查詢
select student_name,course_name,score, row_number() over (partition by student_name order by score desc ) 排名 from t_score;
2、 去除最大值、最小值后求平均值
“薪水表”中记录了雇员编号、部门编号和薪水。要求查询出每个部门去除最高、最低薪水后的平均薪水。
已知条件 薪资表
结果
employee_id
department_id
salary
department_id
avg_salary
1
1
50000
1
50000
2
1
52000
2
60000
3
1
48000
4
1
51000
5
1
49000
6
2
60000
7
2
58000
8
2
62000
9
2
59000
10
2
61000
代碼:
with t1 as ( select department_id,salary, row_number() over (partition by department_id order by salary )序号, row_number() over (partition by department_id order by salary desc )序号1 from t_salary_table ) select department_id,avg(salary) from t1 where 序号>1 and 序号1>1 group by department_id;
3、Top N问题
查询前三名的成绩
-- “成绩表”中记录了学生选修的课程号、学生的学号,以及对应课程的成绩。 -- 为了对学生成绩进行考核,现需要查询每门课程前三名学生的成绩。 -- # todo 注意:如果出现同样的成绩,则视为同一个名次
输入
输出
course_id
student_id
score
course_id
student_id
score
rn
1
1
85
1
3
92
1
1
2
78
1
6
92
1
1
3
92
1
8
92
1
1
4
90
1
4
90
2
1
5
80
1
1
85
3
1
6
92
1
9
85
3
1
7
78
2
3
90
1
1
8
92
2
8
90
1
1
9
85
2
1
88
2
2
1
88
2
6
88
2
2
2
82
2
4
85
3
2
3
90
2
4
85
2
5
78
2
6
88
2
7
82
2
8
90
2
9
82
代碼:
with t1 as ( select student_id,course_id,score,dense_rank() over (partition by COURSE_ID order by score desc )序号 from t_score2) select course_id,student_id, score from t1 where 序号 <=3;
4、Top N問題
查询排在前两名的工资
“雇员表”中是公司雇员的信息,每个雇员有其对应的工号、姓名、工资和部门编号。
现在要查找每个部门工资排在前两名的雇员信息,若雇员工资一样,则并列获取。
已知条件 雇员表
结果表
emp_id
emp_name
salary
department_id
emp_id
emp_name
salary
department_id
rn
1
小明
50000
1
6
小刚
62000
1
1
2
小红
52000
1
4
小张
60000
1
2
3
小李
48000
1
10
小华
52000
2
1
4
小张
60000
1
11
小雷
52000
2
1
5
小王
58000
1
9
小晓
49000
2
2
6
小刚
62000
1
7
小丽
45000
2
8
小芳
47000
2
9
小晓
49000
2
10
小华
52000
2
11
小雷
52000
2
代碼:
with t1 as ( select emp_id,emp_name,department_id,salary,dense_rank() over (partition by department_id order by salary desc )序号 from t_employee ) select emp_id,emp_name,department_id,salary from t1 where 序号<3;
