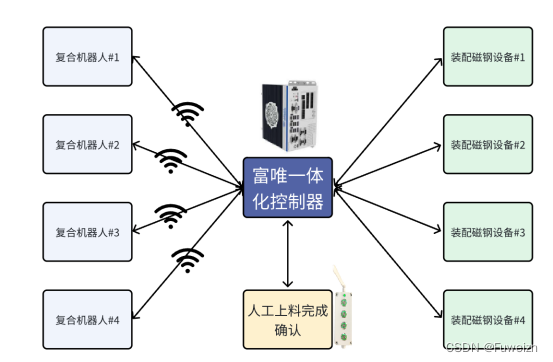
面试者经常会问transform这个模型,一个典型的seq2seq结构。
1 背景
试问几个问题,为什么提出了transform模型。RNN对于长时间序列(超过40)压缩到一个上下文向量中出现记忆退化现象,无法更好捕捉上下文信息。因此transform应运而生了。Transformer模型在2017年被google提出,直接基于Self-Attention结构,取代了之前NLP任务中常用的RNN神经网络结构,与RNN这类神经网络结构相比,Transformer一个巨大的优点是:**模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。
下面是模型的结构:
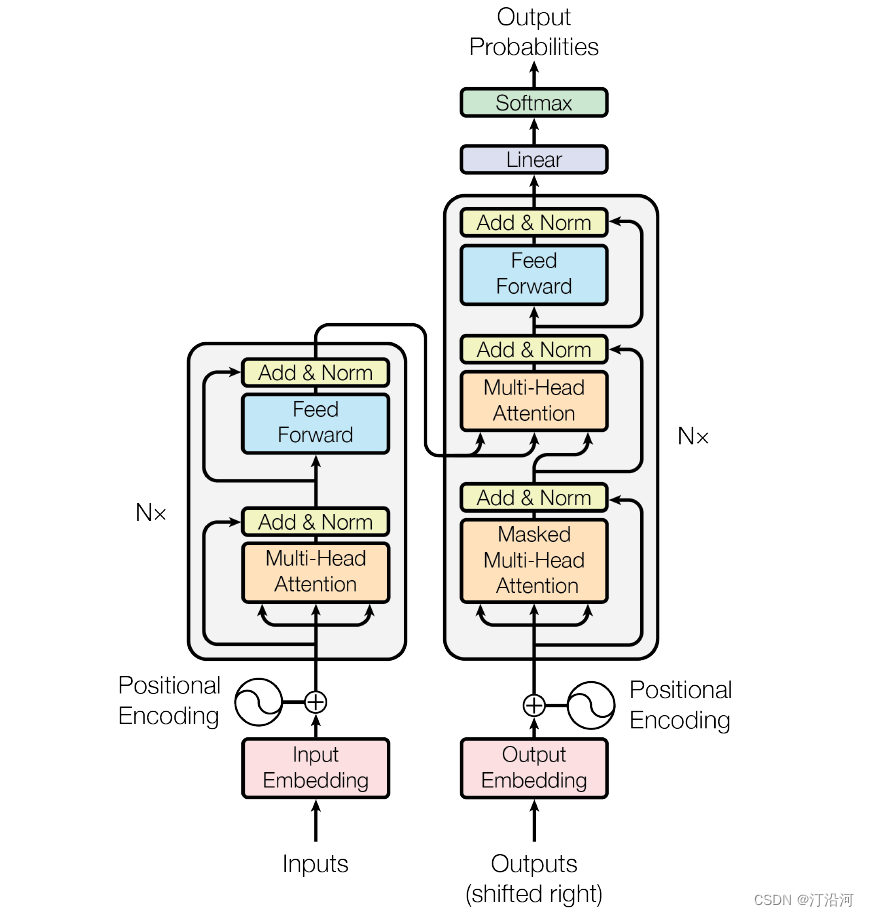
2 TransForm结构
了解了Transformer的宏观结构之后。下面,让我们来看看Transformer如何将输入文本序列转换为向量表示,又如何逐层处理这些向量表示得到最终的输出。
2.1 输入处理
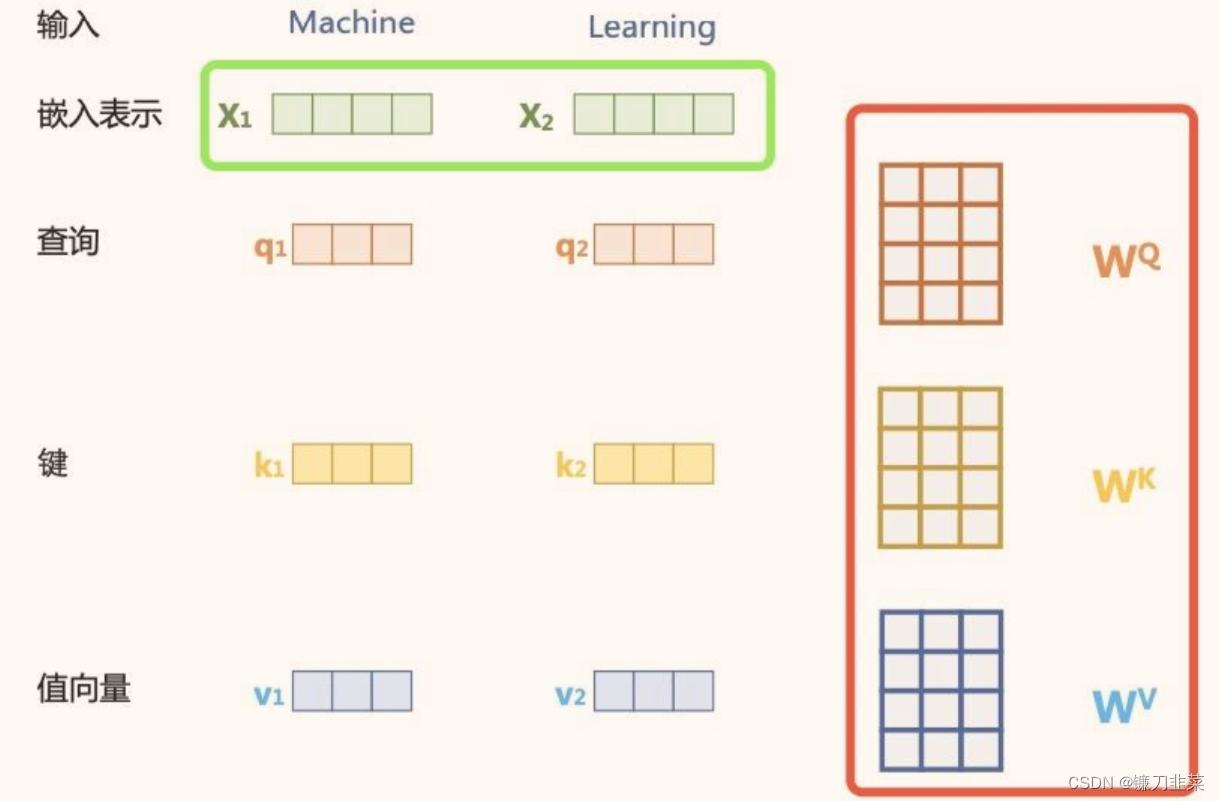
获取词向量: 和常见的NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。716后面会经常看到。
