
题图:芝加哥大学海德公园。芝大是经济学重镇,其学者开创了著名的芝加哥经济学派,共产生了 100 位诺奖、10 位菲尔兹奖、4 位图灵奖。今天量化人追逐的 Alpha, 最早就来自于 Michael Jessen 在芝大时的博士论文。
很多人对基于机器学习的量化策略很好奇,常常问什么时候有机器学习的课。其实,对很多人(我自己就是)来说,没有能力改进机器学习的算法和框架,机器学习都是作为黑盒子来学习,难度主要是卡在训练数据上。
这篇文章,将介绍一种数据标注方法和工具。
有监督的机器学习需要标注数据。标注数据一般是一个二维矩阵,其中一列是标签(一般记为 y),其它列是特征(一般记为 X)。训练的过程就是:
$$
fit(x) = WX -> y’ \approx y
$$
训练就是通过反向传播来调整权重矩阵 W W W,使之得到的 y ′ y' y′最接近于 y y y。
特征矩阵并不困难。它可以是因子在某个时间点上的取值。但如何标注是一个难题。它实际上反应的是,你如何理解因子与标签之间的逻辑关系:因子究竟是能预测标的未来的价格呢,还是可以预测它未来价格的走势?
应该如何标注数据
前几年有一篇比较火的论文,使用 LSTM 来预测股价。我了解到的一些人工智能与金融结合的硕士专业,还把类似的题目布置给学生练习。
作为练习题无可厚非,但也应该讲清楚,使用 LSTM 来预测股价的荒谬之处:你无法利用充满噪声的时序金融数据,从价格直接推导出下一个价格。
坊间还流传另一个方法,既然数据与标签之间不是逻辑回归的关系,那么我们把标签离散化,使之转换成为一个分类问题。比如,按第二天的涨跌,大于 3%的,归类为大幅上涨;涨跌在 1%到 3%的,归类为小幅上涨。在-1%到 1%的,归类为方向不明。
其实这种方法背后的逻辑仍然是逻辑回归。而且,为什么上涨 2.99%是小幅上涨,上涨 3%就是大幅上涨呢?有人就提出改进方法,在每个类之间加上 gap,即 [-0.5%, 0.5%] 为方向不明,[1%,3%] 为小幅上涨,而处在 [0.5%, 1%] 之间的数据就丢掉,不进行训练。这些技巧在其它领域有时候是有效的,但在量化领域,我认为它仍然不够好。因为原理不对。
我们应该回归问题的本质。要判断每一天的涨跌,其实是有难度的。但如果要判断一段趋势是否结束,则相对来讲,特征会多一点,偶然性会低一点。用数学语言来讲,我们可以把一段 k 线中的顶点标注为 1,底部标注为-1,中间的部分都标注为 0。每一个峰都会有一个谷对应,但中间的点会显著多一些,数据分类不够平衡。在训练时,要做到数据分类平衡,把标签为 0 的部分少取一点即可。
顶底数据的标注
鉴于上面的思考,我做了一个小工具,用来标注行情数据的顶和底。
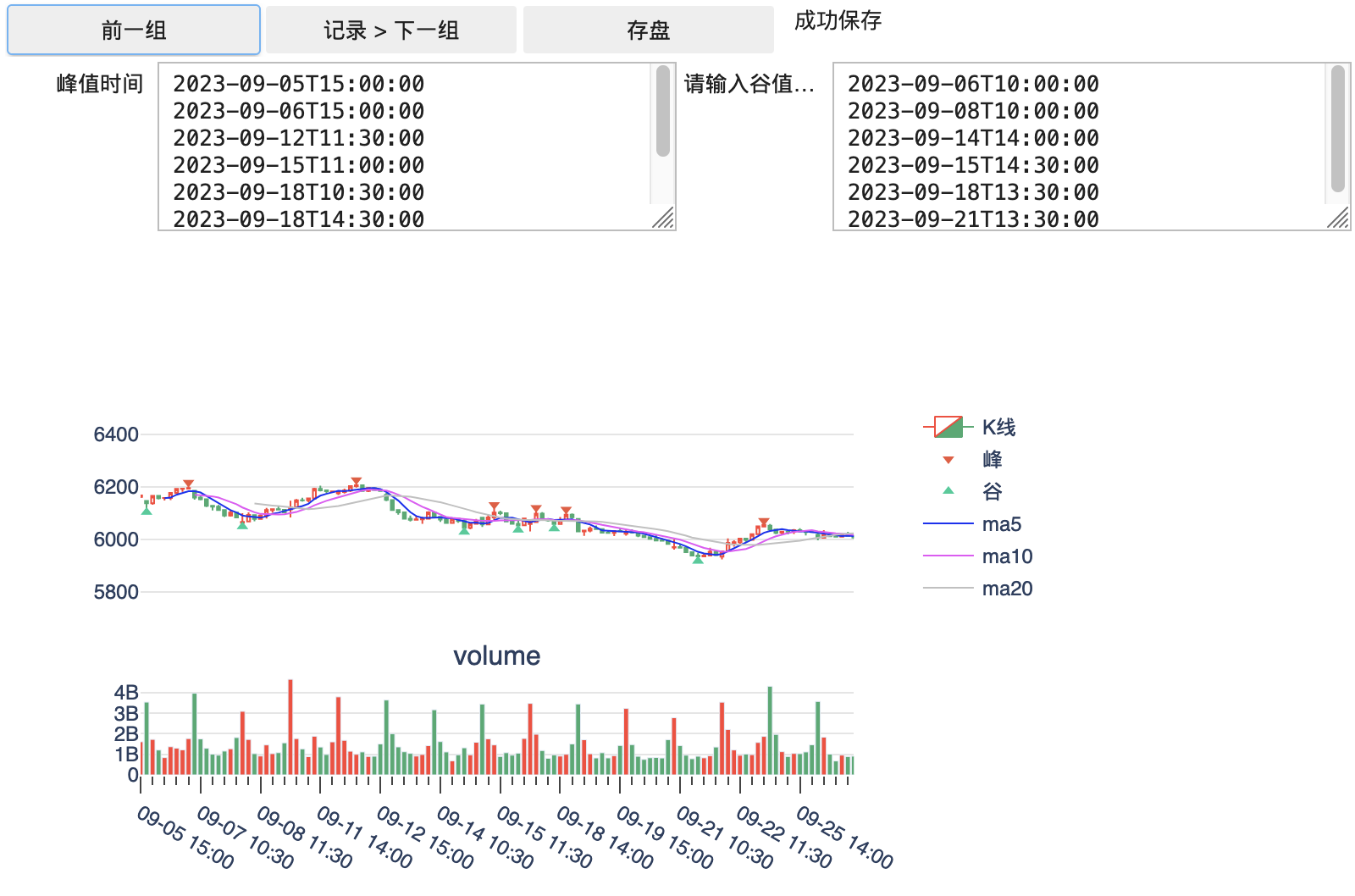
这个工具要实现的任务是:
- 加载一段行情数据,绘制 k 线图
- 自动识别这段 k 线中的的顶和底,并在图上标记出来
- 把这些顶和底的时间提取出来,放到峰和谷两个编辑框中,供人工纠错
- 数据校准后,点击“记录 > 下一组"来标注下一段数据
