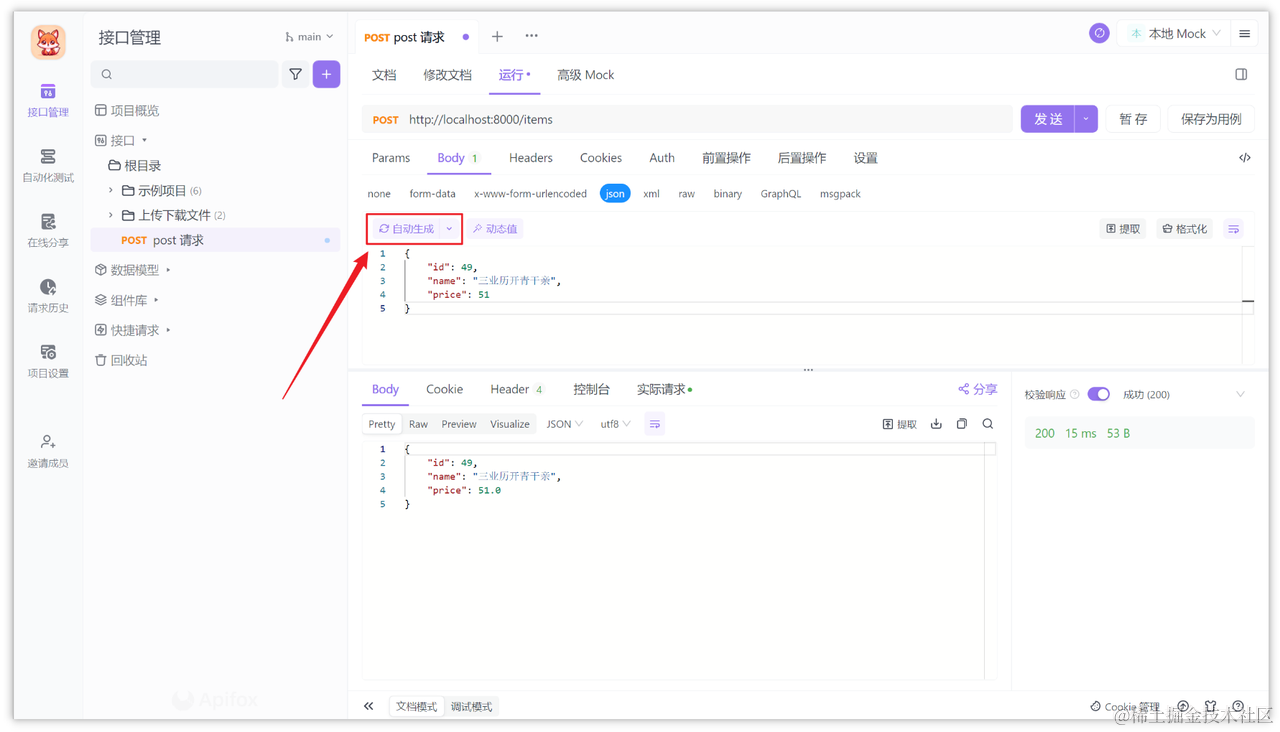
from transformers import SegformerFeatureExtractor
import PIL. Image
feature_extractor = SegformerFeatureExtractor( )
pixel_values = [ PIL. Image. new( 'RGB' , ( 200 , 100 ) , 'blue' ) , PIL. Image. new( 'RGB' , ( 200 , 100 ) , 'red' )
] value = [ PIL. Image. new( 'L' , ( 200 , 100 ) , 150 ) , PIL. Image. new( 'L' , ( 200 , 100 ) , 200 )
]
out = feature_extractor( pixel_values, value)
print ( 'keys=' , out. keys( ) )
print ( 'type=' , type ( out[ 'pixel_values' ] ) , type ( out[ 'labels' ] ) )
print ( 'len=' , len ( out[ 'pixel_values' ] ) , len ( out[ 'labels' ] ) )
print ( 'type0=' , type ( out[ 'pixel_values' ] [ 0 ] ) , type ( out[ 'labels' ] [ 0 ] ) )
print ( 'shape0=' , out[ 'pixel_values' ] [ 0 ] . shape, out[ 'labels' ] [ 0 ] . shape) feature_extractor
keys= dict_keys( [ 'pixel_values' , 'labels' ] )
type = < class 'list' > < class 'list' >
len = 2 2
type0= < class 'numpy.ndarray' > < class 'numpy.ndarray' >
shape0= ( 3 , 512 , 512 ) ( 512 , 512 )
SegformerFeatureExtractor { "do_normalize" : true, "do_resize" : true, "feature_extractor_type" : "SegformerFeatureExtractor" , "image_mean" : [ 0.485 , 0.456 , 0.406 ] , "image_std" : [ 0.229 , 0.224 , 0.225 ] , "reduce_labels" : false, "resample" : 2 , "size" : 512
}
from torchvision. transforms import ColorJitter
jitter = ColorJitter( brightness= 0.25 , contrast= 0.25 , saturation= 0.25 , hue= 0.1 ) print ( jitter) jitter( PIL. Image. new( 'RGB' , ( 200 , 100 ) , 'blue' ) )
ColorJitter( brightness= [ 0.75 , 1.25 ] , contrast= [ 0.75 , 1.25 ] , saturation= [ 0.75 , 1.25 ] , hue= [ - 0.1 , 0.1 ] )
from datasets import load_dataset, load_from_disk
dataset = load_dataset( path= 'segments/sidewalk-semantic' )
def transforms ( data) : pixel_values = data[ 'pixel_values' ] label = data[ 'label' ] pixel_values = [ jitter( i) for i in pixel_values] return feature_extractor( pixel_values, label)
dataset = dataset. shuffle( seed= 1 ) [ 'train' ] . train_test_split( test_size= 0.1 ) dataset[ 'train' ] = dataset[ 'train' ] . with_transform( transforms) print ( dataset[ 'train' ] [ 0 ] ) dataset
import torchdef collate_fn ( data) : pixel_values = [ i[ 'pixel_values' ] for i in data] labels = [ i[ 'labels' ] for i in data] pixel_values = torch. FloatTensor( pixel_values) labels = torch. LongTensor( labels) return { 'pixel_values' : pixel_values, 'labels' : labels} loader = torch. utils. data. DataLoader( dataset= dataset[ 'train' ] , batch_size= 4 , collate_fn= collate_fn, shuffle= True , drop_last= True ,
) for i, data in enumerate ( loader) : break len ( loader) , data[ 'pixel_values' ] . shape, data[ 'labels' ] . shape
torch. nn. functional. interpolate( torch. randn( 4 , 35 , 128 , 128 ) , size= ( 512 , 512 ) , mode= 'bilinear' , align_corners= False ) . shape
from transformers import SegformerForSemanticSegmentation, SegformerModel
