目录
概述
业务驱动因素
目标和原则
基本概念
数据质量维度
数据质量改进生命周期
数据质量问题的常见原因
数据剖析
活动
工具
有效的数据质量指标
根本原因分析
度量指标
扩展
数据质量作业一般包含的内容:
数据质量规则一般包含的内容:
例如一个数据质量校验:
数据质量提升目标与要求:
数据质量规则八性注解:
质量校验SQL举例:
概述
与数据治理和整体数据管理一样,数据质量(Data Quality)管理不是一个项目,而是一项持续性工作。
业务驱动因素
高质量数据本身并不是目的,它只是组织获取成功的一种手段。
目标和原则
数据质量管理的原则是重要的数据先开始,PDCA过程,评估维度、根因分析、质量报告。
数据质量管理应遵循以下原则:
- 重要性。数据质量管理应关注对企业及其客户最重要的数据,改进的优先顺序应根据数据的重要性以及数据不正确时的风险水平来判定。
- 全生命周期管理。数据质量管理应覆盖从创建或采购直至处置的数据全生命周期,包括其在系统内部和系统之间流转时的数据管理(数据链中的每个环节都应确保数据具有高质量的输出)。
- 预防。数据质量方案的重点应放在预防数据错误和降低数据可用性等情形上,不应放在简单的纠正记录上。
- 根因修正。提高数据质量不只是纠正错误,因为数据质量问题通常与流程或系统设计有关所以提高数据质量通常需要对流程和支持它们的系统进行更改,而不仅仅是从表象来理解和解决。
- 治理。数据治理活动必须支持高质量数据的开发,数据质量规划活动必须支持和维持受治理的数据环境。
- 标准驱动。数据生命周期中的所有利益相关方都会有数据质量要求。在可能的情况下,对于可量化的数据质量需求应该以可测量的标准和期望的形式来定义。
- 客观测量和透明度。数据质量水平需要得到客观、一致的测量。应该与利益相关方一同讨论与分享测量过程和测量方法,因为他们是质量的裁决者。
- 嵌人业务流程。业务流程所有者对通过其流程生成的数据质量负责,他们必须在其流程中实施数据质量标准。
- 系统强制执行。系统所有者必须让系统强制执行数据质量要求。
- 与服务水平关联。数据质量报告和问题管理应纳入服务水平协议 (SLA)。
基本概念
高质量的数据:数据质量如达到数据消费者的期望和需求。
企业的关键数据:
- 监管报告;
- 财务报告;
- 商业政策;
- 持续经营;
- 商业战略,尤其是差异化竞争战略
数据质量维度
有好几套,可以看下,Strong-Wang框架、Thomas Redman的、Larry English的、DAMA UK发布的。
其中DAMA UK发布的白皮书,描述了数据质量的6各核心维度,用的比较多:

数据质量改进生命周期
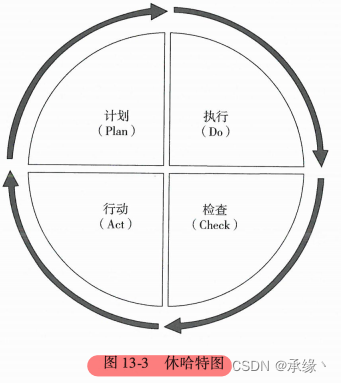