我们使用 zigzag 库来自动寻找 k 线中的顶和底。相比 scipy.signals 包中的 argrelextrema 和 find_peaks 等方法,zigzag 库中的 peaks_valleys_pivot 方法更适合股价数据 – 像 find_peaks 这样的方法,要求的数据质量太高了,金融数据的噪声远远超过它的期待。
peaks_valleys_pivot 会自动把首尾的部分也标记成为峰或者谷 – 这在很多时候会是错误的 – 因为行情还没走完,尾部的标记还没有固定下来。因此,我们需要手动移除这部分标记。此外,偶尔会发现峰谷标记太密的情况 – 一般是由于股价波动太厉害,但如果很快得到修复,我们也可以不标记这一部分。这也需要我们手动移除。
最终,我们将行情数据的 OHLC、成交量等数据与顶底标记一起保存起来。最终,我们将得到类似下面的数据:
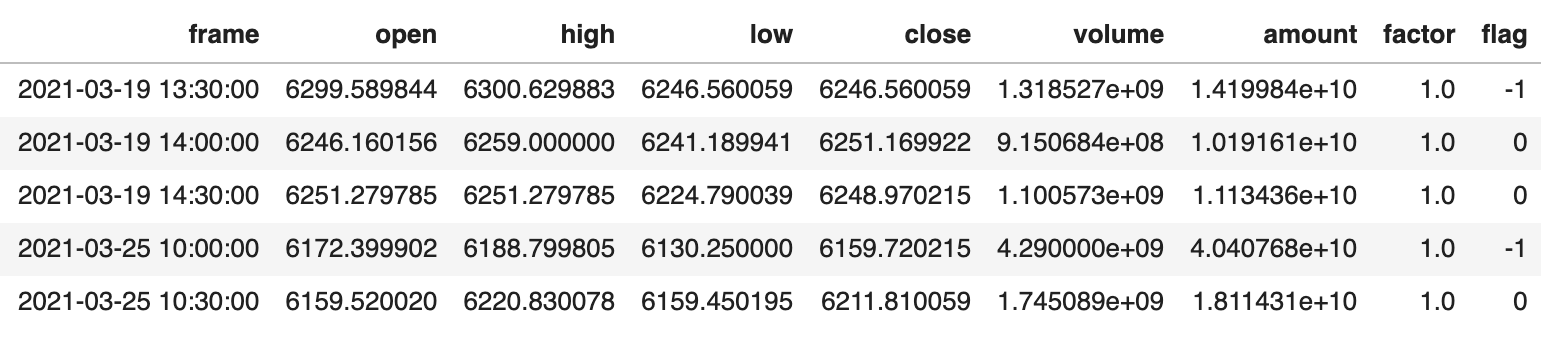
当然,它只能作为我们训练数据的一个底稿。我们说过,不能直接使用价格数据作为训练数据。我们必须从中提取特征。显然,像 RSI 这样的反转类指标是比较好的特征。
另外,冲高回落、均线切线斜率变化(由正转负意味着见顶,反之意味着见底)、两次冲击高点不过、k 线 pattern 中的早晨之星、黄昏之星(如果你将它们的 k 线进行 resample, 实际上它是一个冲高回落过程,或者说长上影、长下影)等等都是有一定指示性的特征。
标注工具构建方法
!!! tip
这里我们介绍的是 jupyter 的 ipywidgets 来构建界面的方法。此外,Plotly Dash, streamlit, H2O wave 也是主要为此目标设计的工具。
为了在 notebook 中使用界面元素,我们需要先导入相关的控件:
from ipywidgets import Button, HBox, VBox, Textarea, Layout,Output, Boxfrom IPython.display import display
在一个单元格中,如果最后的输出是一个对象,那么 notebook 将会直接显示这个对象。如果我们要在一个单元格中显示多个对象,或者,在中间的代码中要显示一些对象,就需要用到 display 这个方法。这是我们上面代码引入 display 的原因。
这里我们引入了 HBox, VBox 和 Box 三个容器类控件,Button, TextArea 这样的功能性控件。
Layout 用来指定控件的样式,比如要指定一个峰值时刻输入框的宽度和高度:
peaks_box = Textarea(value='',placeholder='请输入峰值时间,每行一个',description='峰值时间',layout=Layout(width='40%',height='100px')
)
按钮类控件一般需要指定点击时执行的动作,我们通过 on_click 方法,将点击事件和一个事件处理方法相绑定:
save_button = Button(description='存盘'
)
save_button.on_click(save)def save(c):# SAVE DATA TO DISKpass
这里要注意的是,事件响应函数(比如这里的 save),在函数签名上一定要带一个参数。否则,当按钮被点击时,事件就无法传导到这个函数中来,并且不会有任何错误提示。