class Model ( torch. nn. Module) : def __init__ ( self) : super ( ) . __init__( ) self. pretrained = SegformerModel. from_pretrained( 'nvidia/mit-b0' ) self. linears = torch. nn. ModuleList( [ torch. nn. Linear( 32 , 256 ) , torch. nn. Linear( 64 , 256 ) , torch. nn. Linear( 160 , 256 ) , torch. nn. Linear( 256 , 256 ) ] ) self. classifier = torch. nn. Sequential( torch. nn. Conv2d( in_channels= 1024 , out_channels= 256 , kernel_size= 1 , bias= False ) , torch. nn. BatchNorm2d( 256 ) , torch. nn. ReLU( ) , torch. nn. Dropout( 0.1 ) , torch. nn. Conv2d( 256 , 35 , kernel_size= 1 ) , ) parameters = SegformerForSemanticSegmentation. from_pretrained( 'nvidia/mit-b0' , num_labels= 35 ) for i in range ( 4 ) : self. linears[ i] . load_state_dict( parameters. decode_head. linear_c[ i] . proj. state_dict( ) ) self. classifier[ 0 ] . load_state_dict( parameters. decode_head. linear_fuse. state_dict( ) ) self. classifier[ 1 ] . load_state_dict( parameters. decode_head. batch_norm. state_dict( ) ) self. classifier[ 4 ] . load_state_dict( parameters. decode_head. classifier. state_dict( ) ) self. criterion = torch. nn. CrossEntropyLoss( ignore_index= 255 ) def forward ( self, pixel_values, labels) : features = self. pretrained( pixel_values= pixel_values, output_hidden_states= True ) features = features. hidden_statesfeatures = [ i. flatten( 2 ) for i in features] features = [ i. transpose( 1 , 2 ) for i in features] features = [ l( f) for f, l in zip ( features, self. linears) ] features = [ i. permute( 0 , 2 , 1 ) for i in features] features = [ f. reshape( pixel_values. shape[ 0 ] , - 1 , s, s) for f, s in zip ( features, [ 128 , 64 , 32 , 16 ] ) ] features = [ torch. nn. functional. interpolate( i, size= ( 128 , 128 ) , mode= 'bilinear' , align_corners= False ) for i in features] features = features[ : : - 1 ] features = torch. cat( features, dim= 1 ) features = self. classifier( features) loss = self. criterion( torch. nn. functional. interpolate( features, size= ( 512 , 512 ) , mode= 'bilinear' , align_corners= False ) , labels) return { 'loss' : loss, 'logits' : features} model = Model( )
print ( sum ( i. numel( ) for i in model. parameters( ) ) / 10000 ) out = model( ** data) out[ 'loss' ] , out[ 'logits' ] . shape
from datasets import load_metric
metric = load_metric( 'mean_iou' )
metric. compute( predictions= torch. ones( 4 , 10 , 10 ) , references= torch. ones( 4 , 10 , 10 ) , num_labels= 35 , ignore_index= 0 , reduce_labels= False )
