介绍
有时候需要在多个组间筛选它们的交集特征,本文利用R语言实现该目的
加载R包
library(UpSetR)
library(tidyverse)
Upset画图
movies <- read.csv(system.file("extdata", "movies.csv", package = "UpSetR"), header = T, sep = ";")
movies_list <- list(Action = movies %>%dplyr::filter(Action == 1) %>%dplyr::pull(Name),Adventure = movies %>%dplyr::filter(Adventure == 1) %>%dplyr::pull(Name),Children = movies %>%dplyr::filter(Children == 1) %>%dplyr::pull(Name),Comedy = movies %>%dplyr::filter(Comedy == 1) %>%dplyr::pull(Name),Crime = movies %>%dplyr::filter(Crime == 1) %>%dplyr::pull(Name),Documentary = movies %>%dplyr::filter(Documentary == 1) %>%dplyr::pull(Name)
)movies_pl <- UpSetR::upset(data = fromList(movies_list),nsets = 3, sets = c("Action", "Adventure", "Children", "Comedy", "Crime", "Documentary"),order.by = "freq",main.bar.color = "gray10",sets.bar.color = "gray",matrix.color = "gray10",mainbar.y.label = "NO. of movies",sets.x.label = "NO. of movies")movies_pl
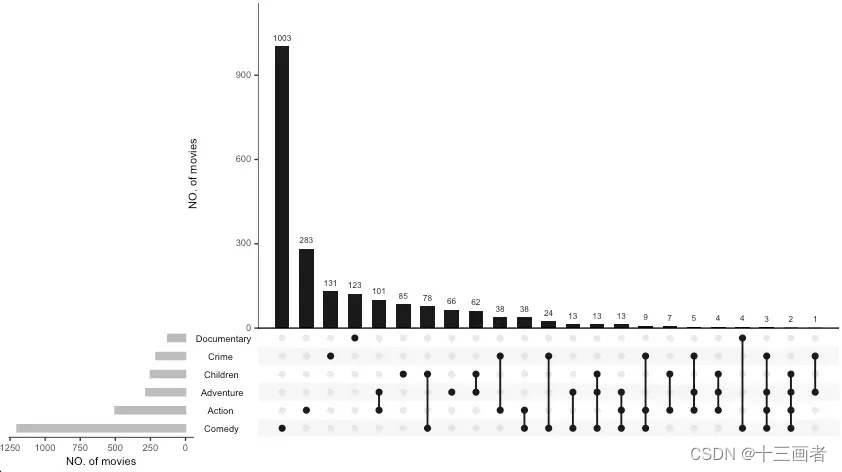
判断交集特征
-
去冗余变量 df_uniq_movie
-
分组变量标签 df_group_movie
df_uniq_movie <- data.frame(feature = unique(unlist(movies_list)))
df_group_movie <- lapply(movies_list, function(x){data.frame(feature = x)
}) %>% dplyr::bind_rows(.id = "Sequence")
- 给变量打上交集标签
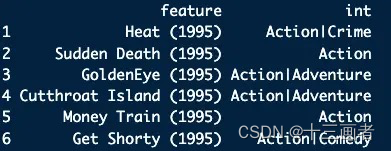
df_int_movie <- lapply(df_uniq_movie$feature, function(x){intersection <- df_group_movie %>% dplyr::filter(feature == x) %>% dplyr::arrange(Sequence) %>% dplyr::pull(Sequence) %>% paste0(collapse = "|")# build the dataframereturn(data.frame(feature = x, int = intersection))
}) %>% dplyr::bind_rows()head(df_int_movie)