目录
安全开发专栏
前言
whois查询
子域名
子域名爆破
1.4 whois查询
方式1:
方式2:
1.5 子域名查询
方式1:子域名爆破
1.5.1 One
1.5.2 Two
方式2:其他方式
总结
安全开发专栏
安全开发实战![]() http://t.csdnimg.cn/25N7H
http://t.csdnimg.cn/25N7H
前言
whois查询
Whois 查询是一种用于获取有关互联网域名注册信息的公共查询服务。当注册一个域名时,必须提供一些个人或组织信息,例如姓名、电子邮件地址、联系电话等。这些信息通常是公开的,可以通过 Whois 查询来获取。
在渗透测试中,Whois 查询可以我们收集目标组织的关键信息。通过查询目标组织的域名注册信息,我们基本可以获得以下信息:
组织联系信息:包括名称、地址、电话号码和电子邮件地址。这些信息可以用于建立联系、进行社会工程攻击或者其他类型的攻击。
域名到期日期:了解域名何时到期可以帮助我们预测目标可能面临的安全风险。例如,如果域名即将到期,组织可能会忽略一些安全措施,使其易受攻击。
DNS 服务器信息:这些信息可以揭示目标使用的 DNS 提供商,有时甚至可以提供与该组织相关的其他域名。
域名所有者历史记录:通过查看域名所有者的历史记录,我们可以了解组织背后的变化、合作伙伴关系或其他潜在的信息。
总的来说:我们可以将这些信息用于制定针对目标组织的更有针对性的攻击策略,或者作为侦察阶段的一部分,以帮助了解目标环境。
子域名
子域名是指在一个域名下面的更小的域名。通常,一个域名可以有多个子域名,每个子域名都可以有自己的主机或服务。例如,在域名example.com下,可以有子域名如www.example.com、mail.example.com等,其实就是前面的信息在换。
子域名爆破
子域名爆破是一种渗透测试技术,旨在通过尝试各种可能的子域名来发现目标域名下存在的子域名。我们可以使用自动化工具或脚本来进行子域名爆破,工具通常会生成可能的子域名列表,并尝试通过DNS查询确定哪些子域名是有效的。
在渗透测试中,子域名爆破可以帮助我们发现目标可能忽略或未公开的子域名。这些子域名可能包含敏感信息、测试环境、未经授权的服务或其他潜在的安全风险。通过发现这些子域名,我们可以扩大对目标组织的攻击面,并进一步进行深入的渗透测试活动。
1.4 whois查询
方式1:
利用python第三方库python-whois查询,没有这个库,需要安装一下
pip install python-whois这个没什么技术含量,直接导入库进行利用就好了,可以看出返回了很多信息,当然,渗透中关注的是其中的获取到域名注册者的联系方式、注册时间、DNS服务器信息等,需要从这个获取的信息中进行提取关键信息即可,有时间将其完善一下.
from whois import whois
data = whois('www.baidu.com')
print(data)
方式2:
通过爬虫将一些查询whois的网站(阿里,爱站)爬取下来,这里因为要写针对某个网站的爬取,还是比较麻烦的,不如使用现成的浏览器插件superSearchPlus工具效率更快,就不写了.
1.5 子域名查询
方式1:子域名爆破
为什么要进行子域名爆破,使用第三方工具或是在线查询不是很好吗,作为一个渗透人员,要尽量避开大家都在使用的工具和字典,那么子域名爆破是最后也是当下最好的方式了,资产测绘平台也有查询不到的资产(未收录),当然也可以使用子域名爆破工具,都是可以的,唯一点就是建立自己的爆破字典,能够获取别人获取不到的资产.
1.5.1 One
利用原理,是通过将字典中的字符读取出来,然后与主域名进行拼接,然后使用socket的方法查询ip地址,如果查询出ip地址,证明这个子域名存在,下面有百度做个示例.
