参考6.6. 卷积神经网络(LeNet) — 动手学深度学习 2.0.0 documentation (d2l.ai)
ps:在这里预备使用pythorch
1.对 LeNet 的初步认识
总的来看,LeNet主要分为两个部分:
-
卷积编码器:由两个卷积层组成;
-
全连接层密集块:由三个全连接层组成。
 每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。
每个卷积层使用5×5卷积核和一个sigmoid激活函数。
这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个2×2池操作(步幅2)通过空间下采样将维数减少4倍。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。
代码
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))读代码
nn.Sequential:创建一个顺序容器,模型中的层将按照在构造函数中传递的顺序依次应用于输入。nn.Conv2d:2D卷积层,第一个参数是输入通道数,第二个参数是输出通道数,kernel_size是卷积核大小,padding表示在输入的每一边填充0的层数。nn.Sigmoid:Sigmoid激活函数,用于引入非线性。nn.AvgPool2d:2D平均池化层,用于减少特征图的空间尺寸。nn.Flatten:将多维张量展平为一维。nn.Linear:全连接层,第一个参数是输入特征数,第二个参数是输出特征数。- 在这个模型中,经过两个卷积层和池化层后,特征图被展平为一维,然后经过三个全连接层进行分类,输出10个类别的概率。

X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape)在整个卷积块中,与上一层相比,每一层特征的高度和宽度都减小了。 第一个卷积层使用2个像素的填充,来补偿5×5卷积核导致的特征减少。 相反,第二个卷积层没有填充,因此高度和宽度都减少了4个像素。 随着层叠的上升,通道的数量从输入时的1个,增加到第一个卷积层之后的6个,再到第二个卷积层之后的16个。 同时,每个汇聚层的高度和宽度都减半。最后,每个全连接层减少维数,最终输出一个维数与结果分类数相匹配的输出。
2.模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)def evaluate_accuracy_gpu(net, data_iter, device=None): #@save"""使用GPU计算模型在数据集上的精度"""if isinstance(net, nn.Module):net.eval() # 设置为评估模式if not device:device = next(iter(net.parameters())).device# 正确预测的数量,总预测的数量metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# BERT微调所需的(之后将介绍)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')训练和评估LeNet-5模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())接下来是一部分的实验报告
卷积网络在Fashion_MNIST数据集上的分类
1.实验目的
本次实验的目的是配置pythorch环境,熟悉卷积神经网络,实现对Fashion_MNIST数据集的分类。
2.实验环境
Python 3.10.9
torch-2.2.2
torchvision-0.17.2
3.项目内容(作业任务、算法原理)
3.1作业任务
使用卷积神经网络完成对fashion_mnist数据集的分类,在本次实验中使用经典的LeNet-5网络进行分类任务。
3.2数据集
本次实验所使用的数据集为 Fashion_MNIST。它包含了来自 Zalando 研究的70,000张灰度图像,涵盖了10个类别的衣服和配件,每个类别有 7,000 张图像。每张图像的分辨率为 28×28 像素并且图像被预处理和标准化,像素值范围在 0 到 255 之间,并已归一化到范围 [0, 1] 内。
3.3 算法原理
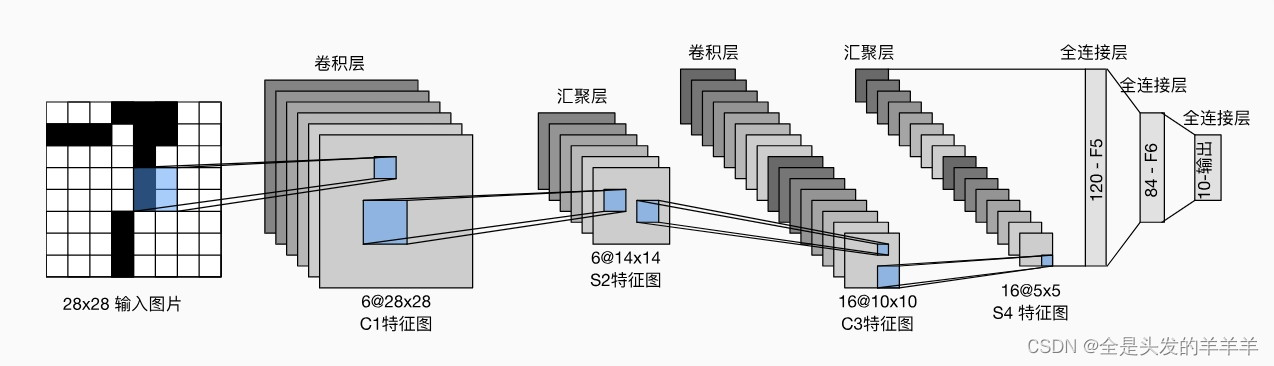
本次实验选用的是经典的卷积神经网络LeNet-5。LeNet-5是由Yann LeCun等人于1998年提出的一种经典的卷积神经网络模型,最初用于手写数字识别任务。它是最早的深度学习模型之一,对于推动卷积神经网络的发展具有重要意义。LeNet-5 包含了卷积层、池化层和全连接层,具体架构如下:
·卷积层:6个卷积核(大小为 5×5)
·池化层:2×2 大小的最大池化
·卷积层:16个卷积核大小为 5×5
·池化层:2×2 大小的最大池化
·全连接层:第一个全连接层包含 120 个神经元
·全连接层:第二个全连接层包含 84 个神经元
·输出层:10个神经元(对应10个类别)