- 计划(Plan)阶段。数据质量团队评估已知问题的范围、影响和优先级,并评估解决这些问题的备选方案。这一阶段应该建立在分析问题根源的坚实基础上,从问题产生的原因和影响的角度了解成本/效益,确定优先顺序,并制订基本计划以解决这些问题。
- 执行(Do)阶段。数据质量团队负责努力解决引起问题的根本原因,并做出对持续监控数据的计划。对于非技术流程类的根本原因,数据质量团队可以与流程所有者一起实施更改。对于需要技术变更类的根本原因,数据质量团队应与技术团队合作,以确保需求得到正确实施,并且技术变更不会引发错误。
- 检查(Check)阶段。这一阶段包括积极监控按要求测量的数据质量。只要数据满足定义的质量阙值,就不需要采取其他行动,这个过程将处于控制之中并能满足商业需求。如果数据低于可接受的质量闻值,则必须采取额外措施使其达到可接受的水平。
- 处理(Act)阶段。这一阶段是指处理和解决新出现的数据质量问题的活动。随着问题原因的评估和解决方案的提出,循环将重新开始。通过启动一个新的周期来实现持续改进。新周期开始于:
- 现有测量值低于闽值
- 新数据集正在调查中。
- 对现有数据集提出新的数据质量要求。
- 业务规则、标准或期望变更。
数据质量问题的常见原因
数据质量问题在数据生命周期的任何节点都有可能出现,如数据输入、数据处理、系统设计、自动化流程中的手动干预问题等。
- 缺乏领导力导致的问题
- 数据输入过程引起的问题
- 数据处理功能引起的问题
- 系统设计引起的问题
最常见的问题其实就是“缺乏领导力导致的问题”和“企业文化导致的问题”。
数据剖析
数据剖析不是解决数据质量问题的方法,是一种用于检查数据和评估质量的数据分析形式。剖析引擎生成统计信息,分析人员可以使用这些统计信息识别数据内容和结构中的模式。例如:
- 空值数;
- 最大/最小值;
- 最大/最小长度;
- 单个列值的频率分布;
- 数据类型和格式。
这个其实有点像我们之前搞的“数据探查”:
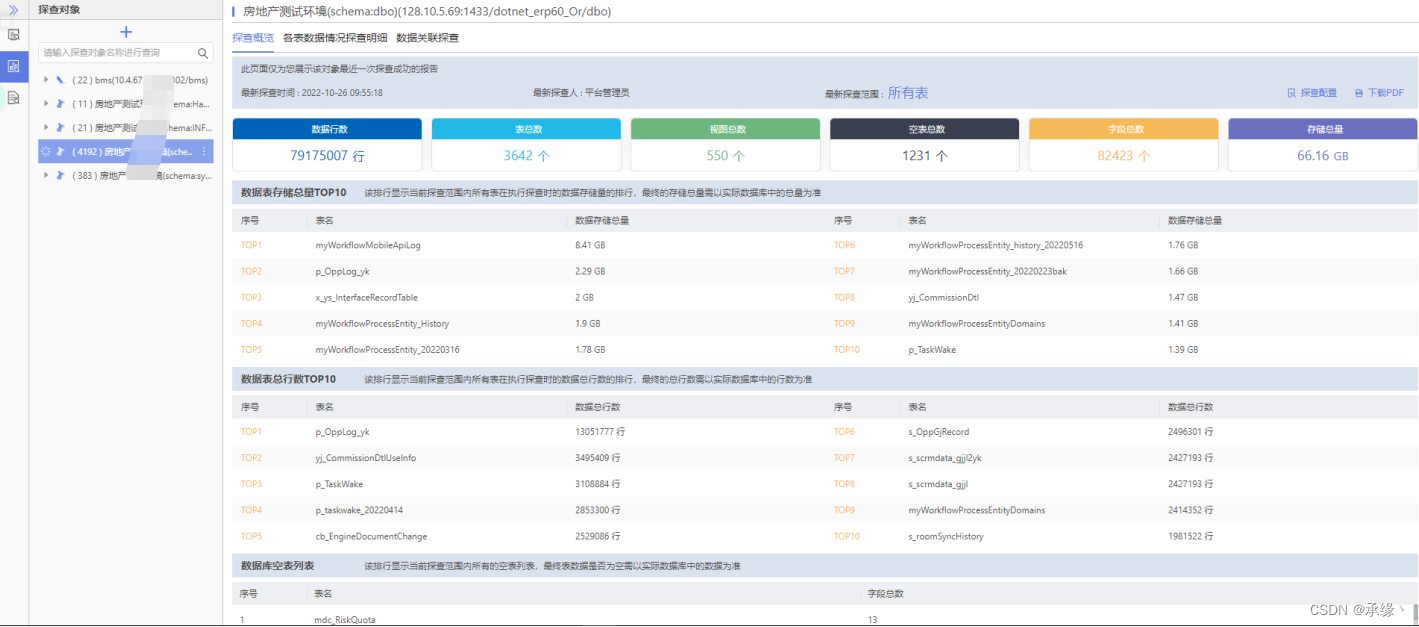
活动
这个地方我记了一个概念,POC,即“一个基本的概念证明(Proof of Concept)”,来演示改进进程是如何工作的。
工具
有效的数据质量指标

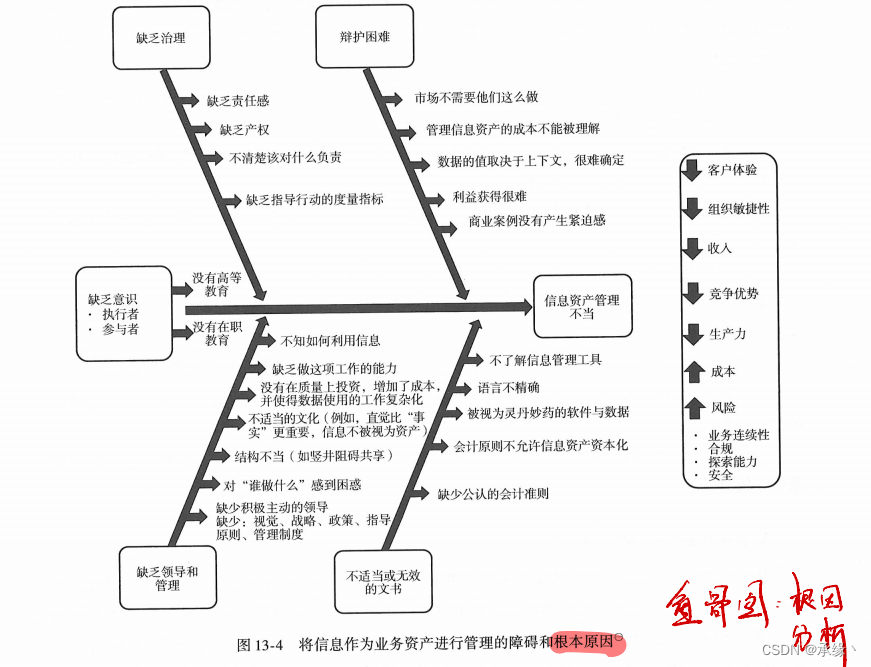
根本原因分析
常见的根因分析技术包括帕累托分析(80/20规则)、鱼骨图分析、跟踪和追踪、过程分析以及五个为什么等。
度量指标
数据质量的高阶指标有:
- 投资汇报;
- 质量水平;
- 数据质量趋势;
- 数据问题管理指标;
- 服务水平一致性。
扩展
举几个项目上对于数据质量实施的例子助于理解。
数据质量作业一般包含的内容:
- 编号
- 名称
- 描述
- 目录
- 告警级别
- 统一告警条件
- 告警通知
- 告警通知类型
- 告警通知主题
- 调度类型
- 调度开始日期
- 调度结束日期
- 调度周期
- 调度时间间隔
- 调度开始时间