在实际应用中,我们通常会同时给模型输入多个句子,如果每个句子的长度不一样,我们会选择一个合适的长度,作为输入文本序列的最大长度:如果一个句子达不到这个长度,那么就填充先填充一个特殊的“padding”词;如果句子超出这个长度,则做截断。最大序列长度是一个超参数,通常希望越大越好,但是更长的序列往往会占用更大的训练显存/内存,因此需要在模型训练时候视情况进行决定。
2.2 Self-Attention层
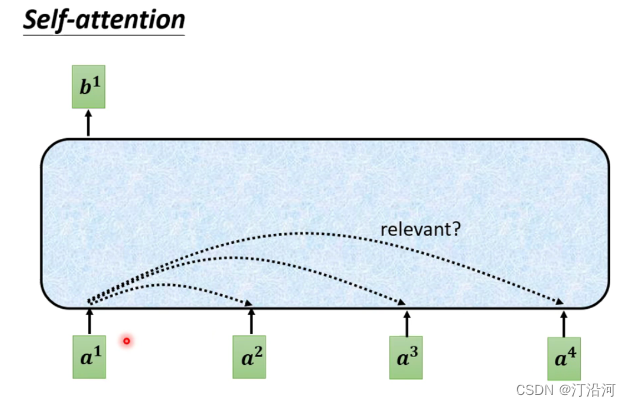
对于每一个输入向量a,经过蓝色部分self-attention之后都输出一个向量b,这个向量b是考虑了所有的输入向量对a1产生的影响才得到的,这里有四个词向量a对应就会输出四个向量b。

参数解释:
- 三个矩阵: W、Q、V是权重,要学习的。
- 你看三个矩阵乘以的都是向量a,这就是为什么叫Self-attenton;
- 本质上不就是一种映射关系,只不过经过一层Self-attenton之后的b,包含了更多的信息。
2.3 Layer Norm
ref: 为什么Transformer要用LayerNorm? - 知乎
这部分可能与batchNorm结合一起讲最好,我也被面试官问到。比如我们现在每一个样本有两个特征 身高x1,体重x2 。batchNorm是对所有样本x2放在一起然后进行归一化处理。而layerNorm是对一个样本的x1、x2放到一起进行归一化处理。