图 1 LeNet-5 架构图
3.4 核心代码
class LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()#6个5×5的卷积核,填充为2,步幅为1self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)#池化层self.conv2 = nn.Conv2d(6, 16, 5)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = nn.Linear(16 * 5 * 5, 120)#全连接层self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return F.log_softmax(x, dim=1)4.实验结果及结果分析
4.1数据集及评估方法
数据集: Fashion_MNIST
训练集大小: 60000
测试集大小: 10000
评估方法: 使用测试集计算模型的平均损失和准确率。
4.2模型对比(表格、结果展示截图等)
实验过程中发现模型训练后的准确率有点不尽人意,于是我尝试调整一些参数,对比了三个模型。
| 模型1 | 模型2 | 模型3 | |
| 训练集大小 | 60000 | 60000 | 60000 |
| 测试集大小 | 10000 | 10000 | 10000 |
| 训练批量大小 | 100 | 256 | 256 |
| 测试批量大小 | 100 | 256 | 256 |
| 学习率 | 0.01 | 0.01 | 0.01 |
| 学习率衰减因子 | 0.7 | 0.7 | 0.7 |
| 训练周期数 | 14 | 14 | 14 |
| 优化器 | SGD | Adam | Adam |
| 其他 | / | 添加了L2正则项 | 添加了L2正则项、Dropout层 |
| 模型准确率 | 80% | 90% | 90% |
模型4的模型架构代码如下