from matplotlib import pyplot as pltdef show ( image, out, label) : plt. figure( figsize= ( 15 , 5 ) ) image = image. clone( ) image = image. permute( 1 , 2 , 0 ) image = image - image. min ( ) . item( ) image = image / image. max ( ) . item( ) image = image * 255 image = PIL. Image. fromarray( image. numpy( ) . astype( 'uint8' ) , mode= 'RGB' ) image = image. resize( ( 512 , 512 ) ) plt. subplot( 1 , 3 , 1 ) plt. imshow( image) plt. axis( 'off' ) out = PIL. Image. fromarray( out. numpy( ) . astype( 'uint8' ) ) plt. subplot( 1 , 3 , 2 ) plt. imshow( out) plt. axis( 'off' ) label = PIL. Image. fromarray( label. numpy( ) . astype( 'uint8' ) ) plt. subplot( 1 , 3 , 3 ) plt. imshow( label) plt. axis( 'off' ) plt. show( ) show( data[ 'pixel_values' ] [ 0 ] , torch. ones( 512 , 512 ) , data[ 'labels' ] [ 0 ] )
def test ( ) : model. eval ( ) dataset[ 'test' ] = dataset[ 'test' ] . shuffle( ) loader_test = torch. utils. data. DataLoader( dataset= dataset[ 'test' ] . with_transform( transforms) , batch_size= 8 , collate_fn= collate_fn, shuffle= False , drop_last= True , ) labels = [ ] outs = [ ] correct = 0 total = 1 for i, data in enumerate ( loader_test) : with torch. no_grad( ) : out = model( ** data) out = torch. nn. functional. interpolate( out[ 'logits' ] , size= ( 512 , 512 ) , mode= 'bilinear' , align_corners= False ) out = out. argmax( dim= 1 ) outs. append( out) label = data[ 'labels' ] labels. append( label) select = label != 0 correct += ( label[ select] == out[ select] ) . sum ( ) . item( ) total += len ( label[ select] ) if i % 1 == 0 : show( data[ 'pixel_values' ] [ 0 ] , out[ 0 ] , label[ 0 ] ) if i == 4 : break metric_out = metric. compute( predictions= torch. cat( outs, dim= 0 ) , references= torch. cat( labels, dim= 0 ) , num_labels= 35 , ignore_index= 0 ) metric_out. pop( 'per_category_iou' ) metric_out. pop( 'per_category_accuracy' ) print ( metric_out) print ( correct / total) test( )
from transformers import AdamW
from transformers. optimization import get_schedulerdef train ( ) : optimizer = AdamW( model. parameters( ) , lr= 5e-5 ) scheduler = get_scheduler( name= 'linear' , num_warmup_steps= 0 , num_training_steps= len ( loader) * 3 , optimizer= optimizer) model. train( ) for i, data in enumerate ( loader) : out = model( ** data) loss = out[ 'loss' ] loss. backward( ) torch. nn. utils. clip_grad_norm_( model. parameters( ) , 1.0 ) optimizer. step( ) scheduler. step( ) optimizer. zero_grad( ) model. zero_grad( ) if i % 10 == 0 : out = torch. nn. functional. interpolate( out[ 'logits' ] , size= ( 512 , 512 ) , mode= 'bilinear' , align_corners= False ) . argmax( dim= 1 ) label = data[ 'labels' ] metric_out = metric. compute( predictions= out, references= label, num_labels= 35 , ignore_index= 0 ) metric_out. pop( 'per_category_iou' ) metric_out. pop( 'per_category_accuracy' ) select = label != 0 label = label[ select] out = out[ select] accuracy = ( label == out) . sum ( ) . item( ) / ( len ( label) + 1 ) lr = optimizer. state_dict( ) [ 'param_groups' ] [ 0 ] [ 'lr' ] print ( i, loss. item( ) , lr, metric_out, accuracy) torch. save( model, 'models/9.抠图.model' ) train( )
model = torch. load( 'models/9.抠图.model' )
test( )