HBox, VBox 用来将子控件按行、列进行排列。比如:
# K 线图的父容器
figbox = Box(layout=Layout(width="100%"))
inputs = HBox((peaks_box, valleys_box))
buttons = HBox((backward_button, keep_button, save_button, info))
display(VBox((buttons, inputs, figbox)))
Output 控件是比较特殊的一个控件。如果我们在事件响应函数中进行了打印,这些打印是无法像其它单元格中的打印那样,直接输出在单元格下方的。我们必须定义一个 Output 控制,打印的消息将会捕获,并显示在 Output 控件的显示区域中。
info = Output(layout=Layout(width="40%"))def save(c):global info# DO THE SAVE JOBwith info:print("数据已保存到磁盘!")
与此类似,plotly 绘制的 k 线图,也不能直接显示。我们要通过 go.FigureWidget 来显示 k 线图。
import plotly.graph_objects as gofigure = ... # draw the candlestick with bars
fig = go.FigureWidget(figure)
figbox.children = (fig, )
我们特别给出这段代码,是要展示更换 k 线图的方法。在初始化时,我们就必须把 figbox 与其它控件一起安排好,但如何更新 figbox 的内容呢?
答案是,让 figbox 成为一个容器,而 go.FigureWidget 成为它的一个子控件。每次要更新 k 线图时,我们生成一个新的 fig 对象,通过figbox.children = (fig, )来替换它。
最后,谈一点 troubleshooting 的方法。所有通过 on_click 方法绑定的事件函数,即使在运行中出了错,也不会有任何提示。因此,我们需要自己捕获错误,再通过 Output 控件来显示错误堆栈:
def log(msg):global infoinfo.clear_output()with info:if isinstance(msg, Exception):traceback.print_exc(msg)else:print(msg)def on_save(b):try:# DO SOMETHING MAY CAUSE CHAOSraise ValueError()except Exception as e:log(e)info = Output(layout = Layout(...))
save_button = Button()
save_button.on_click(on_save)
利用这款工具,大概花了两小时,最终我得到了2万条数据,其中顶底标签约1600个。



![[Qt网络编程]之获取基本网络信息](https://img-blog.csdnimg.cn/direct/d137a71f4e25403ebd91bb9c161a1b7c.png)