- 调度结束时间
- 规则个数
数据质量规则一般包含的内容:
- 质量作业编号
- 规则类型
- 数据连接
- 连接类型
- 数据库
- SQL
- 数据表
- 表中文名称
- 参考表
- 字段
- 字段中文名称
- 参考字段
- 忽略规则错误
- 维度
- 队列
- 模板
- 匹配表达式
- 模板版本
- 权重
- 计算范围
- 计算范围SQL
- 告警条件
- 导出异常表
- 异常表数据库
- 异常表Schema
- 异常表信息
- 异常表前缀
- 异常表后缀
- 异常字段名
- 异常表SQL
- 异常表输出配置
- 是否包含空值
- 异常表输出数量
- 质量评分
- 质量评分Schema
- 质量评分表名
- 质量评分表达式
- 表所属层(贴源层/明细层/汇总层/集市层)
- "来源委办局(贴源层表必填)"
- "来源系统(贴源层表必填)"
例如一个数据质量校验:

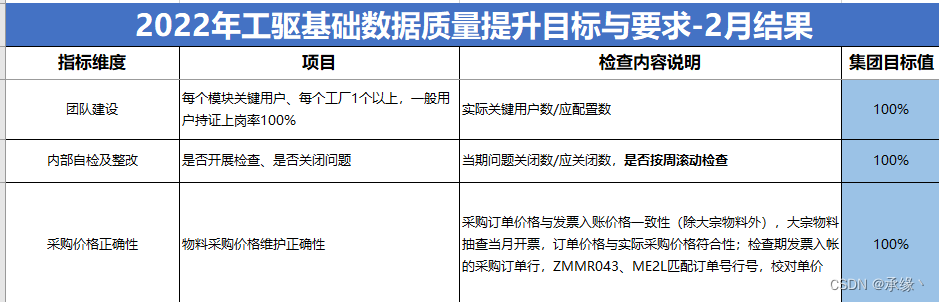
数据质量提升目标与要求:
数据质量规则八性注解:
| 指标大类名称 | 注解 | 指标小类名称 | 指标描述 | 权重 | 是否启用 |
| 规范性 | 符合数据标准、数据模型、业务规则、元数据或权威参考数据的程度 | 数据标准 | 数据符合数据标准的度量。 计算方法:X=A/B A=满足数据标准要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 5 | 是 |
| 数据模型 | 数据符合数据模型的度量。评价数据质量时需要检查是否存在清晰可理解的数据模型定义以及这些数据的组织形式,计算方法:X=A/B A=满足数据模型要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 0 | 是 | ||
| 元数据 | 数据符合元数据定义的度量。元数据标注、描述或刻画其他数据、以使检索、或使用信息更容易。评价数据质量时需要检查是否提供可解读的元数据文档。 计算方法:X=A/B A=满足元数据定义的数据集中元素的个数; B=被评价的数据集中元素的个数 | 0 | 是 | ||
| 业务规则 | 数据符合业务规则的度量。业务规则是一种权威性原则或指导方针,用来描述业务交互,并建立行动和数据行为结果及完整性的规则。评价数据质量时需要检查是否存在良好归档的业务规则。 计算方法:X=A/B A=满足业务规则的数据集中元素的个数; B=被评价的数据集中元素的个数 | 10 | 是 | ||
| 权威参考数据 | 参考数据是系统、应用软件、数据库、流程、报告等用来参考的数据集合或分类表。评价数据质量时需要收集参考数据列表。示例:一张用于一个特定字段的有效值列表作为一种参考数据类型。 计算方法:X=A/B A=满足参考数据规则的数据集中元素的个数; B=被评价的数据集中元素的个数 | 5 | 是 | ||