# 方式1: 利用字段爆破进行查询
import socket
import time
# 子域名查询
def subdomain_collect():print('[+] 正在收集子域名信息...') # 这个是我后面加的for sub in open('dic.txt', 'r'):sub = sub.replace('\n', '') # 将每个子域名后的换行符替换为空url = f'{sub}.baidu.com'try:ip = socket.gethostbyname(url)print(f'[+] {url} -> {ip}')time.sleep(0.5) # 避免因为查询过快而导致ip被封except Exception as e:passif __name__ == '__main__':subdomain_collect() 

1.5.2 Two
因为写批量收集的时候需要进行测试,所以根据上面的返回bing和百度的子域名的真实数据混合不存在的子域名制作一个小字典进行测试,因为本次代码,写出后没有出现任何问题,一次成功,所以也就没有最后的整合部分了.
当然在运行的结果中也可以发现,出现多个域名对应同一个ip,因为本来百度和bing都使用了cdn技术,所以说很正常,后面也需要将代码改进,或是写一个将子域名反查ip相同的子域名进行去重.
# 方式1: 利用字典爆破进行查询
import socket
import time
# 子域名查询
def subdomain_collect(domain):with open(f'sub_{domain}.txt', 'a+') as w:print(f'[+] 正在收集{domain}子域名的信息...')w.write(f'[+] 收集{domain}子域名的信息如下:\n')for sub in open('test.txt', 'r'):sub = sub.replace('\n', '') # 将每个子域名后的换行符替换为空url = f'{sub}.{domain}'try:ip = socket.gethostbyname(url)print(f'[+] {url} -> {ip}')w.write(f'[+] {url} -> {ip}\n')time.sleep(0.5)except Exception as e:passprint('\n')if __name__ == '__main__':for domain in open('domain.txt', 'r'):domain = domain.replace('\n', '') # 将每个取出的域名后的换行符替换为空subdomain_collect(domain)测试小字典
test.txt
a
ab
a2
abcd
abc
city
a1
cc
a3
josn
blog1
pmt
asd
cha
a4
version
okay
aa
ab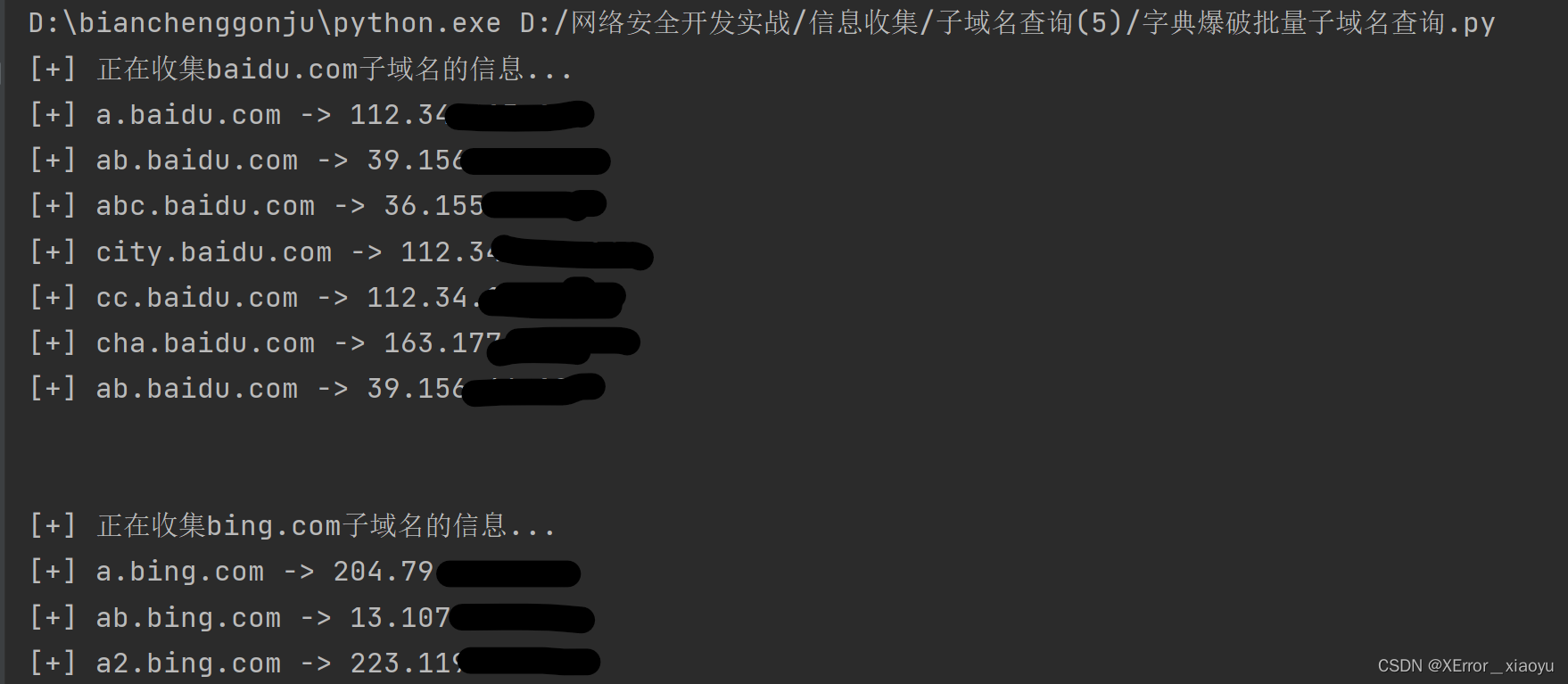 domain.txt
domain.txt
baidu.com
bing.com运行完代码后生成的两个子域名文件:
sub_baidu.com.txt
[+] 收集baidu.com子域名的信息如下:
[+] a.baidu.com -> 112.34.113.xxx
[+] ab.baidu.com -> 39.156.66.xxx
[+] abc.baidu.com -> 36.155.132.xxx
[+] city.baidu.com -> 112.34.111.xxx
[+] cc.baidu.com -> 112.34.111.xxx
[+] cha.baidu.com -> 163.177.17.xxx
[+] ab.baidu.com -> 39.156.66.xxxsub_bing.com.txt
[+] 收集bing.com子域名的信息如下:
[+] a.bing.com -> 204.79.197.xxx
[+] ab.bing.com -> 13.107.21.xxx
[+] a2.bing.com -> 223.119.248.xx
[+] abcd.bing.com -> 204.79.197.xxx
[+] abc.bing.com -> 13.107.21.xxx
[+] city.bing.com -> 13.107.21.xxx
[+] a1.bing.com -> 223.119.248.xx
[+] cc.bing.com -> 13.107.21.xxx
[+] a3.bing.com -> 223.119.248.xx
[+] josn.bing.com -> 204.79.197.xxx
[+] blog1.bing.com -> 13.107.21.xxx
[+] pmt.bing.com -> 13.107.21.xxx
[+] asd.bing.com -> 13.107.21.xxx
[+] cha.bing.com -> 204.79.197.xxx
[+] a4.bing.com -> 223.119.248.xxx
[+] version.bing.com -> 13.107.21.xxx
[+] okay.bing.com -> 13.107.21.xxx
[+] aa.bing.com -> 13.107.21.xxx
[+] ab.bing.com -> 13.107.21.xxx
方式2:其他方式
通过子域名查询或是子域名枚举工具
当然这种方式相信大家初学时都会使用通过将一些子域名查询网站,查询的子域名将其爬取下来,写到txt文本中火是csv中,使用常见工具进行枚举其实根本也是通过调用一些资产测绘平台的api或是工具自带的字典进行暴力枚举,根本上和我使用的这个基本上差不多,大家都在用,用烂了,很难搜集到别人搜集不到的资产,说到底,自己总结的别人没有的字典,才能发现新的大陆,这里我就不写了,大佬们写了很多工具和脚本调用资产测绘平台直接使用就可以了.
总结
本篇文章也是对上一篇的进一步利用吧,在对渗透过程中,还是需要对所属域名的所有者的信息进行一定的收集的,帮助我们制作对应的字典进行一些登录界面的爆破,当然在渗透过程中,主域名都是比较难啃的骨头,需要我们对子域名进行信息收集,然后进行进一步的利用.