图 2 训练集和测试集的损失收敛情况(模型1
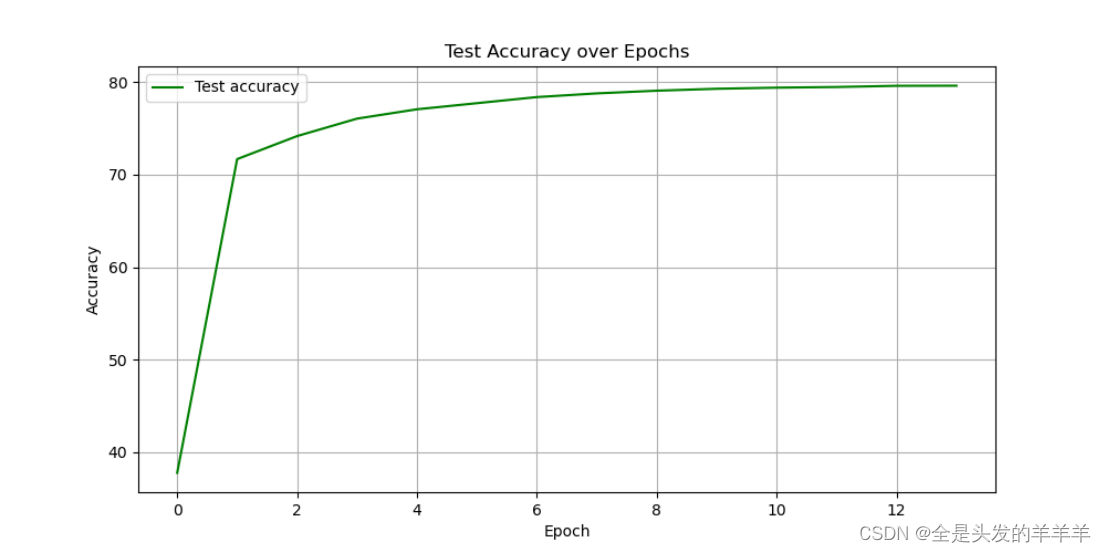
图 3 测试集的准确率(模型1

图 4 14个epochs后的准确率(模型1
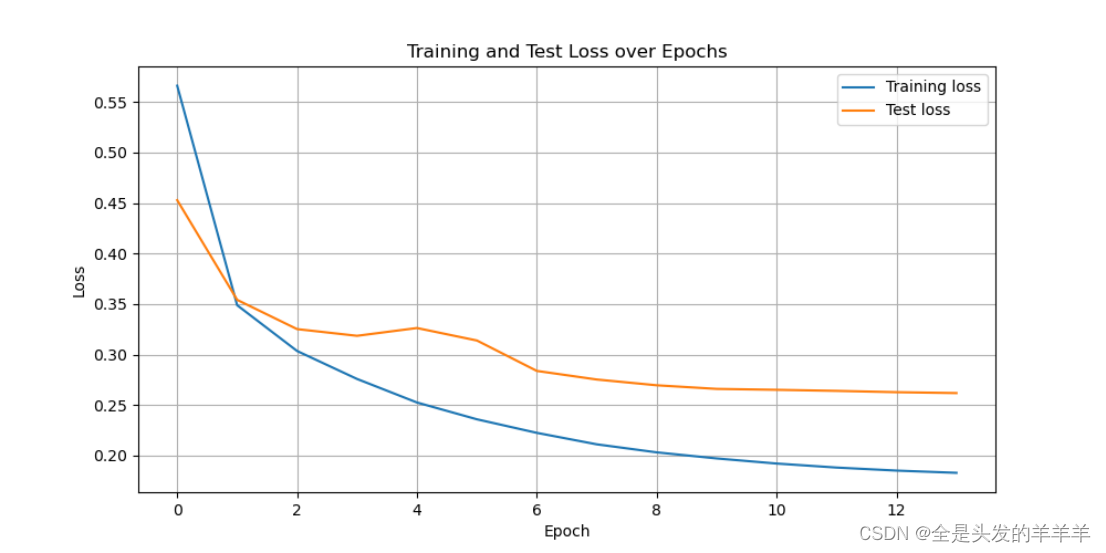
图 5 训练集和测试集的损失收敛情况(模型2

图 6 测试集的准确率(模型2

图 7 14个epochs后的准确率(模型2
从模型2的训练集和测试集的损失收敛情况可以看出,模型在训练集的效果明显好于测试集,由此我们可以看出模型出现了过拟合的情况,由于没有办法增加数据集的数量,于是在模型3中我在模型中添加了Dropout层以防止过拟合。

图 8 训练集和测试集的损失收敛情况(模型3

图 9 测试集的准确率(模型3

图 10 14个epochs后的准确率(模型3
可以看到的是过拟合情况得到了缓解,但是准确率并没有提高,于是我尝试修改模型的架构。
图 11 14个epochs后的准确率(模型4
可以看到的是修改后的模型的准确率并没有提高,于是我上网查找原因,发现在用卷积网络进行fashion_MNIST数据集进行分类的时候,90%的准确率已经是挺高的了,也就是说模型2和模型3已经得到我们想要的效果了。
在模型4中我们增加了卷积核的数量却反而导致我们模型的准确率降低了,经过了解我得知增加卷积核数量可能导致模型的复杂度增加,进而需要更多的参数来学习数据集的特征。这可能会增加过拟合的风险,尤其是当训练数据集较小或者特征较简单时。在某些情况下,增加卷积核数量会引入过多的噪声,导致模型性能下降。