| 安全规范 | 安全规范是安全和隐私方面的规则,包括数据权限管理、数据脱敏处理等。 计算方法:X=A/B A=满足安全规范的数据集中元素的个数; B=被评价的数据集中元素的个数 | 10 | 是 | ||
| 完整性 | 按照数据规则要求,数据元素被赋予数值的程度,数据完整不缺失的 ,对应的规则为:空值校验,记录数校验,参照性校验(参照事实表,外键约束) | 数据元素完整性 | 按照业务规则要求,数据集中应被赋值的数据元素的赋值程度。 计算方法:X=A/B A=被赋值的数据集中元素的个数; B=预期被赋值的数据集中的元素的个数 | 10 | 是 |
| 数据记录完整性 | 按照业务规则要求,数据集中应被赋值的数据记录的赋值程度。 计算方法:X=A/B A=被赋值的数据集中元素的个数; B=预期被赋值的数据集中的元素的个数 | 10 | 是 | ||
| 准确性 | 数据准确表示其所描述的真实实体(实际对象)真实值的程度,数据是否准确,存储格式是否规范,对应的规则为:值域校验,格式校验,参照性校验(参照码表) | 数据内容正确性 | 数据内容是否是预期数据,计算方法:X=A/B A=满足数据正确性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 10 | 是 |
| 数据格式合规性 | 数据格式,包括数据类型、数值范围、数据长度、精度是否满足预期要求。例如性别一栏不能出现男/女以外的内容,身份证号不能出现标点符号等。 计算方法:X=A/B A=满足格式要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 5 | 是 | ||
| 数据重复率 | 特定字段、记录、文件或数据集意外重复的度量,计算方法:X=A/B A=重复的数据集中元素个数; B=被评价的数据集中元素的个数 | 5 | 是 | ||
| 数据唯一性 | 特定字段、记录、文件或数据集唯一性的度量,计算方法:X=A/B A=满足唯一性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 5 | 是 | ||
| 脏数据出现率 | 正确字段、记录、文件或数据集之外无效数据的度量。例如事务发生回滚时由于回滚机制不健全或不完善导致可能出现脏数据。 计算方法:X=A/B A=有脏数据出现的数据集中元素的个数; B=被评价的数据集中元素的个数 | 0 | 是 | ||
| 一致性 | 数据与其他特定上下文中使用的数据无矛盾的程度,同源或跨源数据是一致不冲突的,对应的规则为: 一致性校验 | 相同数据一致性 | 同一数据在不同位置存储或被不同应用或用户使用时,数据的一致性;数据发生变化时,存储在不同位置的同一数据 被同步修改,计算方法:X=A/B A=满足一致性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 10 | 是 |