5、連續問題
员工的 累计工资汇总 可以计算如下:
对于该员工工作的每个月,将 该月 和 前两个月 的工资 加 起来。这是他们当月的 3 个月总工资和 。如果员工在前几个月没有为公司工作,那么他们在前几个月的有效工资为 0 。
不要 在摘要中包括员工 最近一个月 的 3 个月总工资和。
不要 包括雇员 没有工作 的任何一个月的 3 个月总工资和。
返回按 id 升序排序 的结果表。如果 id 相等,请按 month 降序排序。

代碼:
select id,month,sum(salary)over (partition by id order by month descrange between current row and 2 following )馬内 from t_employee1;
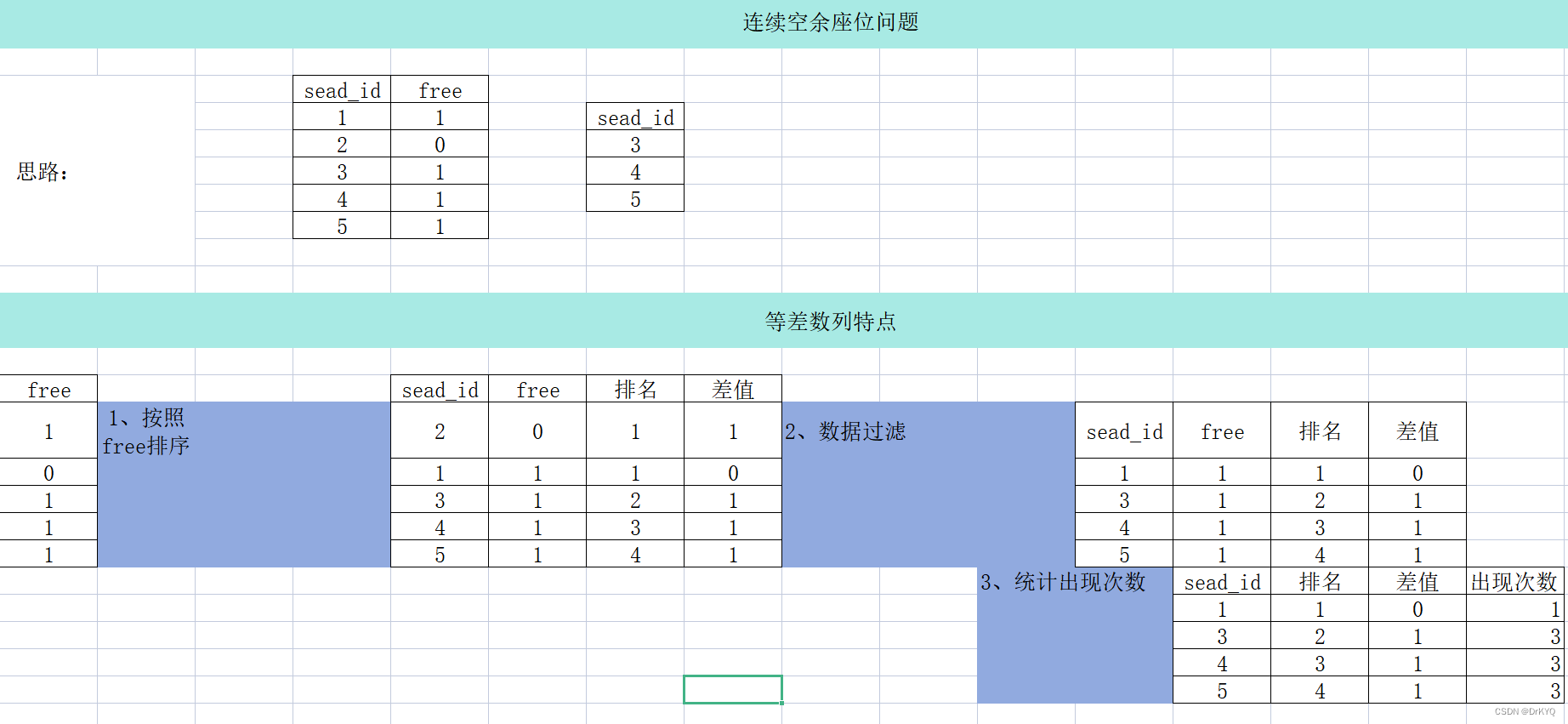
6、连续空余座位抛真题
-- # todo 查找电影院所有连续可用的座位。 -- # todo 返回按 seat_id 升序排序 的结果表。 -- # todo 测试用例的生成使得两个以上的座位连续可用。

代碼1:
-- 第一種方法 -- 1、先按照free分組 打亂seat——id -- 2、再加入一條等差數列row num 進行對比 因爲使用over partition by 所以 可以直接加等差數列 select Cinema.*,row_number() over (partition by free order by seat_id) 等差數列 from CINEMA; -- 3、再把沒有空位置的Free給篩選掉 select Cinema.*,row_number() over (partition by free order by seat_id) 等差數列 from CINEMA where free=1; -- 4、桌位id減去等差數列如果數字一樣(差值),則證明是連續的 select Cinema.*,seat_id-row_number() over (partition by free order by seat_id) 差值 from CINEMA where free=1; -- 5、按差值和判斷是否連續的字段(free)分組,進行計數 with t1 as ( select Cinema.*,seat_id-row_number() over (partition by free order by seat_id) 差值 from CINEMA where free=1) select t1.*,count(*) over (partition by t1.差值,free) 計數 from t1; -- 6、計數條件判斷是否大於XXX,幾個連續的,如果連續2就大於等於2,即可 with t1 as ( select Cinema.*,seat_id-row_number() over (partition by free order by seat_id) 差值 from CINEMA where free=1),t2 as ( select t1.*,count(*) over (partition by t1.差值,free) 計數 from t1) select t2.seat_id from t2 where 計數>=2 order by seat_id ;
代碼2:
-- 第二種方法 with t1 as (select Cinema.*,lead(free, 1) over (order by seat_id) rn1,lag(free, 1) over (order by seat_id) rn2from Cinema) select seat_id from t1 where (t1.free = 1 and t1.rn1 = 1)or (t1.rn1 is null and t1.rn2 = 1 and t1.free=1);
附(連續問題的解題思路):