-
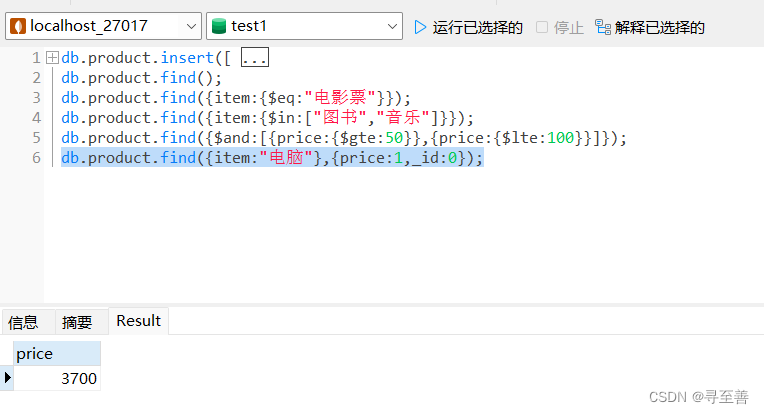
共享代理,打开允许局域网
-
打开clash的allow LAN
-
查看mac的以太网的ip地址(mac在局域网中的ip)
-
修改下面命令中的ip,粘贴到服务器的终端中即可
-
终端是否代理
curl ipinfo.io
-
export https_proxy=http://10.15.223.121:7890;
export http_proxy=http://10.15.223.121:7890;
export all_proxy=socks5://10.15.223.121:7890;
- bin加载,放在最开始,优先加载
export PATH=/home/user-ana/software/git-2.42/bin:$PATH
- 查看大小
du -sh 目录的路径
- venv激活环境,进入其中的bin目录
source activate
- Pycharm 缩进
同时按住 Shift + Tab 键
- 删除文件夹
rm -rf folder
- 查看端口占用
lsof -i tcp:port
- 端口转发
ssh -L 127.0.0.1:16006 : 127.0.0.1:6006 user-ana@10.255.248.48ssh -L 16006 : 127.0.0.1:6006 user-ana@10.255.248.48
- pytorch下载
官网
# CUDA 11.7
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia#
# CUDA 11.7
conda install pytorch==2.0.1 torchvision==0.15.2 pytorch-cuda=11.7 -c pytorch -c nvidia
sudo adduser tom
sudo useradd -m tom
# conda 更新
WARNING: A newer version of conda exists. <== current version: 23.3.1 latest version: 23.10.0
Please update conda by running conda update -n base -c conda-forge conda
Or to minimize the number of packages updated during conda update use conda install conda=23.10.0
- 设置超时上限时间
conda config --set remote_read_timeout_secs 600.0
- 删除环境
conda remove -n env_name --all
- $前面消失,shell的问题,切换为bash就行
- 用户无法删除,被进程占用,根本原因在于切换回其他用户之后,要被删除的用户还被某个进程占用,手动关闭终端后,重新打开
- 修改用户的附加组
sudo usermod -G wheel
# 切换用户
su -l user
- 取消自动激活base
conda config --set auto_activate_base false
- vim删除
Ctrl+u 删除命令行开始至光标处Ctrl+k 删除光标至命令行结尾Ctrl+a 光标移到最前Ctrl+e 光标移到最后
- 查看linux版本
hostnamectl
- 查看虚拟环境
conda info --envs
- 导出环境
conda env export > xxx.yaml
- 根据已有环境创建
conda env create -f xxx.yaml
- conda 更换源,清华源
# 添加Anaconda镜像
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/clouddeepmodeling: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/
auto_activate_base: false
show_channel_urls: true# --add 每一次add添加的源优先级变得最高-
在
.condarc文件中直接修改源 -
查看源
conda config --show channels
- 查看所有已创建的虚拟环境
conda env list
- 查看命令的位置
# 显示位置和帮助手册
whereis command_name
# 只显示位置
which command_name
pip show packname #显示包的安装位置等信息
损失函数-针对单个训练样本
代价函数-针对整个训练集,衡量w和b的学习效果
用梯度下降法在整个训练集上来学习或训练w和b
0、空字符串、空列表、空元组等被视为 False
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。元组中的元素类型也可以不相同,其实,可以把字符串看作一种特殊的元组。元组用(),字符串用"",元组用逗号分割,字符串无明显分割符。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
- **不可变类型:**类似 C++ 的值传递,如整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象。
- **可变类型:**类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
输入通道数是指输入图像中的颜色通道数或信息通道数。对于灰度图像,通常只包含一个单一的亮度通道,因此其通道数为1。这是因为灰度图像中的每个像素只包含亮度信息,而不包含颜色信息。
通常,彩色图像是由红色(R)、绿色(G)、蓝色(B)等不同颜色通道组成的,每个通道包含不同颜色信息。因此,彩色图像通常具有多个通道,例如RGB图像具有3个通道,而RGBA图像还包含了一个透明度通道,具有4个通道。
对于深度学习模型,通道数是一个重要的参数,因为它决定了每个像素点的特征信息的维度。在卷积神经网络(CNN)中,卷积核的数量通常与输入图像的通道数相对应,卷积核在每个通道上分别执行卷积操作,从而提取不同通道的特征信息。
因此,对于灰度图像,通常将其视为单通道图像,只有一个亮度通道。而对于彩色图像,通常将其视为多通道图像,每个颜色通道分别包含颜色信息。通道数的选择取决于图像的性质和任务需求,但通常在深度学习中使用的图像是灰度图像或RGB彩色图像。
torch.nn.Conv2d二维卷积层可以处理多通道的输入数据,例如彩色图像的三个通道
全连接一般会把卷积输出的二维特征图转化成一维的一个向量
全连接层的主要参数有权重矩阵W和偏置向量b
如何缓解全连接层的过拟合问题?
答:可以采用dropout、权重衰减等方法来缓解全连接层的过拟合问题
to(device) 方法返回一个新的张量,这个张量是原始张量的副本,但被移动到了指定的设备上。原始张量保持不变,不会发生就地移动。这是一个创建新张量的操作,新张量存储在指定的设备上。
例如,如果你有一个在 CPU 上的张量 x,并使用 y = x.to(device) 将其移动到 GPU 上,那么 x 保持在 CPU 上,而 y 是一个新的张量,它的数据存储在 GPU 上。你可以通过 y.device 属性来检查 y 所在的设备。
这种方法的使用方式允许你在不影响原始数据的情况下,在不同的设备上执行计算,非常灵活。同时,它还允许你在需要时切换计算设备,以充分利用 GPU 等硬件加速。
注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
使用 from Package import specific_submodule 这种方法永远不会有错
DataLoader 封装了数据加载和迭代的逻辑。您只需为它提供数据集、批处理大小和其他选项,然后就可以使用 for 循环来迭代数据集,每次迭代返回一个批次的数据。
model.train()方法通常在训练卷积神经网络(CNN)或包含需要不同行为的层时使用。在CNN中,BatchNormalization和Dropout等层在训练和推理模式下有不同的行为,因此需要使用model.train()和model.eval()来切换它们的模式。
对于您提供的前馈神经网络,您可以不使用model.train(),因为它的结构不包含需要在训练和推理之间切换的层
len(data_loader) 计算了数据加载器 data_loader 中的批次数量,也就是你的训练数据集中样本的总数除以每个批次的样本数