1. 删除有序数组中的重复项
给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
- 更改数组
nums,使nums的前k个元素包含唯一元素,并按照它们最初在nums中出现的顺序排列。nums的其余元素与nums的大小不重要。 - 返回
k。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组
int[] expectedNums = [...]; // 长度正确的期望答案int k = removeDuplicates(nums); // 调用assert k == expectedNums.length;
for (int i = 0; i < k; i++) {assert nums[i] == expectedNums[i];
}
如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2] 输出:2, nums = [1,2,_] 解释:函数应该返回新的长度2,并且原数组 nums 的前两个元素被修改为1,2。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4] 输出:5, nums = [0,1,2,3,4] 解释:函数应该返回新的长度5, 并且原数组 nums 的前五个元素被修改为0,1,2,3,4。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 104-104 <= nums[i] <= 104nums已按 非严格递增 排列
双指针思路:
-
我们首先定义两个指针,一个快指针
fast和一个慢指针slow,初始值都为1。这是因为数组的第一个元素肯定是不重复的。 -
然后我们从数组的第二个元素开始,用快指针遍历整个数组。
-
在遍历的过程中,我们比较当前元素和前一个元素是否相同。如果当前元素与前一个元素不相同,则说明当前元素是一个新的不重复元素,我们就将它移动到慢指针的位置,并且慢指针向后移动一位。
-
最后,快指针继续向后移动,直到遍历完整个数组。慢指针所指向的位置即为去重后的数组的长度。
代码:
class Solution {
public:// 定义一个函数,用于移除已排序数组中的重复元素,并返回去重后的数组长度int removeDuplicates(vector<int>& nums) {// 获取数组长度int n = nums.size();// 如果数组为空,直接返回长度0if (n == 0) {return 0;}// 定义快指针和慢指针,初始位置均为1,因为第一个元素肯定是不重复的int fast = 1, slow = 1;// 从第二个元素开始遍历数组while (fast < n) {// 如果当前数字和前一个数字不相同if (nums[fast] != nums[fast - 1]) {// 将当前不重复的数字移动到慢指针的位置nums[slow] = nums[fast];// 慢指针向后移动++slow;}// 快指针始终向后移动++fast;}// 返回去重后的数组长度return slow;}
};2K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
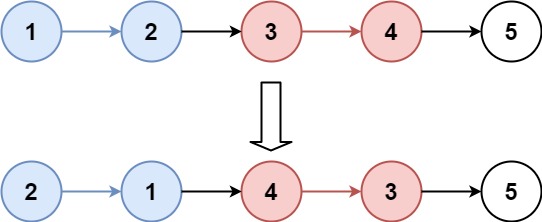
输入:head = [1,2,3,4,5], k = 2 输出:[2,1,4,3,5]
示例 2:
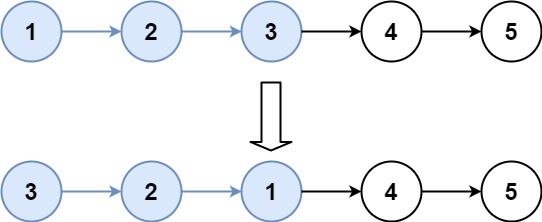
输入:head = [1,2,3,4,5], k = 3 输出:[3,2,1,4,5]
提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
思路:
-
切分链表为 K 个一组:首先,我们需要将给定的链表按照 K 个一组进行切分。这一步可以通过遍历链表,每次取出 K 个节点为一组,然后记录下一组的起始节点。
-
翻转每个子链表:对于每个切分出来的子链表,我们需要进行翻转操作。可以使用迭代或递归的方式实现链表的翻转。如果使用迭代,我们需要维护三个指针,分别指向当前节点、前一个节点和下一个节点,然后依次修改指针方向实现翻转。如果使用递归,我们可以递归地将子链表翻转,直到到达子链表的末尾再开始向前翻转。
-
连接翻转后的子链表:将翻转后的每个子链表连接起来,形成最终的翻转后的链表。需要注意连接的时候要保持原有的顺序。
-
处理剩余不足 K 个节点的部分:如果链表长度不是 K 的倍数,最后一组可能不足 K 个节点。在处理完前面的 K 个节点后,剩余的不足 K 个节点不需要翻转,直接连接到最终的链表中。
-
返回结果:返回翻转后的链表头节点。
代码:
class Solution {
public:// 定义一个函数,用于每 k 个节点一组进行反转,并返回反转后的头节点ListNode* reverseKGroup(ListNode* head, int k) {// 如果 k 小于等于 1,直接返回头节点if (k <= 1)return head;// 定义两个指针,一个用于遍历节点,一个用于标记每 k 个节点的起始位置ListNode* node = head;ListNode* change = head;// 循环遍历链表while (true) {// 用于存储每 k 个节点的值vector<int> nums;int i;// 遍历 k 个节点,将节点的值存储到 nums 中for (i = 0; i < k; i++) {nums.push_back(node->val);// 如果还有下一个节点,继续遍历下一个节点,否则跳出循环if (node->next != NULL) {node = node->next;} elsebreak;}// 如果遍历的节点数不等于 k,并且不等于 k-1(说明剩余节点数不足 k 个),则跳出循环if (i != k && i != k - 1)break;// 将 nums 中的值倒序赋值给每 k 个节点for (int j = 0; j < k; j++) {change->val = nums[nums.size() - 1];nums.pop_back();change = change->next;}}// 返回头节点return head;}
};3树节点
表:Tree
+-------------+------+ | Column Name | Type | +-------------+------+ | id | int | | p_id | int | +-------------+------+ id 是该表中具有唯一值的列。 该表的每行包含树中节点的 id 及其父节点的 id 信息。 给定的结构总是一个有效的树。