| 关联数据一致性 | 根据一致性约束规则检查关联数据的一致性,计算方法:X=A/B A=满足一致性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 5 | 是 | ||
| 时效性 | 数据在时间变化中的正确程度,数据的加工是否满足时效性要求:对应规则为:及时性校验 | 基于时间段的正确性 | 基于日期范围的记录数或频率分布符合业务需求的程度,计算方法:X=A/B A=满足有效性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 4 | 是 |
| 基于时间点的及时性 | 基于时间戳的记录数、频率分布或延迟时间符合业务需求的程度,计算方法:X=A/B A=满足及时性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 4 | 是 | ||
| 时序性 | 数据集中同一实体的数据元素之间相对时序关系,计算方法:X=A/B A=满足时序性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 2 | 是 | ||
| 可访问性 | 数据能被访问的程度 | 可访问 | 数据在需要时的可获取性,计算方法:X=A/B A=满足可访问性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 0 | 是 |
| 可用性 | 数据在需要时的可获取性,计算方法:X=A/B A=满足可用性要求的数据集中元素的个数; B=被评价的数据集中元素的个数 | 0 | 是 | ||
| 合理性 | 数据之间的逻辑关系合理,变化趋势满足现实,对应的规则为: 逻辑校验、波动性校验,关系校验 | 0 | 否 | ||
| 唯一性 | 数据是唯一不重复的,对应的规则为:重复校验 | 0 | 否 |
质量校验SQL举例:
SELECT ifnull(b - a,0),ifnull(a,0),ifnull(b,0),ifnull(a/b,1)
FROM (SELECT (SELECT count(1) AS aFROM ${Schema_Table1}WHERE ${Column1} regexp '^[(11,12,13,19)|(51,52,53)|(91,92,93)|(Y1)]{2}[0-9]{6}[0-9a-zA-Z]{9}[0-9ABCDEFGHJKLMNPQRTUWXY]{1}$ |^([a-zA-Z0-9]){8}-?[a-zA-Z0-9]$' ) a,(SELECT count(1) AS bFROM ${Schema_Table1} ) b )