图 12 模型预测结果可视化
5.实验总结
本次实验旨在探索卷积神经网络在Fashion_MNIST数据集上的应用,以经典的LeNet-5模型为基础进行分类任务。在实验过程中,我逐步优化了模型架构,并对比了不同模型的性能表现,以达到更好的分类准确率。
首先,Fashion_MNIST数据集包含10个类别的衣物和配饰图像,每个类别包含7000张28x28像素的灰度图像。我采用了LeNet-5模型作为初始模型架构,该模型包含了卷积层、池化层和全连接层,经典简洁。
随后,在训练过程中我注意到模型的性能不尽如人意,于是尝试了调整参数和模型架构。我对比了三个不同的模型,包括了对卷积核数量、全连接层节点数量以及添加正则化和Dropout层等方面的调整。通过实验结果的对比,我发现模型2和模型3在经过一定的调优后,已经达到了我期望的90%的准确率,表现出良好的性能。
此外,我还注意到了模型4中增加卷积核数量后导致性能下降的情况。经过分析得知,增加卷积核数量可能会增加模型复杂度,导致过拟合的风险增加。这一观察对我更好地理解模型性能和参数调优提供了重要启示。
最后,我通过可视化预测结果对模型的分类效果进行了直观展示,从而进一步加深了对模型性能的理解。总的来说,本次实验不仅加深了我对卷积神经网络在图像分类任务中的应用理解,也为我后续对模型性能优化提供了有益的参考。
6.附录(代码
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import matplotlib.pyplot as plt
import numpy as np#程序中链接了多个 OpenMP 运行时库的副本
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"import torch.nn.functional as Fclass LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(6, 16, 5)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)self.dropout = nn.Dropout(0.5) # 添加Dropout层,丢弃概率为0.5def forward(self, x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = self.dropout(x) # 在第一个全连接层后应用Dropoutx = F.relu(self.fc2(x))x = self.dropout(x) # 在第二个全连接层后应用Dropoutx = self.fc3(x)return F.log_softmax(x, dim=1)def train(args, model, device, train_loader, optimizer, epoch):model.train()epoch_train_losses = [] # 用于保存每个epoch的训练损失for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % args.log_interval == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))if args.dry_run:breakepoch_train_losses.append(loss.item()) # 将每个batch的损失保存下来return epoch_train_lossesdef test(model, device, test_loader):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, reduction='sum').item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)test_accuracy = 100. * correct / len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset), test_accuracy))return test_loss, test_accuracydef plot_loss(train_losses, test_losses):averaged_train_losses = [np.mean(epoch_losses) for epoch_losses in train_losses] # 取每个epoch的平均训练损失plt.figure(figsize=(10,5))plt.plot(averaged_train_losses, label='Training loss')plt.plot(test_losses, label='Test loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('Training and Test Loss over Epochs')plt.legend()plt.grid(True)plt.show()def plot_accuracy(test_accuracies):plt.figure(figsize=(10,5))plt.plot(test_accuracies, label='Test accuracy', color='green')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.title('Test Accuracy over Epochs')plt.legend()plt.grid(True)plt.show()def main():parser = argparse.ArgumentParser(description='PyTorch FashionMNIST Example')parser.add_argument('--batch-size', type=int, default=256, metavar='N',help='input batch size for training (default: 256)')parser.add_argument('--test-batch-size', type=int, default=256, metavar='N', # 设置测试集批量大小与训练集相同help='input batch size for testing (default: 256)')parser.add_argument('--epochs', type=int, default=14, metavar='N',help='number of epochs to train (default: 14)')parser.add_argument('--lr', type=float, default=0.01, metavar='LR',help='learning rate (default: 0.01)')parser.add_argument('--gamma', type=float, default=0.7, metavar='M',help='Learning rate step gamma (default: 0.7)')parser.add_argument('--no-cuda', action='store_true', default=True,help='disables CUDA training')parser.add_argument('--dry-run', action='store_true', default=False,help='quickly check a single pass')parser.add_argument('--seed', type=int, default=1, metavar='S',help='random seed (default: 1)')parser.add_argument('--log-interval', type=int, default=10, metavar='N',help='how many batches to wait before logging training status')parser.add_argument('--save-model', action='store_true', default=False,help='For Saving the current Model')args = parser.parse_args()use_cuda = not args.no_cuda and torch.cuda.is_available()torch.manual_seed(args.seed)device = torch.device("cuda" if use_cuda else "cpu")train_kwargs = {'batch_size': args.batch_size}test_kwargs = {'batch_size': args.test_batch_size}if use_cuda:cuda_kwargs = {'num_workers': 1,'pin_memory': True,'shuffle': True}train_kwargs.update(cuda_kwargs)test_kwargs.update(cuda_kwargs)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])train_dataset = datasets.FashionMNIST('./data', train=True, download=True, transform=transform)test_dataset = datasets.FashionMNIST('./data', train=False, download=True, transform=transform)train_loader = torch.utils.data.DataLoader(train_dataset, **train_kwargs)test_loader = torch.utils.data.DataLoader(test_dataset, **test_kwargs)model = LeNet5().to(device)optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=0.001)scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)train_losses = []test_losses = []test_accuracies = []for epoch in range(1, args.epochs + 1):train_loss = train(args, model, device, train_loader, optimizer, epoch)train_losses.append(train_loss)test_loss, test_accuracy = test(model, device, test_loader)test_losses.append(test_loss)test_accuracies.append(test_accuracy)scheduler.step()if args.save_model:torch.save(model.state_dict(), "fashion_mnist_lenet5.pt")plot_loss(train_losses, test_losses)plot_accuracy(test_accuracies)if __name__ == '__main__':main()