树中的每个节点可以是以下三种类型之一:
- "Leaf":节点是叶子节点。
- "Root":节点是树的根节点。
- "lnner":节点既不是叶子节点也不是根节点。
编写一个解决方案来报告树中每个节点的类型。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
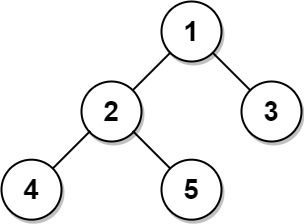
输入: Tree table: +----+------+ | id | p_id | +----+------+ | 1 | null | | 2 | 1 | | 3 | 1 | | 4 | 2 | | 5 | 2 | +----+------+ 输出: +----+-------+ | id | type | +----+-------+ | 1 | Root | | 2 | Inner | | 3 | Leaf | | 4 | Leaf | | 5 | Leaf | +----+-------+ 解释: 节点 1 是根节点,因为它的父节点为空,并且它有子节点 2 和 3。 节点 2 是一个内部节点,因为它有父节点 1 和子节点 4 和 5。 节点 3、4 和 5 是叶子节点,因为它们有父节点而没有子节点。
示例 2:

输入: Tree table: +----+------+ | id | p_id | +----+------+ | 1 | null | +----+------+ 输出: +----+-------+ | id | type | +----+-------+ | 1 | Root | +----+-------+ 解释:如果树中只有一个节点,则只需要输出其根属性。
思路:
- 使用别名
atree来引用表tree,这样在查询中可以更方便地引用表。 - 对于每个节点,首先检查其父节点的 ID 是否为空(即是否为根节点),如果为空,则将该节点标记为
'Root'。 - 如果父节点的 ID 不为空,则进一步检查该节点是否在子节点列表中。如果在子节点列表中,则将该节点标记为
'Inner',否则标记为'Leaf'。 - 最后按照节点的 ID 进行排序,以确保结果按照树的结构顺序显示。
代码:
-- 选择树的 ID 和节点类型
select atree.id,-- 如果父 ID 为空,则为根节点;如果在子节点列表中,则为内部节点;否则为叶子节点IF(ISNULL(atree.p_id),'Root',IF(atree.id IN (select p_id from tree), 'Inner','Leaf')) Type
from -- 使用别名 atree 来引用树表tree atree
order by atree.id; -- 按照树的 ID 进行排序4判断三角形
表: Triangle
+-------------+------+ | Column Name | Type | +-------------+------+ | x | int | | y | int | | z | int | +-------------+------+ 在 SQL 中,(x, y, z)是该表的主键列。 该表的每一行包含三个线段的长度。
对每三个线段报告它们是否可以形成一个三角形。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入: Triangle 表: +----+----+----+ | x | y | z | +----+----+----+ | 13 | 15 | 30 | | 10 | 20 | 15 | +----+----+----+ 输出: +----+----+----+----------+ | x | y | z | triangle | +----+----+----+----------+ | 13 | 15 | 30 | No | | 10 | 20 | 15 | Yes | +----+----+----+----------+
代码:
-- 选择 x、y、z 三个列,并添加一个新的列来判断是否为三角形
select x, y, z,casewhen x + y > z and x + z > y and y + z > x then 'Yes' -- 如果满足三角形的条件,则输出 Yeselse 'No' -- 否则输出 Noend as "triangle" -- 新列名为 triangle
from Triangle; -- 数据来源表为 Triangle5只出现一次的最大数字
MyNumbers 表:
+-------------+------+ | Column Name | Type | +-------------+------+ | num | int | +-------------+------+ 该表可能包含重复项(换句话说,在SQL中,该表没有主键)。 这张表的每一行都含有一个整数。
单一数字 是在 MyNumbers 表中只出现一次的数字。
找出最大的 单一数字 。如果不存在 单一数字 ,则返回 null 。
查询结果如下例所示。
示例 1:
输入: MyNumbers 表: +-----+ | num | +-----+ | 8 | | 8 | | 3 | | 3 | | 1 | | 4 | | 5 | | 6 | +-----+ 输出: +-----+ | num | +-----+ | 6 | +-----+ 解释:单一数字有 1、4、5 和 6 。 6 是最大的单一数字,返回 6 。
示例 2:
输入: MyNumbers table: +-----+ | num | +-----+ | 8 | | 8 | | 7 | | 7 | | 3 | | 3 | | 3 | +-----+ 输出: +------+ | num | +------+ | null | +------+ 解释:输入的表中不存在单一数字,所以返回 null 。
思路:
子查询:首先,内部的子查询从 MyNumbers 表中选择出现一次的数字。这是通过 GROUP BY 和 HAVING 子句完成的。group by num 将相同的数字分组,然后 having count(num) = 1 保证了我们只获取出现一次的数字。
外部查询:外部查询则使用 max() 函数从子查询的结果中选取最大值。
代码:
-- 从 MyNumbers 表中选择仅出现一次的数字,并从中找出最大值
selectmax(s.num) as num -- 选择唯一出现一次的数字中的最大值,并命名为 num
from(selectnum -- 选择数字列fromMyNumbers -- 数据来源表为 MyNumbersgroup bynum -- 按数字进行分组havingcount(num) = 1 -- 仅保留出现一次的数字) as s; -- s 为仅出现一次的数字组成的子查询结果集