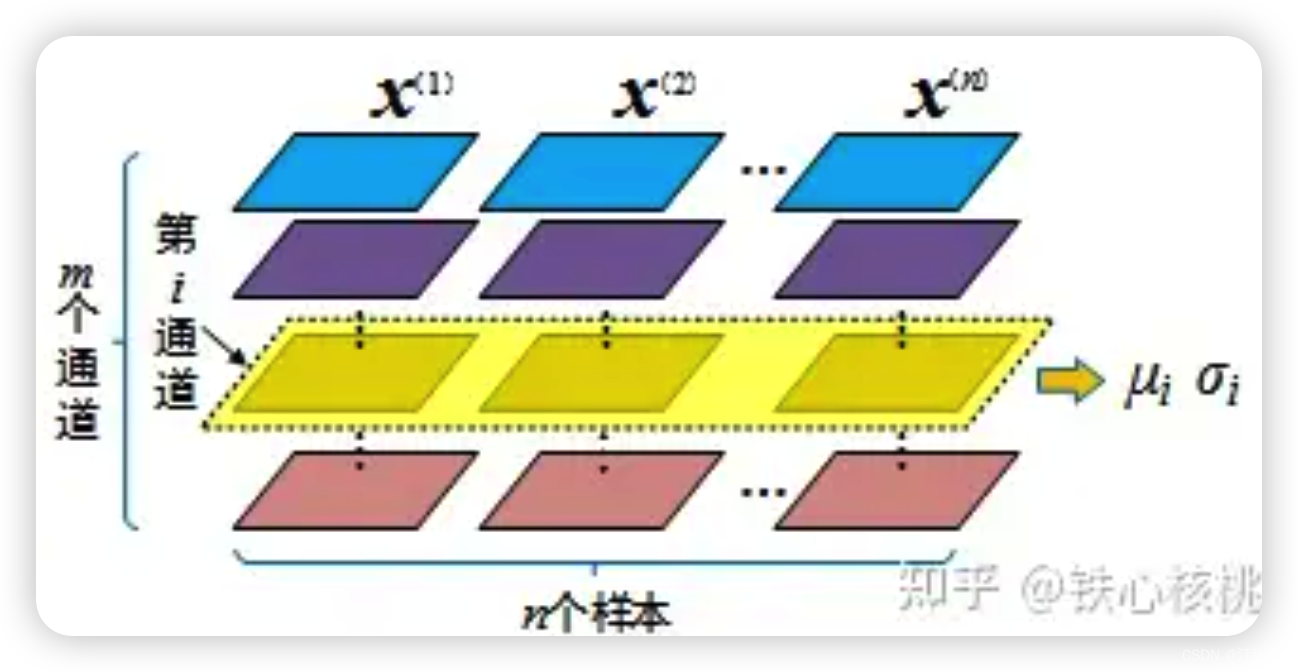
BatchNorm将不同样本相同维度的特征处理为相同的分布。其广泛使用在CV中,一个批次中样本是一个三通道(R、G、B)。有n个样本,每个样本有m个特征(通道),BatchNorm把所有样本通道进行归一会处理。针对同一个通道的特征跨越样本的方式进行归一化处理。
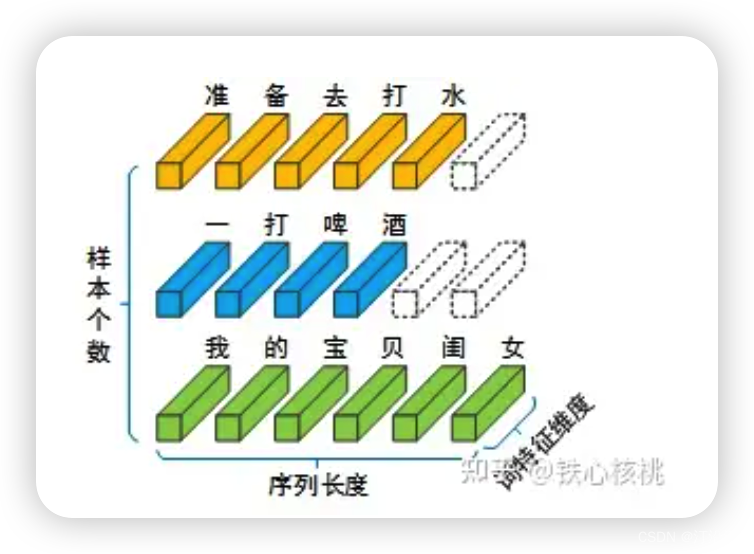
对于一个NLP模型,一个批次的输入包括若干个独立的句子,每个句子又由不定长度的词构成,句子中的每个词又被映射为固定长度的词向量。然后一个句子作为归一化的单位。(保留词与词之间的相对性)。
二者结果差异比较:

2.4 的意义
两个向量内积会随着维度的增加而变大,经过softmax之后防止进入饱和区,反向求导会有问题。
ref: https://github.com/datawhalechina/learn-nlp-with-transformers/blob/main/docs/%E7%AF%87%E7%AB%A02-Transformer%E7%9B%B8%E5%85%B3%E5%8E%9F%E7%90%86/2.2-%E5%9B%BE%E8%A7%A3transformer.md